从零开始的 Vulkan(六):同步与渲染循环
同步依赖
对于资源读写的同步一直是包括Vulkan在内的现代图形学API的重要议题,而在Vulkan中,隐式执行的同步操作非常有限,大部分的同步操作是交由用户手动操作,因此对于同步粒度的要求也上了一个台阶,在本节中,我将依据VkSpec上的描述详细探讨Vulkan中同步的细节。
执行依赖和内存依赖
Vulkan的许多同步是以操作集(Operation set) 为单位进行的,两个操作集之间的同步确保了第一个操作集的完成执行在第二个操作集的初始化之前,而为了实现这种操作集之间的同步,就需要定义不同的同步范围(Operation Scopes)。VkSpec向我们解释了同步操作大概的执行模式:
- 让Ops1(一号操作)和Ops2(二号操作)位于不同的操作集中。
- 定义一个Sync(同步)命令。
- 让Scope1st(一号范围)和Scope2st(二号范围)成为Sync的同步范围。
- ScopedOps1(一号范围中操作)是Ops1和Scope1st的交集。
- ScopedOps2(二号范围中操作)是Ops2和Scope2st的交集。
- 依次提交Ops1,Sync,Ops2到执行队列中,这会导致在ScopedOps1和ScopedOps2中出现一个ExeDep(执行依赖)。
- ExeDep保证了ScopedOps1完全在ScopedOps2之前执行。
执行依赖链(Execution dependency chain) 是一个由多个执行依赖组成的序列,它会为第一个依赖的ScopedOps1和最后一个依赖的ScopedOps2在执行之前规定对应的关系。对于每一对连续的执行依赖,假如第一个依赖和Scope2st的交集以及第二个依赖和Scope1st的交集并非空集,那么执行依赖链就会形成。每一个执行依赖在执行依赖链中的形成都能用以下方式来描述:
- 让Sync成为一组会生成执行依赖链的同步命令。
- 让Scope1st成为Sync的第一个命令的的第一个同步范围。
- 让Scope2st成为Sync的最后一个命令的的第二个同步范围。
但是仅仅使用执行依赖是无法有效确保在一个操作集中写入的值可以在另一个操作集中被访问,因此我们需要内存依赖(Memory dependency) 作为调控内存读写的同步方法。
可以使用另外三种操作来控制内存访问,分别是可用性操作(Availability operations),内存域操作(Memory domain operations) 和可见性操作(Visibility operations)。可用性操作会导致特定的内存写入数据将允许被一个内存域访问(任何可用的数据将保持可用直至相同的内存地址再次被写入或内存被释放);内存域操作会导致对于源内存域可用的写入将变得对于目标内存域可用;可见性操作和可用性操作相反,会导致对于内存域可用的数据可见于特定内存访问操作。大部分Vulkan同步命令都指明了内存依赖。
一个内存依赖就是包含了可用性和可见性操作的执行依赖,如下所示:
- 前一个操作集发生在可用性操作之前。
- 可用性操作发生在可见性操作之前。
- 可见性操作发生在后一个操作集之前。
同样的,我们也可以也引入一个访问范围(Access Scope) 来规定内存访问是如何变得可用和可见的。所有在内存依赖的第一个访问范围并且发生在ScopedOps1中的访问会变为可用状态;所有在内存依赖的第二个访问范围并且发生在ScopedOps2中的访问会对任何可用的写入可见。任何不在访问范围的操作不会被包含在产生的依赖中。
内存依赖在两组操作之间强制规定内存访问和执行顺序的可用性和可见性,把它添加进执行依赖链后,就可以得到下面这样的顺序:
- 让MemOps1(一号内存操作)成为ScopedOps1实施的内存访问操作集。
- 让MemOps2(二号内存操作)成为ScopedOps2实施的内存访问操作集。
- 让AccessScope1st(一号访问范围)成为Sync链的中的第一个命令的第一个访问范围。
- 让AccessScope2st(二号访问范围)成为Sync链的中的最后一个命令的第二个访问范围。
- ScopedMemOps1 (一号范围中内存操作)是MemOps1和AccessScope1st的交集。
