和图像零距离接触:图形渲染管线
如今已经是脱离固定管线的新时代了,GPU也不再是一个无可控制的黑盒,我们可以根据自己的需求去定制硬件需要做的任务,当下主流的渲染方式主要是光栅化 和光线追踪 ,Vulkan作为次世代图形API,也十分贴心地给我们准备了所有需要用的可编程管线:计算管线,图形管线,光线追踪管线 。
这一节我们主要探讨光栅化在Vulkan中的实现方法,因此只会讲解图形管线的具体使用。
光栅化渲染流水线简述
GPU的光栅化一般由以下几个步骤组成(以下的部分概念来自DX12龙书):
输入装配器(Input Assembler,IA) 阶段会从显卡存储中读取几何数据(顶点和索引),再将它们依据图元拓扑(Primitive Topology)装配为几何图元(Geometric Primitive),送入后续的阶段。待图元被装配完毕后,其顶点就会被送入顶点着色器阶段(Vertex Shader Stage) ,顶点着色器对数据的处理是逐顶点的,在这一阶段我们要完成顶点的坐标变换和数据传递,使所有顶点处于齐次裁剪空间中,由硬件完成透视除法(齐次除法)后,所有的顶点都位于规范化设备坐标(Normalized Device Coordinates,NDC) 空间中。
曲面细分阶段(Tessellation Stage,可选阶段) 是利用镶嵌化处理技术对网格中的三角形进行细分(subdivide),以此来增加物体表面上的三角形面数量。再将这些新增的三角形偏移到适当的位置,使网格表现出更加细腻的细节。几何着色器阶段(Geometry Shader,可选阶段) 对数据的处理是逐图元的,处理类型由图元拓扑而定,可以根据自己的需求创建和销毁几何体之后将数据输出。裁剪阶段 ,为了优化,在这个阶段中所有位于视锥体(Viewing Frustum)外的几何体和几何体部分将会被裁剪(clip)和丢弃。在光栅化阶段(Rasterization Stage) 中,硬件会自动执行视口变换 (同时执行透视除法),背面剔除 (依据三角形的绕序对背面三角形进行剔除,使需要处理的三角形数量减少为原来的一半),顶点属性插值 ,透视校正插值 (根据三角形顶点的属性值计算出其内部像素的属性值,透视校正插值确保了这个属性是线性的)。
像素着色器阶段 (Pixel Shader Stage ,或者按Khronos的说法叫片元着色器,Fragment Shader ) 对数据的处理是逐像素的,它会针对每一个像素片元(pixel fragment)进行处理,计算出对应的像素颜色。在此阶段实现光照,反射,阴影等复杂效果。在最后的输出合并阶段(Output Merger Stage,OM) ,一些像素片元可能会被丢失(例如未通过深度测试 或者模板测试 ),然后,剩下的像素片元会被写入后台缓冲区中,颜色混合(blend) 操作就是在这阶段实现的,可用于实现透明效果。
着色器模型简述
一个最简单的前向渲染模型需要一个顶点着色器和像素着色器,为了方便理解渲染过程,我将着色器的HLSL源码的main函数贴在此处,但不作过多深入。
在顶点着色器中,我们需要执行顶点的MVP矩阵变换,并将变换完成的顶点输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 VertexOut main (VertexIn input) { VertexOut output; float4x4 viewProjMatrix = mul (projMatrix, viewMatrix); output.posW = float3 (mul (worldMatrix, float4 (input.posL, 1.0f ))); output.position = mul (viewProjMatrix, float4 (output.posW, 1.0f )); output.normal = float3 (mul (worldMatrix_trans_inv, float4 (input.normal, 0.0f ))); output.tangent = float3 (mul (worldMatrix, float4 (input.tangent, 0.0f ))); output.shadowPos = mul (shadowTransform, float4 (output.posW, 1.0f )); output.texCoord = input.texCoord; return output; }
在像素着色器中,我们根据传入的颜色(图像)和材质数据执行最简单的PBR光照算法,并输出计算的值:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 struct Material { float4 diffuseAlbedo; float3 fresnelR0; float shininess; }; float4 main (PixelIn input) : SV_TARGET { float4 diffuse = float4 (0.0f ); diffuse = diffuseAlbedo * tex.Sample (samplerState, mul ((float2x2)matTransform, input.texCoord)); input.normal = normalize (input.normal); float3 toEye = normalize (eyePos.xyz - input.posW); const float shininess = 1.0f - roughness; Material mat = { diffuseAlbedo, fresnelR0, shininess }; float3 lightingResult = ComputeDirectionalLight (lights[0 ], mat, input.normal, toEye) + ComputePointLight (lights[NUM_DIRECTIONAL_LIGHT], mat, input.posW, input.normal, toEye) + ComputeSpotLight (lights[NUM_DIRECTIONAL_LIGHT + NUM_POINT_LIGHT], mat, input.posW, input.normal, toEye); float4 litColor = diffuse * (ambientLight + float4 (lightingResult, 1.0f )); float3 r = reflect (-toEye, input.normal); float4 reflectionColor = cubeMap.Sample (cubeMapSampler, r); float3 fresnelFactor = SchlickFresnel (fresnelR0, input.normal, r); litColor.rgb += shininess * fresnelFactor * reflectionColor.rgb; litColor.a = diffuse.a; return litColor; }
配置Vulkan渲染管线
接下来我们要将上面所讲东西与Vulkan API实际结合起来,进行Vulkan渲染管线的创建。
着色器模块
Vulkan中使用的着色器是以名为SPIR-V的二进制代码为源码的,SPIR-V的出现极大地推进了不同着色器语言的互译和统一,无论是GLSL还是HLSL,甚至CG语言,都可以通过编译器转化为SPIR-V二进制码,然后被Vulkan读取使用。由于我最喜欢的着色器语言是微软的HLSL,所以我的所有着色器都将采用HLSL转译为SPIR-V的形式。SPIR-V文件的后缀名为.spv。
我们可以使用VulkanSDK提供的glslangValidator工具来便捷地将HLSL转译为SPIR-V,用以下命令行代码来执行:
1 2 glslangValidator.exe -S vert -e main -o vertex.spv -V -D VertexShader.hlsl glslangValidator.exe -S frag -e main -o fragment.spv -V -D PixelShader.hlsl
-S指定了编译地着色器类型,-e指定了着色器地入口点函数,-o指定了输出spv文件的名称,-V指定了源文件地址,如果是HLSL还必须加上-D标记。运行成功后能获得对应的spv文件,然后就可以用用C++的方式将spv二进制码载入到内存中,用于创建着色器模块。
我们定义了以下辅助函数来帮助创建Vulkan的着色器模块。setCodeSize和setPCode函数指定了存储的spv二进制码的内存空间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 vk::ShaderModule CreateShaderModule (const std::string& path, vk::Device device) { std::ifstream loadFile (path, std::ios::ate | std::ios::binary) ; if (!loadFile.is_open ()) { } size_t fileSize = (size_t )loadFile.tellg (); std::vector<char > buffer (fileSize) ; loadFile.seekg (0 ); loadFile.read (buffer.data (), fileSize); loadFile.close (); vk::ShaderModuleCreateInfo createInfo = {}; createInfo.setCodeSize (buffer.size ()); createInfo.setPCode (reinterpret_cast <const uint32_t *>(buffer.data ())); vk::ShaderModule shaderModule; if (device.createShaderModule (&createInfo, 0 , &shaderModule) != vk::Result::eSuccess) { } return shaderModule; }
得到了需要用到的顶点着色器和像素着色器模块后,将它们填写进VkPipelineShaderStageCreateInfo中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 auto vertexShader = CreateShaderModule ("Shaders\\vertex.spv" , vkInfo->device);auto pixelShader = CreateShaderModule ("Shaders\\pixel.spv" , vkInfo->device);std::vector<vk::PipelineShaderStageCreateInfo> pipelineShaderInfo (2 ) ;pipelineShaderInfo[0 ] = vk::PipelineShaderStageCreateInfo () .setPName ("main" ) .setModule (vertexShader) .setStage (vk::ShaderStageFlagBits::eVertex); pipelineShaderInfo[1 ] = vk::PipelineShaderStageCreateInfo () .setPName ("main" ) .setModule (pixelShader) .setStage (vk::ShaderStageFlagBits::eFragment); ``` 除了常规的着色器功能以外,Vulkan还提供了一个**特殊映射入口(Specialization Map Entry)**,这允许我们将一些特定的数据直接在管线创建时就传入着色器中。