随机试验与随机事件
随机试验
在自然界和人类社会中出现的各种现象大致可以分为两类:必然现象和随机现象。在一定条件下必然出现的现象叫做必然现象;在相同的条件下,可能出现不同的结果,而在试验或观测之前不能预知确切的结果的现象叫做随机现象。
为了研究和揭示随机现象的统计规律性,我们需要对随机现象进行大量重复的观察、测量或试验。具有以下特点的试验称为随机试验:
- 可重复性:可以在相同条件下重复进行;
- 可观测性:每次试验的所有可能结果都是明确的,可以观测的,并且试验结果有两个或两个以上;
- 随机性:每次试验结果不确定。
随机试验简称试验,通常用字母 E 表示。随机试验 E 的基本结果称为样本点,用 ω 表示。称随机试验 E 的所有基本结果的集合为样本空间,用 Ω=∣ω∣ 表示。
随机事件及其运算
我们把随机试验 E 的样本空间 Ω=∣ω∣ 的子集称为随机试验 E 的随机事件,简称为事件,用大写字母 A,B,C 等表示。设 A⊆Ω,如果试验结果 ω∈A,则称在这次试验中事件 A 发生;如果 ω∈/A,则称事件 A 不发生。
下面是一些基本概念:
- 随机事件:样本空间的子集,是由若干样本点构成的集合,记为 A,B,C 等。
- 事件发生:当事件 A 所包含的样本点有一个出现,就说事件 A 发生了,否则就说事件 A 未发生。
- 基本事件:由一个样本点组成的事件。
- 必然事件:包含样本空间 Ω 的所有样本点,每次试验必然发生。
- 不可能事件:空集 ∅,不包含任何样本点,每次试验都不可能发生。
随机事件的关系与运算:
| 名称 |
表达式 |
含义 |
| 包含 |
A⊂B |
A 发生必然导致 B 发生 |
| 相等 |
A=B A⊂B 且 B⊂A |
A 与 B 为同一事件 |
| 并(和) |
A∪B |
A 与 B 至少有一个发生 |
| 交(积) |
A∩B=AB |
A 与 B 同时发生 |
| 差 |
A−B |
A 发生,B 不发生 |
| 互不相容(互斥) |
AB=∅ |
A 与 B 不能同时发生 |
| 互逆(对立) |
A=B A∪B=Ω 且 AB=∅ |
A 与 B 中有且只有一个发生 |
基本运算律:
运算顺序:逆交并差,括号优先。
- 交换律:A∪B=B∪A,AB=BA
- 结合律:(A∪B)∪C=A∪(B∪C),(AB)C=A(BC)
- 分配律:(A∪B)C=(AC)∪(BC),A∪(BC)=(A∪B)(A∪C)
- 对偶律:A∪B=A B,AB=A∪B
i=1⋃nAi=i=1⋂nAii=1⋂nAi=i=1⋃nAi
- 吸收律:若 A⊂B,则 A∪B=B,AB=A.
- 差化积:A−B=AB=A−AB
- 逆:A=A
- AB=∅⟺A⊂B⟺B⊂A
随机事件的概率
频率与概率
定义: 设在相同的条件下进行的 n 次试验中,事件 A 发生了 nA 次,则称 nA 为事件 A 发生的频数,称比值 nnA 为事件 A 发生的频率,记作 fn(A),即
fn(A)=nnA
频率具有如下基本性质:
- 非负性:对于任意事件 A,有 fn(A)≥0;
- 规范性:对于必然事件 Ω,有 fn(Ω)=1;
- 优先可加性: 对于两两互不相容的事件 A1,A2,⋯,Am(即当 i=j 时,有 AiAj=∅,i,j=1,2,⋯,m),有
fn(i=1⋃mAi)=i=1∑mfn(Ai)
大量的试验表明,在相同的条件下重复进行 n 次试验,当 n 增大时,事件 A 发生的频率 fn(A) 呈现出稳定性,逐渐稳定于某一常数 p,我们用这一常数 p 表示事件 A 发生的可能性大小,称为事件 A 的概率,记为 P(A)=p.
定义: 设随机试验 E 的样本空间为 Ω,如果对于 E 的每一个事件 A,有唯一的实数 P(A) 和它对应,并且这个事件的函数 P(A) 满足以下条件:
- 非负性:对于任一事件 A,有 P(A)≥0;
- 规范性:对于必然事件 Ω,有 P(Ω)=1;
- 可列可加性:对于两两互不相容的事件 A1,A2,⋯,有
P(i=1⋃∞Ai)=i=1∑∞P(Ai)
则称 P(A) 为事件 A 的概率。
根据上述定义,可以得到概率的一些性质:
性质 1: 对于不可能事件 ∅,有 P(∅)=0.