- ScopedMemOps2 (二号范围中内存操作)是MemOps2和AccessScope2st的交集。
- 依次提交Ops1,Sync,Ops2到执行队列中,这会导致在ScopedOps1和ScopedOps2中出现一个MemDep(内存依赖)。
执行依赖和内存依赖是用来解决数据的错误访问所造成的危险。读操作后的写操作带来的危险可以单纯用执行依赖进行解决,但写操作后的读操作或写操作后的写操作带来的危险需要合适的内存依赖进行解决,如过应用程序不指定依赖来解决这些危险,那么谁也不知道会造成什么后果。
图像布局转换
作为内存依赖的一部分,图像可以从一个布局转换至另一个布局(为了优化读写),被称作图像布局转换(Image Layout Transitions),它发生在内存依赖中的可用性操作之后,可见性操作之前。对于必要的图像子资源,图像布局转换可能会在执行内存的读写操作,因此,在执行图像布局转换之前,应用程序必须保证所有的内存写入是可用的(而可用的内存对于布局转换来说也是可见的)。
在执行图像布局转换时,我们需要指定旧布局(oldLayout)和新布局(newLayout),指定的旧布局可以是未定义的(VK_IMAGE_LAYOUT_UNDEFINED)或图像原本的布局,但指定未定义的旧布局将会使图像面临数据丢失的风险。很明显,所有使用旧图像布局的操作必须发生在图像布局转换之前,所有使用新图像布局的操作必须发生在图像布局转换之后。
相对于提交到同一队列的其他图像布局转换(包括由渲染通道执行的那些),通过图像内存屏障执行的布局转换以提交顺序完整执行。实际上,从每个布局转换到之前提交到同一队列的所有布局转换都存在一个隐式执行依赖关系。
管线阶段
由设备上的命令(action or synchronization command)所分派的工作包含多个操作步骤,这些操作步骤按照互相独立的序列执行,被称为管线阶段(Pipeline stages)。具体的管线阶段会在录制命令时得到指定(或由命令缓冲区所处的阶段指定),包括绘制命令,分派命令,复制命令,清除命令,同步命令在内的多数命令都需要在特定管线阶段的操作集中执行,但是同步命令并非在Vulkan所给定的管线阶段中执行。
跨管线阶段的操作必须遵循严格的顺序,这个顺序由管线阶段顺序(Pipeline stage order) 指定,由Vulkan内部定义。否则,这些操作会在不同的管线阶段造成混淆,除非受到执行依赖的强制同步。
虽然同步命令并非在给定的管线阶段中执行,但是可以将同步命令的同步范围指定为管线阶段的一部分,从而给不同管线阶段的操作添加必要的内存依赖。
Vulkan1.3(不含扩展)所拥有的管线阶段如下所示:
| VkPipelineStageFlagBits2 | 含义 |
|---|---|
| VK_PIPELINE_STAGE_2_NONE | 未指定阶段 |
| VK_PIPELINE_STAGE_2_DRAW_INDIRECT_BIT | 间接绘制命令执行 |
| VK_PIPELINE_STAGE_2_INDEX_INPUT_BIT | 索引缓冲被使用 |
| VK_PIPELINE_STAGE_2_VERTEX_ATTRIBUTE_INPUT_BIT | 顶点缓冲被使用 |
| VK_PIPELINE_STAGE_2_VERTEX_INPUT_BIT | 包含前两个阶段 |
| VK_PIPELINE_STAGE_2_VERTEX_SHADER_BIT | 顶点着色器 |
| VK_PIPELINE_STAGE_2_TESSELLATION_CONTROL_SHADER_BIT | 细分控制着色器(外壳着色器) |
| VK_PIPELINE_STAGE_2_TESSELLATION_EVALUATION_SHADER_BIT | 细分评估着色器(域着色器) |
| VK_PIPELINE_STAGE_2_GEOMETRY_SHADER_BIT | 几何着色器 |
| VK_PIPELINE_STAGE_2_PRE_RASTERIZATION_SHADERS_BIT | 预光栅化(包含前四个阶段) |
| VK_PIPELINE_STAGE_2_FRAGMENT_SHADER_BIT | 片元着色器(像素着色器) |
| VK_PIPELINE_STAGE_2_EARLY_FRAGMENT_TESTS_BIT | 早期片元测试 |