这个看似不起眼的功能有的时候却能给予我们极大的方便,它的用法演示如下(format代表数据类型,data代表具体数据): ```C++ auto SMEData= vk::SpecializationMapEntry () .setConstantID (0 ) .setOffset (0 ) .setSize (sizeof (format)); auto specializationInfo = vk::SpecializationInfo () .setDataSize (sizeof (format)) .setMapEntryCount (1 ) .setPMapEntries (&SMEData) .setPData (&data); pipelineShaderInfo[1 ].setPSpecializationInfo (&specializationInfo);
在着色器中对应如下:
1 2 3 [vk::constant_id (0 )] const format SMEData;
管线动态阶段
在Vulkan中,大部分的管线参数都将在管线被创建时指定,此后无法更改,但是管线动态阶段的存在允许一些参数在管线被创建之后,在真正调用渲染命令之前再次由用户进行更改。在老版本的Vulkan中,能够添加到管线动态阶段中的管线参数少得可怜,但在Vulkan1.3中,更多的参数得以允许被添加到管线动态阶段中。管线动态阶段用以下方法进行指定:
1 2 3 4 5 6 7 std::vector<vk::DynamicState> dynamicStates; dynamicStates.push_back (vk::DynamicState::eScissor); dynamicStates.push_back (vk::DynamicState::eViewport); dynamicStates.push_back (vk::DynamicState::eBlendConstants); auto dynamicInfo = vk::PipelineDynamicStateCreateInfo () .setDynamicStateCount (dynamicStates.size ()) .setPDynamicStates (dynamicStates.data ());
根据VkSpec,以下参数是被允许添加到管线动态阶段的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 typedef enum VkDynamicState { VK_DYNAMIC_STATE_VIEWPORT = 0 , VK_DYNAMIC_STATE_SCISSOR = 1 , VK_DYNAMIC_STATE_LINE_WIDTH = 2 , VK_DYNAMIC_STATE_DEPTH_BIAS = 3 , VK_DYNAMIC_STATE_BLEND_CONSTANTS = 4 , VK_DYNAMIC_STATE_DEPTH_BOUNDS = 5 , VK_DYNAMIC_STATE_STENCIL_COMPARE_MASK = 6 , VK_DYNAMIC_STATE_STENCIL_WRITE_MASK = 7 , VK_DYNAMIC_STATE_STENCIL_REFERENCE = 8 , VK_DYNAMIC_STATE_CULL_MODE = 1000267000 , VK_DYNAMIC_STATE_FRONT_FACE = 1000267001 , VK_DYNAMIC_STATE_PRIMITIVE_TOPOLOGY = 1000267002 , VK_DYNAMIC_STATE_VIEWPORT_WITH_COUNT = 1000267003 , VK_DYNAMIC_STATE_SCISSOR_WITH_COUNT = 1000267004 , VK_DYNAMIC_STATE_VERTEX_INPUT_BINDING_STRIDE = 1000267005 , VK_DYNAMIC_STATE_DEPTH_TEST_ENABLE = 1000267006 , VK_DYNAMIC_STATE_DEPTH_WRITE_ENABLE = 1000267007 , VK_DYNAMIC_STATE_DEPTH_COMPARE_OP = 1000267008 , VK_DYNAMIC_STATE_DEPTH_BOUNDS_TEST_ENABLE = 1000267009 , VK_DYNAMIC_STATE_STENCIL_TEST_ENABLE = 1000267010 , VK_DYNAMIC_STATE_STENCIL_OP = 1000267011 , VK_DYNAMIC_STATE_RASTERIZER_DISCARD_ENABLE = 1000377001 , VK_DYNAMIC_STATE_DEPTH_BIAS_ENABLE = 1000377002 , VK_DYNAMIC_STATE_PRIMITIVE_RESTART_ENABLE = 1000377004 , VK_DYNAMIC_STATE_RAY_TRACING_PIPELINE_STACK_SIZE_KHR = 1000347000 , VK_DYNAMIC_STATE_FRAGMENT_SHADING_RATE_KHR = 1000226000 , } VkDynamicState;