性质 2(有限可加性): 对于两两互不相容的事件 A1,A2,⋯,An,有
P(i=1⋃nAi)=i=1∑nP(Ai)
性质 3: 对于任一事件 A,有 P(A)=1−P(A).
性质 4: 如果 A⊆B,则有
P(B−A)=P(B)−P(A),P(A)≤P(B)
性质 5: 对于任一事件 A,有 P(A)≤1.
性质 6(减法公式): 对于任意两个事件 A 与 B,有
P(B−A)=P(B)−P(AB)
性质 7(加法公式): 对于任意两个事件 A 与 B,有
P(A∪B)=P(A)+P(B)−P(AB),P(A∪B)≤P(A)+P(B)
推广:概率的一般加法公式为
P(i=1⋃nAi)=i=1∑nP(Ai)−1≤i<j≤n∑P(AiAj)+1≤i<j<k≤n∑P(AiAjAk)+⋯+(−1)n−1P(A1A2⋯An)
古典概型
如果随机试验具有以下两个特点:
- 试验的样本空间 Ω 只包含有限个样本点;
- 在试验中每个基本事件发生的可能性相同,
则称这种试验为等可能概型或古典概型。
古典概型中事件 A 的概率计算方式:
P(A)=Ω包含的基本事件总数A包含的基本事件个数
由这一公式可知,要计算古典概型中事件 A 的概率,只需算出样本空间 Ω 包含的基本事件总数及事件 A 包含的基本事件个数。这时常常用到加法原理、乘法原理以及排列组合公式。
特点: 有限性和等可能性
排列组合相关知识:
- 加法原理:完成一件事有 n 类方法,第 i 类方法中有 mi 种具体的方法,则完成这件事共有 i=1∑nmi 种不同的方法。
- 乘法原理:完成一件事有 n 个步骤,第 i 个步骤中有 mi 种具体的方法,则完成这件事共有 i=1∏nmi 种不同的方法。
- 组合:从 n 个不同的元素中(不放回地)取出 m 个组成一组,不同的分法共有
Cnm=m!(n−m)!n!
- 排列:从 n 个不同的元素中(不放回地)取出 m 个按一定的次序排成一排,不同的排法共有
Anm=n(n−1)(n−2)⋯(n−m+1)=(n−m)!n!
- 全排列:Ann=n!
- 可重复排列:从 n 个不同的元素中可重复地取出 m 个排成一排,不同的排法共有 nm.
- 分类分组:n 个元素分 m 类,第 i 类中有 ki 个相同地元素,且 k1+k2+⋯+km=n,不同的排法共有
Cnk1Cn−k1k2⋯Ckmkm=k1!k2!⋯km!n!
摸球问题: 袋中有 a 只白球,b 只红球,每次任取一只,取后不放回,进行 k+1 (k+1≤a+b) 次,则最后一次取到白球的概率为
P(A)=Aa+bk+1Aa1Aa+b−1k=a+ba
随机取数问题:
例:从 0, 1, 2, …, 9 这十个数字中任意取出 4 个,求能排成一个四位偶数的概率。
解:从 0 至 9 中任取 4 个数并进行排列得到的数字的个数为 C104A44=5040.
- 当个位为 0 时,排列得到的四位偶数的个数为 C93A33=504;
- 当个位不为0时,四位偶数的个数为 C41C81C82A22=1792.
综上所述,所求概率为 5040504+1792=9041.
分房问题: 将 n 个人随机地分配到 N (n≤N) 个房间,则每个房间至多有一人的概率为
P(A)=NnANn
某指定的 n 个房间各有一人的概率为
P(B)=Nnn!