| VK_PIPELINE_STAGE_2_LATE_FRAGMENT_TESTS_BIT | 晚期片元测试 |
| VK_PIPELINE_STAGE_2_COLOR_ATTACHMENT_OUTPUT_BIT | 颜色附件输出 |
| VK_PIPELINE_STAGE_2_COMPUTE_SHADER_BIT | 计算着色器 |
| VK_PIPELINE_STAGE_2_HOST_BIT | 主机对设备内存的读写 |
| VK_PIPELINE_STAGE_2_COPY_BIT | 复制命令执行 |
| VK_PIPELINE_STAGE_2_BLIT_BIT | vkCmdBlitImage执行 |
| VK_PIPELINE_STAGE_2_RESOLVE_BIT | vkCmdResolveImage执行 |
| VK_PIPELINE_STAGE_2_CLEAR_BIT | vkCmdClearAttachments以外的清除命令执行 |
| VK_PIPELINE_STAGE_2_ALL_TRANSFER_BIT | 包含前四个阶段和VK_PIPELINE_STAGE_2_ACCELERATION_STRUCTURE_COPY_BIT_KHR扩展阶段 |
| VK_PIPELINE_STAGE_2_ALL_GRAPHICS_BIT | 包含从VK_PIPELINE_STAGE_2_DRAW_INDIRECT_BIT到VK_PIPELINE_STAGE_2_COLOR_ATTACHMENT_OUTPUT_BIT的所有阶段 |
| VK_PIPELINE_STAGE_2_ALL_COMMANDS_BIT | 包含所有命令执行阶段 |
| VK_PIPELINE_STAGE_2_TOP_OF_PIPE_BIT | 等同于VK_PIPELINE_STAGE_2_ALL_COMMANDS_BIT把第二个同步范围的VkAccessFlags2设为0;作为第一个同步范围,等同于VK_PIPELINE_STAGE_2_NONE |
| VK_PIPELINE_STAGE_2_BOTTOM_OF_PIPE_BIT | 等同于VK_PIPELINE_STAGE_2_ALL_COMMANDS_BIT把第一个同步范围的VkAccessFlags2设为0;作为第二个同步范围,等同于VK_PIPELINE_STAGE_2_NONE |
TOP_OF_PIPE和BOTTOM_OF_PIPE几乎被弃用了,应用程序应该优先使用ALL_COMMANDS和NONE
访问类型(Access Type)
Vulkan中的设备内存可以被着色器调用或经由一些固定功能的管线阶段访问,而访问类型就规定了设备内存被访问的方式。多数同步命令会将访问类型作为定义内存依赖的访问范围的参数,如果一个同步命令包含了源访问掩码(Source access mask),那么它的第一个访问范围只会包括掩码中所指定的访问操作类型;同样的,如果一个同步命令包含了目标访问掩码(Destination access mask),那么它的第二个访问范围只会包括掩码中所指定的访问操作类型。
Vulkan1.3(不含扩展)所拥有的访问类型如下所示:
| VkAccessFlagBits2 | 含义 |
|---|---|
| VK_ACCESS_2_NONE | 未指定类型 |
| VK_ACCESS_2_MEMORY_READ_BIT | 所有内存读操作 |
| VK_ACCESS_2_MEMORY_WRITE_BIT | 所有内存写操作 |
| VK_ACCESS_2_INDIRECT_COMMAND_READ_BIT | 发生在VK_PIPELINE_STAGE_2_DRAW_INDIRECT_BIT阶段的间接命令读操作 |
| VK_ACCESS_2_INDEX_READ_BIT | 发生在VK_PIPELINE_STAGE_2_INDEX_INPUT_BIT阶段的索引缓冲读操作 |
| VK_ACCESS_2_VERTEX_ATTRIBUTE_READ_BIT | 发生在VK_PIPELINE_STAGE_2_VERTEX_ATTRIBUTE_INPUT_BIT阶段的顶点缓冲读操作 |