顶点输入和输入装配阶段
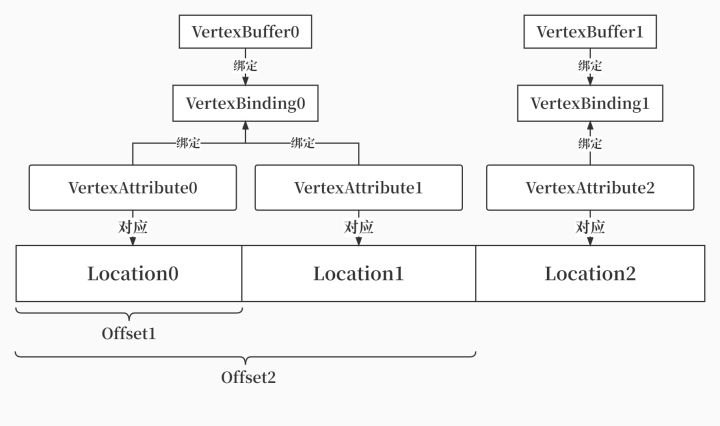
顶点输入阶段指定了顶点数据将以怎样的方式输入到顶点着色器中,需要分别描述VertexBinding和VertexAttribute,这里我用一张图来讲清楚它们的工作模式。
这张图对应的代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 vkInfo->vertex.binding.resize (2 ); vkInfo->vertex.binding[0 ].setBinding (0 ); vkInfo->vertex.binding[0 ].setInputRate (vk::VertexInputRate::eVertex); vkInfo->vertex.binding[0 ].setStride (sizeof (Vertex)); vkInfo->vertex.binding[1 ].setBinding (1 ); vkInfo->vertex.binding[1 ].setInputRate (vk::VertexInputRate::eInstance); vkInfo->vertex.binding[1 ].setStride (sizeof (Vertex)); vkInfo->vertex.attrib.resize (3 ); vkInfo->vertex.attrib[0 ].setBinding (0 ); vkInfo->vertex.attrib[0 ].setFormat (format0); vkInfo->vertex.attrib[0 ].setLocation (0 ); vkInfo->vertex.attrib[0 ].setOffset (0 ); vkInfo->vertex.attrib[1 ].setBinding (0 ); vkInfo->vertex.attrib[1 ].setFormat (format1); vkInfo->vertex.attrib[1 ].setLocation (1 ); vkInfo->vertex.attrib[1 ].setOffset (sizeof (format0)); vkInfo->vertex.attrib[2 ].setBinding (1 ); vkInfo->vertex.attrib[2 ].setFormat (format2); vkInfo->vertex.attrib[2 ].setLocation (2 ); vkInfo->vertex.attrib[2 ].setOffset (sizeof (format0) + sizeof (format1));
首先来解释一下vertexBinding的意义:vertexBinding规定了顶点缓冲区将以什么样的方式被GPU给使用,setBinding制定了顶点缓冲区的绑定位点,setInputRate指定了顶点缓冲区的输入步率,分为逐顶点和逐实例两种,setStride指定了顶点缓冲内部的数据间隔,可以理解为一个顶点(或实例)数据的内存大小,而顶点缓冲区是由一组顶点(或实例)存储的。
接着解释以下vertexAttribute的意义:setBinding指定了绑定位点,和前面的vertexBinding相对应,指定了要使用的顶点缓冲区,setFormat指定了该条目数据的格式,setLocation指定了该条目输入到着色器中的位点,setOffset指定了该条目在所有输入到着色器的数据中的地址偏移。
下面的HLSL代码演示了vertexAttribute和着色器输入的对应关系:
1 2 3 4 5 6 struct VertexIn { float3 posL; float2 texCoord; float3 normal; };
接下来完成管线VertexInput阶段的配置:
1 2 3 4 5 auto viInfo = vk::PipelineVertexInputStateCreateInfo () .setVertexBindingDescriptionCount (vkInfo->vertex.binding.size ()) .setPVertexBindingDescriptions (vkInfo->vertex.binding.data ()) .setVertexAttributeDescriptionCount (vkInfo->vertex.attrib.size ()) .setPVertexAttributeDescriptions (vkInfo->vertex.attrib.data ());
最后完成输入装配(IA)阶段的配置:
1 2 3 auto iaInfo = vk::PipelineInputAssemblyStateCreateInfo () .setTopology (vk::PrimitiveTopology::eTriangleList) .setPrimitiveRestartEnable (VK_FALSE);
setTopology指定了输入顶点构建的图元类型,这里是三角形列表;setPrimitiveRestartEnable指定了是否开启图元重启动,这里我选择关闭,图元重启动允许我们通过特定的重启标志绘制分散的三角形或者线段,而并非是全部连在一起,Vulkan通常使用(uint[size]_t)-1作为图元重启动标志。
曲面细分阶段(可选)
当我们需要进行曲面细分时,可以通过如下方法来指定面片的控制点数量:
1 2 auto tsInfo = vk::PipelineTessellationStateCreateInfo () .setPatchControlPoints (controlPointsNum);
在Vulkan1.1版本后提供了一个可以用于指定域着色器原点位置的功能,用法如下:
1 2 3 auto domainOrigin = vk::PipelineTessellationDomainOriginStateCreateInfo () .setDomainOrigin (vk::TessellationDomainOrigin::eLowerLeft); tsInfo.setPNext (&domainOrigin);
光栅化阶段
下面演示了管线光栅化阶段的配置方法:
1 2 3 4 5 6 7 8 auto rsInfo = vk::PipelineRasterizationStateCreateInfo () .setCullMode (vk::CullModeFlagBits::eBack) .setDepthBiasEnable (VK_FALSE) .setDepthClampEnable (VK_FALSE) .setFrontFace (vk::FrontFace::eClockwise) .setLineWidth (1.0f ) .setPolygonMode (vk::PolygonMode::eFill) .setRasterizerDiscardEnable (VK_FALSE);
setCullMode指定了剔除的方法,可以指定正面剔除,背面剔除和不剔除。
setDepthBiasEnable指定了是否产生深度偏移,通过命令缓冲区的setDepthBias函数可以指定这个值。
setDepthClampEnable指定了是否将深度值钳制到[0,1]中。
setFrontFace指定了图元的正面的定义方法,分为顺时针绕序和逆时针绕序。
setLineWidth指定了绘制的线宽。
setPolygonMode指定了图元的绘制模式,可以指定填充图形,只绘制线框和只绘制顶点。
setRasterizerDiscardEnable如果打开,那么将不会对任何图元进行光栅化,该功能可用于对光栅化之前的阶段进行测试。
视口裁剪阶段
viewport指定了绘制时的视口大小和位置,可以设置渲染允许的最小深度和最大深度(NDC空间)和渲染区域在窗口中所处的位置;scissor指定了绘制时的裁剪矩形,只有位于裁剪矩形中的渲染区域才被允许显示在窗口中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 vk::Viewport viewport; viewport.setMaxDepth (1.0f ); viewport.setMinDepth (0.0f ); viewport.setX (0.0f ); viewport.setY (0.0f ); viewport.setWidth (vkInfo->width); viewport.setHeight (vkInfo->height); auto scissor = vk::Rect2D () .setOffset (vk::Offset2D (0 , 0 )) .setExtent (vk::Extent2D (vkInfo->width, vkInfo->height)); auto vpInfo = vk::PipelineViewportStateCreateInfo () .setScissorCount (1 ) .setPScissors (&scissor) .setViewportCount (1 ) .setPViewports (&viewport);
深度模板测试阶段
深度测试将顶点的深度值与深度缓冲区中的深度值进行比较并决定是否写入深度缓冲区中,把比较OP设置为Less就可以确保被遮挡的物体不会被绘制出来。
模板缓冲操作允许我们在渲染片段时将模板缓冲设定为一个特定的值。通过在渲染时修改模板缓冲的内容,我们写入了模板缓冲。在同一个(或者接下来的)渲染迭代的模板测试中,我们可以读取这些值,来决定丢弃还是保留某个片段。
1 2 3 4 5 6 auto dsInfo = vk::PipelineDepthStencilStateCreateInfo () .setDepthTestEnable (VK_TRUE) .setDepthWriteEnable (VK_TRUE) .setDepthCompareOp (vk::CompareOp::eLess) .setDepthBoundsTestEnable (VK_FALSE) .setStencilTestEnable (VK_FALSE);
颜色混合阶段
下面演示了颜色混合阶段的配置方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 auto attState = vk::PipelineColorBlendAttachmentState () .setColorWriteMask (vk::ColorComponentFlagBits::eR | vk::ColorComponentFlagBits::eG | vk::ColorComponentFlagBits::eB | vk::ColorComponentFlagBits::eA) .setBlendEnable (VK_TRUE) .setColorBlendOp (vk::BlendOp::eAdd) .setSrcColorBlendFactor (vk::BlendFactor::eSrcAlpha) .setDstColorBlendFactor (vk::BlendFactor::eOneMinusSrcAlpha) .setAlphaBlendOp (vk::BlendOp::eAdd) .setSrcAlphaBlendFactor (vk::BlendFactor::eZero) .setDstAlphaBlendFactor (vk::BlendFactor::eOne); auto cbInfo = vk::PipelineColorBlendStateCreateInfo () .setLogicOpEnable (VK_FALSE) .setAttachmentCount (1 ) .setPAttachments (&attState) .setLogicOp (vk::LogicOp::eNoOp);