| VK_ACCESS_2_UNIFORM_READ_BIT | 着色器对Uniform buffer的读操作 |
| VK_ACCESS_2_INPUT_ATTACHMENT_READ_BIT | 发生在VK_PIPELINE_STAGE_2_FRAGMENT_SHADER_BIT阶段的片元着色器对Input attachment的读操作 |
| VK_ACCESS_2_SHADER_SAMPLED_READ_BIT | 着色器对Uniform texel buffer和Sampled image的读操作 |
| VK_ACCESS_2_SHADER_STORAGE_READ_BIT | 着色器对Storage buffer,Physical storage buffer,Storage texel buffer或Storage image的读操作 |
| VK_ACCESS_2_SHADER_READ_BIT | VK_ACCESS_2_UNIFORM_READ_BIT,VK_ACCESS_2_SHADER_SAMPLED_READ_BIT,VK_ACCESS_2_SHADER_STORAGE_READ_BIT和VK_ACCESS_2_SHADER_BINDING_TABLE_READ_BIT_KHR的总和 |
| VK_ACCESS_2_SHADER_STORAGE_WRITE_BIT | 着色器对Storage buffer,Physical storage buffer,Storage texel buffer或Storage image的写操作 |
| VK_ACCESS_2_SHADER_WRITE_BIT | 等同于VK_ACCESS_2_SHADER_STORAGE_WRITE_BIT |
| VK_ACCESS_2_COLOR_ATTACHMENT_READ_BIT | 发生在VK_PIPELINE_STAGE_2_COLOR_ATTACHMENT_OUTPUT_BIT阶段对颜色附件的读操作 |
| VK_ACCESS_2_COLOR_ATTACHMENT_WRITE_BIT | 发生在VK_PIPELINE_STAGE_2_COLOR_ATTACHMENT_OUTPUT_BIT阶段对颜色附件的写操作 |
| VK_ACCESS_2_DEPTH_STENCIL_ATTACHMENT_READ_BIT | 发生在VK_PIPELINE_STAGE_2_EARLY_FRAGMENT_TESTS_BIT或VK_PIPELINE_STAGE_2_LATE_FRAGMENT_TESTS_BIT阶段对深度模板附件的读操作 |
| VK_ACCESS_2_DEPTH_STENCIL_ATTACHMENT_WRITE_BIT | 发生在VK_PIPELINE_STAGE_2_EARLY_FRAGMENT_TESTS_BIT或VK_PIPELINE_STAGE_2_LATE_FRAGMENT_TESTS_BIT阶段对深度模板附件的写操作 |
| VK_ACCESS_2_TRANSFER_READ_BIT | 发生在VK_PIPELINE_STAGE_2_COPY_BIT,VK_PIPELINE_STAGE_2_BLIT_BIT或VK_PIPELINE_STAGE_2_RESOLVE_BIT阶段在复制操作中对缓冲或图像的读操作 |
| VK_ACCESS_2_TRANSFER_WRITE_BIT | 发生在VK_PIPELINE_STAGE_2_COPY_BIT,VK_PIPELINE_STAGE_2_BLIT_BIT或VK_PIPELINE_STAGE_2_RESOLVE_BIT阶段在复制操作中对缓冲或图像的写操作 |
| VK_ACCESS_2_HOST_READ_BIT | 主机对资源的读操作 |
| VK_ACCESS_2_HOST_WRITE_BIT | 主机对资源的写操作 |
| VK_PIPELINE_STAGE_2_ALL_GRAPHICS_BIT | 包含从VK_PIPELINE_STAGE_2_DRAW_INDIRECT_BIT到VK_PIPELINE_STAGE_2_COLOR_ATTACHMENT_OUTPUT_BIT的所有阶段 |
| VK_PIPELINE_STAGE_2_ALL_COMMANDS_BIT | 包含所有命令执行阶段 |