每一个颜色附件都可以用一个用VkPipelineColorBlendAttachmentState结构体指定其混合方法,而混合方法是由对应的混合方程来构建的,混合方程的形式如下:
1 新的颜色值 = 源颜色值 * 源混合因子 混合运算符 目标颜色值 * 目标混合因子
setColorWriteMask指定了允许写入的颜色通道,这里允许所有颜色通道写入;ColorBlendOp和AlphaBlendOp分别指定了RGB通道和alpha通道的混合运算符;SrcColorBlendFactor和DstBlendFactor分别指定了源混合因子和目标混合因子,同样分为RGB通道和alpha通道。同时,Vulkan还允许一个混合常量参与到混合方程中,用vk::PipelineColorBlendStateCreateInfo::setBlendConstants函数指定,并且也可以被包含在动态阶段中通过调用命令缓冲区更改。
除了普通的混合方程外,Vulkan还提供了另一个控制混合的方法:逻辑运算符。要使用逻辑运算符方法,需要启用LogicOp并且用setLogicOp函数设定逻辑运算符。
逻辑运算符只能用于有符号/无符号归一化整型,而不能用于浮点数类型和SRGB格式附件,也就是说逻辑运算符并不是用于常规的颜色混合的。注意,若使用逻辑运算符,则第一种混合方程形式会自动失效,但ColorWriteMask依旧有效。
不同逻辑运算符枚举量的具体含义如下(摘自VkSpec):
¬表示按位非,∧表示按位与,∨表示按位或,⊕表示按位异或
枚举量
逻辑运算符
VK_LOGIC_OP_CLEAR
全部用0填充
VK_LOGIC_OP_AND
s ∧ d
VK_LOGIC_OP_AND_REVERSE
s ∧ ¬ d
VK_LOGIC_OP_COPY
s
VK_LOGIC_OP_AND_INVERTED
¬ s ∧ d
VK_LOGIC_OP_NO_OP
d
VK_LOGIC_OP_XOR
s ⊕ d
VK_LOGIC_OP_OR
s ∨ d
VK_LOGIC_OP_NOR
¬ (s ∨ d)
VK_LOGIC_OP_EQUIVALENT
¬ (s ⊕ d)
VK_LOGIC_OP_INVERT
¬ d
VK_LOGIC_OP_OR_REVERSE
s ∨ ¬ d
VK_LOGIC_OP_COPY_INVERTED
¬ s
VK_LOGIC_OP_OR_INVERTED
¬ s ∨ d
VK_LOGIC_OP_NAND
¬ (s ∧ d)
VK_LOGIC_OP_SET
全部用1填充
多重采样
多重采样是一种使用更多颜色、深度和模板信息对图元进行反走样处理的技术,在Vulkan中,我们可以让管线帮我们进行多重采样反走样(MSAA):
1 2 3 4 5 6 auto msInfo = vk::PipelineMultisampleStateCreateInfo () .setAlphaToCoverageEnable (VK_TRUE) .setAlphaToOneEnable (VK_FALSE) .setMinSampleShading (1.0f ) .setRasterizationSamples (vk::SampleCountFlagBits::e1) .setSampleShadingEnable (VK_TRUE);
多重采样通过跨子像素共享一些计算信息,使用多倍于屏幕分辨率的后台缓冲区和深度缓冲区来进行硬件反走样。RasterizationSamples指定了对于每个像素实现多重采样的子像素数量;setSampleShadingEnable用于开启对绘制的几何体内部的多重采样;MinSampleShading用于指定SampleShading相对于RasterizationSamples的最小分数(例如若RasterizationSamples=4,MinSampleShading=0.5,则实际用于SampleShading的采样数量为2),这个数越接近于1效果越好;开启AlphaToCoverage会使硬件检测像素着色器所返回的alpha并将其用于确定覆盖的情况,该技术用于解决以alpha遮罩的形式裁剪纹理时出现的锯齿边缘问题;开启AlphaToOne则会使所有的alpha都被强制置换为1。
开启SampleShading需要启用VkPhysicalDeviceFeatures中的SampleRateShading功能。
管线布局
正如OpenGL有UniformBuffer,Direct3D12有描述符,Vulkan也有一个相似的结构用来描述向着色器中提供常量缓冲的方式,这个结构就叫管线布局(Pipeline Layouts),合理地分配和使用管线布局是充分运用着色器功能的必要条件之一,下面我将详细讲解管线布局的创建和使用方法。
管线布局由两块组成,一块是用于传递轻量级数据的PushConstant,它的特点是易于改变,快捷方便;另一块是用于传递大量数据的layouts,它的特点是包罗万象,规范工整。
首先来讲解最简单的PushConstant的用法,它简单就简单在只需要一块内存,一个指针,一个范围,就可以完成指定,如下所示:
1 2 3 4 5 6 7 8 auto range = vk::PushConstantRange () .setOffset (0 ) .setSize (dataSize) .setStageFlags (vk::ShaderStageFlagBits::eAll); auto plInfo = vk::PipelineLayoutCreateInfo ();plInfo.setPushConstantRangeCount (1 ); plInfo.setPPushConstantRanges (&range);
PushConstant的属性可以由一系列VkPushConstantRange结构体指定,这个结构体的内容十分简单,指定了偏移值,数据大小和需要使用的着色器。
更新PushConstant需要在DrawCall之前调用pushConstant函数:
1 cmd.pushConstants (vkInfo->pipelineLayout["scene" ], vk::ShaderStageFlagBits::eAll, 0 , dataSize, &data);
在HLSL里用以下方式引用PushConstant数据:
1 2 3 4 5 [vk::push_constant] struct PushConstant { };
解决完较为简单的PushConstant后就要深入更加复杂的描述符集了,描述符集由一系列VkDescriptorSetLayout对象指定并绑定到管线布局上,详细规定了资源将以什么样的方式被GPU所访问:
1 2 plInfo.setSetLayoutCount (renderEngine.descSetLayout.size ()) plInfo.setPSetLayouts (renderEngine.descSetLayout.data ());
下面演示了描述符集的一种典型的分配模式,即将需要以不同频率更新的描述符放在不同的描述符集中,例如这里将世界矩阵放在第一个描述符集中,和材质相关的放在第二个描述符集中,这样可以大大方便绘制时更新描述符和按照需求添加新的描述符:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 auto objCBBinding = vk::DescriptorSetLayoutBinding () .setBinding (0 ) .setDescriptorCount (1 ) .setDescriptorType (vk::DescriptorType::eUniformBuffer) .setStageFlags (vk::ShaderStageFlagBits::eVertex); vk::DescriptorSetLayoutBinding layoutBindingObject[] = { objCBBinding }; auto materialCBBinding = vk::DescriptorSetLayoutBinding () .setBinding (0 ) .setDescriptorCount (1 ) .setDescriptorType (vk::DescriptorType::eUniformBuffer) .setStageFlags (vk::ShaderStageFlagBits::eFragment); auto samplerBinding = vk::DescriptorSetLayoutBinding () .setBinding (1 ) .setDescriptorCount (1 ) .setDescriptorType (vk::DescriptorType::eSampler) .setStageFlags (vk::ShaderStageFlagBits::eFragment); auto textureBinding = vk::DescriptorSetLayoutBinding () .setBinding (2 ) .setDescriptorCount (1 ) .setDescriptorType (vk::DescriptorType::eSampledImage) .setStageFlags (vk::ShaderStageFlagBits::eFragment); auto normalMapBinding = vk::DescriptorSetLayoutBinding () .setBinding (3 ) .setDescriptorCount (1 ) .setDescriptorType (vk::DescriptorType::eSampledImage) .setStageFlags (vk::ShaderStageFlagBits::eFragment); vk::DescriptorSetLayoutBinding layoutBindingMaterial[] = { textureBinding, materialCBBinding, samplerBinding, normalMapBinding }; descSetLayout.resize (2 ); auto descLayoutInfo_obj = vk::DescriptorSetLayoutCreateInfo () .setBindingCount (1 ) .setPBindings (layoutBindingObject); vkInfo->device.createDescriptorSetLayout (&descLayoutInfo_obj, 0 , &descSetLayout[0 ]); auto descLayoutInfo_material = vk::DescriptorSetLayoutCreateInfo () .setBindingCount (4 ) .setPBindings (layoutBindingMaterial); vkInfo->device.createDescriptorSetLayout (&descLayoutInfo_material, 0 , &descSetLayout[1 ]);