| VK_PIPELINE_STAGE_2_TOP_OF_PIPE_BIT | 等同于VK_PIPELINE_STAGE_2_ALL_COMMANDS_BIT把第二个同步范围的VkAccessFlags2设为0;作为第一个同步范围,等同于VK_PIPELINE_STAGE_2_NONE |
| VK_PIPELINE_STAGE_2_BOTTOM_OF_PIPE_BIT | 等同于VK_PIPELINE_STAGE_2_ALL_COMMANDS_BIT把第一个同步范围的VkAccessFlags2设为0;作为第二个同步范围,等同于VK_PIPELINE_STAGE_2_NONE |
依赖选项
对于FRAGMENT_SHADE,VK_PIPELINE_STAGE_EARLY_FRAGMENT_TESTS,LATE_FRAGMENT_TESTS和COLOR_ATTACHMENT_OUTPUT这几个管线阶段而言,其中的依赖可以应用于帧缓冲整体(Framebuffer-global),也可以将帧缓冲分割成多个子集单独生效(Framebuffer-local),为dependencyFlags指定VK_DEPENDENCY_BY_REGION_BIT从而使用Framebuffer-local依赖,对于大多数架构这会更加高效。
对于一个开启了多视图(Mutiview)的RenderPass,依赖可以只包含来自单一源视图(Source view)和单一目标视图(Destination view)的操作,这被称为View-local dependency;同样的,依赖也可以包含来自源子通道和目标子通道的所有视图掩码中指定的视图,这被称为View-global dependency,为dependencyFlags指定VK_DEPENDENCY_VIEW_LOCAL_BIT从而使用View-local dependency。
依赖可以被指定为Device-local或Non-device-local。对于Device-local dependency,依赖会被拆分并为每个物理设备的操作单独应用;对于Non-device-local dependency,依赖会为所有参与的物理设备的操作共同应用。参与的物理设备由VkDeviceGroupRenderPassBeginInfo::deviceMask和命令缓冲区所指定的设备掩码决定。为dependencyFlags指定VK_DEPENDENCY_DEVICE_GROUP_BIT从而使用Non-device-local dependency。
Semaphore和Event依赖是Device-local的并且只会在一个指定的物理设备上生效。
同步原语
Vulkan为我们提供了同步原语来实现手动同步,而这些同步原语大部分时候需要搭配起来使用,下面是一些简单介绍:
Fences(栅栏):
Fences可以和主机(CPU和内存)进行交流并得知设备(GPU和显存)完成某些任务执行的信息,用于在队列和主机之间插入一个依赖。
Semaphores(信号量):
Semaphores可以用于在多个执行队列之间控制资源的读写许可,用于在队列操作之间或在队列操作和主机之间插入依赖。
Events(事件):
Events提供了一种细粒度的同步方式,它可以被命令缓冲区或主机标记,并在命令缓冲区和队列内部完成等待的任务。
Pipeline Barriers(管线屏障):
PipelineBarriers也提供了命令缓冲区内部的同步方式,但是是被单独使用的,而非像Events那样由分开的标记和等待操作。
Render Passes(渲染通道):
RenderPasses为大多数渲染任务提供了一个重要的同步框架,我们在上一节讲解渲染通道时已经了解过了它的具体用法,大部分情况下需要将其它的同步原语高效地结合在RenderPasses中。
Fences
Fence拥有两个状态,分别是signaled(有信号)和unsignaled(无信号),它可以作为队列的一部分在提交时被标记为signaled,也可以在主机上使用vkResetFences方法重置为unsignaled。在主机上使用vkWaitForFences方法来等待Fences,使用vkGetFence方法来获取Fence的当前状态。下面演示了Fences的基本使用方式:
创建Fence:
1 | auto fenceInfo = vk::FenceCreateInfo(); |
为队列提交绑定Fence:
1 | vkInfo.queue.submit(1, &submitInfo, vkInfo.fence); |
在主机端等待Fence变为signaled:
1 | vk::Result waitingRes; |
在vkWaitForFences的参数列表中,waitAll指定了结束等待需要满足的条件,若为VK_TRUE则所有指定的Fences都必须为signaled才会结束等待,否则只要有一个Fences满足条件就结束等待;timeout指定了超时时间(以纳秒为单位)超时调整为最接近的值取决于实现的超时精度允许,这可能会更长超过一纳秒,并且可能比请求的时间长。
当vkWaitForFences执行时,若未满足结束等待的条件,那么就会在主机端进行阻塞并强制等待直到超过timeout时间。若满足条件,则该函数会返回VK_SUCCESS,若超时,则会返回VK_TIMEOUT,这里我使用while循环来保证超时后也会继续等待直到满足条件。
Semaphores
Binary semaphores(二进制信号量)拥有两个状态(signaled和unsignaled),而Timeline semaphores(时间线信号量)拥有严格递增的64位无符号整数有效载荷,并针对特定的参考值发出信号。一个Semaphore可以在队列操作的执行完成后被标记信号,同样的,队列操作也可等待Semaphore被标记信号,而Timeline semaphores可以额外地被主机使用vkSignalSemaphore命令来标记信号,也可以使用vkWaitSemaphores命令来等待信号。下面演示了Binary semaphores的基本使用方式:
创建Semaphore:
1 | auto semaphoreInfo = vk::SemaphoreCreateInfo(); |
在Vulkan1.2后,可以为pNext指定VkSemaphoreTypeCreateInfo来指明创建的是Binary semaphores抑或是Timeline semaphores并为Timeline semaphores设定初始值,默认为Binary semaphores。
为队列操作指定要标记信号的Semaphore(以提交队列为例):
1 | auto submitInfo = vk::SubmitInfo() |
为队列操作指定要等待信号的Semaphore(以切换交换链图像为例):
1 | vkInfo.device.acquireNextImageKHR(vkInfo.swapchain, UINT64_MAX, vkInfo.imageAcquiredSemaphore, vk::Fence(), ¤tBuffer); |
Events
Events拥有两种状态(signaled和unsignaled),应用程序在主机和设备端都可以改变Events的状态,但只有设备端可以等待Events的信号,以此来阻塞之后的命令的执行,主机端只可以查询Events状态。下面演示了Events的基本用法:
创建Event:
1 | vk::Event events; |
在Vulkan1.3后可以为flags指定VK_EVENT_CREATE_DEVICE_ONLY_BIT来指定该event不会受到主机命令的调用。
在主机端改变Event的状态:
1 | vkInfo.device.setEvent(events); //设为signaled |
在设备端改变Event的状态:
1 | cmd.setEvent(events, vk::PipelineStageFlagBits::eAllCommands); |
在设备端改变Event的状态(Vulkan1.3):
1 | auto depInfo = vk::DependencyInfo(); |
DependencyInfo指定了当setEvent命令被提交至队列时,需要的内存依赖的第一个范围,也就是在setEvent命令执行之前所需要完成的内存依赖。
在设备端等待Event(Vulkan1.3):