每一个描述符集下面可以拥有多个绑定的描述符(VkDescriptorSetLayoutBinding),而对于每个描述符,在VkDescriptorSetLayoutBinding结构体中可以指定其绑定位点(binding),描述符数量(descriptorCount),描述符类型(descriptorType),允许访问的着色器(stageFlags)。通过填写VkDescriptorSetLayoutCreateInfo将多个描述符绑定在一起创建一个描述符集。
在HLSL里用以下方式引用描述符集指定的数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 [vk::binding (0 , 0 )] cbuffer ObjectConstants { float4x4 worldMatrix; }; [vk::binding (0 , 1 )] cbuffer MaterialConstants { float4x4 matTransform; float4 diffuseAlbedo; float3 fresnelR0; float roughness; }; [vk::binding (1 , 1 )] SamplerState samplerState; [vk::binding (2 , 1 )] Texture2D tex; [vk::binding (3 , 1 )] Texture2D normalMap;
注意vk::binding中的第二个参数代表了描述符集序号,第一个参数代表了描述符集下的绑定位点序号。
有关描述符的更多内容将会在以后讲解,这里不作过多赘述,继续回到管线的创建工作中来。
衍生管线
当我们需要两个大多数参数相同的管线时,Vulkan允许我们用一个管线作为基础去创建衍生管线以达到优化的效果,VkGraphicsPipelineCreateInfo中的basePipelineHandle和basePipelineIndex就是派这个用途的。指定basePipelineHandle允许我们以一个已经创建的管线作为基础管线,指定basePipelineIndex允许我们以一个尚未创建的管线作为基础管线,但这个管线必须和衍生管线用同一个创建命令创建且优先于衍生管线创建。基础管线的flags需要指定VK_PIPELINE_CREATE_ALLOW_DERIVATIVES_BIT标志,衍生管线的flags需要指定VK_PIPELINE_CREATE_DERIVATIVE_BIT标志。
管线缓存
虽然大多数时候我们并不需要特别注意管线缓存,但通过复用创建管线所遗留的缓存可以达到节省资源的目的,这便是管线缓存的意义所在。
用以下方法创建管线缓存:
1 2 3 4 5 6 7 8 9 10 11 12 13 typedef struct VkPipelineCacheCreateInfo { VkStructureType sType; const void * pNext; VkPipelineCacheCreateFlags flags; size_t initialDataSize; const void * pInitialData; } VkPipelineCacheCreateInfo; VkResult vkCreatePipelineCache ( VkDevice device, const VkPipelineCacheCreateInfo* pCreateInfo, const VkAllocationCallbacks* pAllocator, VkPipelineCache* pPipelineCache)
initialDataSize指定了初始的缓存数据大小,若为0,则代表缓存一开始是空的。
pInitialData是一个指向管线缓存数据的指针,可以用vkGetPipelineCacheData函数获取。
在Vulkan1.3中,可以给flags指定VK_PIPELINE_CACHE_CREATE_EXTERNALLY_SYNCHRONIZED_BIT,标志管线缓存不使用默认的内部同步而是采用外部多线程同步。(需要启用pipelineCreationCacheControl功能特性)
用以下方法可以将多个管线缓存合并:
1 2 3 4 5 VkResult vkMergePipelineCaches ( VkDevice device, VkPipelineCache dstCache, uint32_t srcCacheCount, const VkPipelineCache* pSrcCaches)
dstCache指向合并后的管线缓存。
srcCacheCount和pSrcCaches指定了要合并的管线缓存。
用以下方法获取管线缓存中的数据:
1 2 3 4 5 VkResult vkGetPipelineCacheData ( VkDevice device, VkPipelineCache pipelineCache, size_t * pDataSize, void * pData)
pipelineCache指向了要查询的管线缓存。
pDataSize和pData指针用于获取数据的大小和指针。
在完成了这一切的准备工作后,就可以最终完成管线的创建了(这里我为了省事没有指定管线缓存):
1 device.createGraphicsPipelines (vk::PipelineCache (), 1 , &pipelineInfo, 0 , &pipeline);
这一节我们花了非常冗长的篇幅详细了解了光栅化渲染管线的一些细节,对于这些细节的深刻理解对于我们之后的绘制工作会大有裨益。