1 | auto depInfo = vk::DependencyInfo(); |
Pipeline Barriers
管线屏障允许我们在命令缓冲区中主动插入依赖,下面演示了管线屏障的基本用法:
命令缓冲区调用管线屏障(该用法已在第三节里演示过):
1 | auto barrier = vk::ImageMemoryBarrier() |
命令缓冲区调用管线屏障(Vulkan1.3)(需要开启synchronization2 feature):
1 | auto barrier2 = vk::ImageMemoryBarrier2() |
相当于将pipelineBarrier的参数移进了DependencyInfo,实际上和初版并没有什么区别,不过我使用pipelineBarrier2一直报错,原因未知。
管线屏障和RenderPass的一些注意事项:
管线屏障无法在动态渲染内部调用。
当管线屏障在RenderPass内部调用时,image必须作为该Subpass的InputAttachment和颜色/深度/模板附件;Buffer memory barriers不允许被使用;图像的oldLayout和newLayout必须相同;srcQueueFamilyIndex和dstQueueFamilyIndex必须相同。
当管线屏障在RenderPass外部调用时,flags不允许VK_DEPENDENCY_VIEW_LOCAL_BIT。
渲染循环
当我们做完了所有的准备工作后,就可以正式将渲染程序的整个渲染循环完全写出来,让它不断进行绘制工作了。我们使用Win32 API来创建一个计时器,控制程序大致以60帧的速度循环执行,然后将绘制相关工作放在消息循环中:
1 | HANDLE phWait = CreateWaitableTimer(NULL, FALSE, NULL); |
一个完整的渲染循环的逻辑大致如下所示:
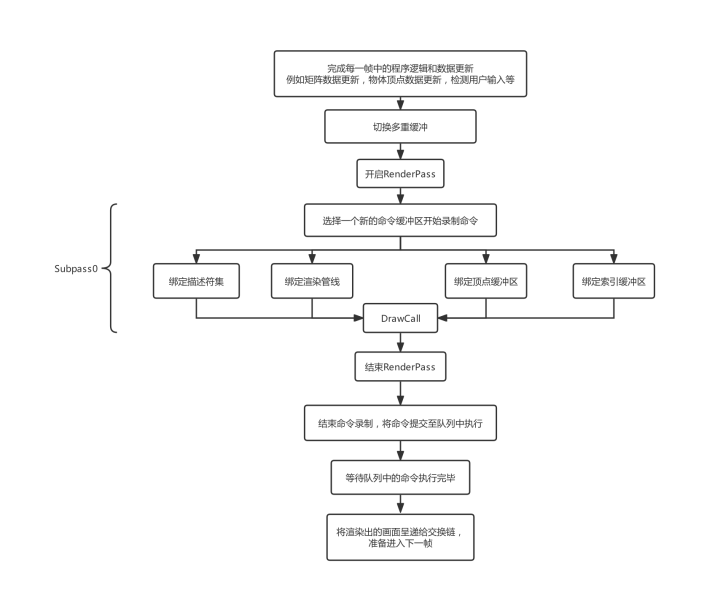
在本程序中,我使用双重缓冲并为每一个缓冲都配备了一个命令缓冲区,所以在渲染循环的最开始,我们需要切换至对应的帧缓冲和命令缓冲区:
1 | uint32_t currentBuffer; |
vkAcquireNextImageKHR函数通知了交换链自行切换至下一个要渲染的图像,并会返回当前的图像索引,而timeout参数指定了当没有可用的图像时该函数会等待多长时间。同时,这里指定了一个Semaphore以用于同步。
DrawObject函数的定义如下所示:
1 | void Scene::DrawObject(vk::CommandBuffer cmd, uint32_t currentBuffer) { |
关于RenderPass和Subpass的一些细节在上一节中已经讲过。
对于每一个渲染Pass,我们首先调用vkCmdBindDescriptorSets绑定整个场景的常量缓冲(包含了观察矩阵和透视投影矩阵),然后调用vkCmdBindVertexBuffers绑定顶点缓冲(已经提前将所有要绘制物体的顶点存储在了同一个顶点缓冲中),如果使用索引绘制的话,还需要调用vkCmdBindIndexBuffer绑定索引缓冲。接下来对于每一个物体,都需要调用vkCmdBindPipeline绑定需要使用的渲染管线,调用vkCmdBindDescriptorSets绑定物体专属的常量缓冲(包括世界矩阵,物体的材质光照属性)。在完成这些绑定工作后,使用vkCmdDraw(索引绘制为vkCmdDrawIndexed)调用DrawCall完成绘制。
在录制完所有命令关闭命令缓冲区之后,就可以将命令缓冲区提交给队列,把所有命令放到队列上开始执行了:
1 | //Submit the command list |
这里使用了一个Fence来完成GPU和CPU的同步,只有当队列中的命令执行完成后,才会允许CPU进行接下来的工作,防止图像还没渲染完成就被呈现造成不必要的错误。
最后就是将渲染完成的图像呈递给交换链,呈现在显示器上了:
1 | auto presentInfo = vk::PresentInfoKHR() |
至此,我们已经将渲染循环的代码流程完整走了一遍,也就是说结合前五节的内容,终于可以真正地使用Vulkan绘制出图像了。