几何概型
在古典概型中利用等可能性计算了一类问题的概率,但古典概型要求基本事件的总数必须是有限个。人们希望把这种做法推广到无限个基本事件,而这些基本事件又有某种等可能性的情形。
如果随机试验是将一个点随机地投到某一区域 Ω(Ω 可以是直线上的某一区间,也可以是平面或空间内的某一区域)内,而这个随机点落在 Ω 中任意两个度量相等的子区域内的可能性是一样的,则称这样的试验属于几何概型。对于任何有度量的子区域 A⊆Ω,我们定义事件 $A = $ “随机点落在区域 A 内” 的概率为
P(A)=Ω的度量A的度量
特点: 无限性和等可能性
蒲丰投针问题: 在平面上画有等距离的平行线,平行线间的距离为 2a (a>0). 向该平面任意投掷一枚长为 2l (l<a) 的圆柱形的针,求此针与任一平行线相交的概率。
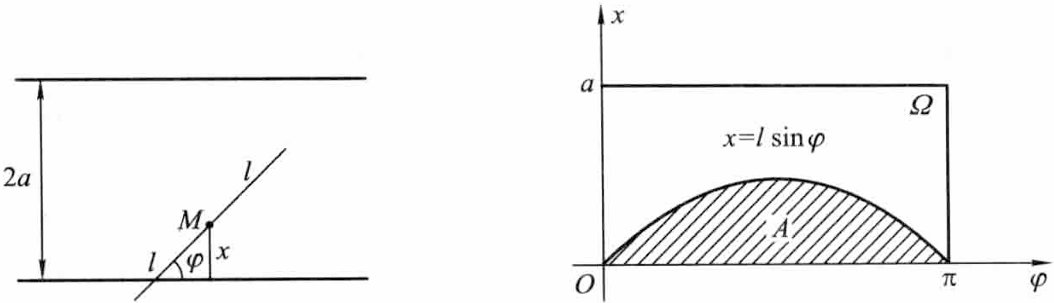
解: 针投在该平面上,以 x 表示针的中点 M 到最近的一条平行线的距离,以 φ 表示针与此直线的交角,则有
0≤x≤a,0≤φ≤π
针与最近的一条平行线相交的充分必要条件是
x≤lsinφ
设
ΩA={(φ,x)∣0≤φ≤π,0≤x≤a}={(φ,x)∣0≤φ≤π,0≤x≤lsinφ}
则所求概率为
p=Ω的面积A的面积=πa∫0πlsinφdφ=πa2l
条件概率
条件概率与乘法公式
定义: 设 A 和 B 是试验 E 的两个事件,且 P(A)>0,称 P(AB)/P(A) 为在事件 A 已经发生的条件下,事件 B 发生的条件概率,记为 P(B∣A),即
P(B∣A)=P(A)P(AB)
由这个定义可知,对于任意两个事件 A 及 B,如果 P(A)>0,则有
P(AB)=P(A)P(B∣A)
称上式为概率的乘法公式。
条件概率具有如下性质:
- 非负性:对任意事件 B,有 P(B∣A)≥0;
- 规范性:对于必然事件 Ω,有 P(Ω∣A)=1;
- 可列可加性:对于两两互不相容的事件 B1,B2,⋯, 有
P((i=1⋃∞Bi)∣A)=i=1∑∞P(Bi∣A)
可由条件概率的三个基本性质推导出其他一些性质:
- P(∅∣A)=0;
- P(B∣A)=1−P(B∣A);
- P((B1−B2)∣A)=P(B1∣A)−P(B1B2∣A);
- P((B1∪B2)∣A)=P(B1∣A)+P(B2∣A)−P((B1B2)∣A).
乘法公式的推广:
- 当 P(AB)>0 时,P(ABC)=P(A)P(B∣A)P(C∣AB);
- 当 P(A1A2⋯An−1)>0 时,P(A1A2⋯An)=P(A1)P(A2∣A1)⋯P(An∣A1A2⋯An−1).
例:设 M 件产品中有 m 件是不合格品,从中任取两件,在所取产品中有一件是不合格品的条件下,求另一件也是不合格品的概率。
解:设 A 表示事件 “所取产品中至少有一个是不合格品”,B 表示事件 “所取产品都是不合格品”,则
P(A)=CM2Cm2+Cm1CM−m1,P(B)=CM2Cm2
又因为 P(AB)=P(B),所以所求概率为
P(B∣A)=P(A)P(AB)=P(A)P(B)=2M−m−1m−1
结论: 设 A,B 为随机事件,若 0<P(A)<1,0<P(B)<1,则 P(A∣B)>P(A∣B) 的充要条件是 P(B∣A)>P(B∣A).
证明:
P(A∣B)>P(A∣B) 等价于 P(B)P(AB)>P(B)P(AB)=1−P(B)P(A)−P(AB),即 P(AB)>P(A)P(B).
P(B∣A)>P(B∣A) 等价于 P(A)P(AB)>1−P(A)P(B)−P(AB),即 P(AB)>P(A)P(B).
全概率公式
设 A1,A2,⋯,An 为 Ω 中的事件,满足
- 事件 A1,A2,⋯,An 互不相容(即 AiAj=∅, i=j, i,j=1,2,⋯);
- ⋃iAi=Ω.
则称 A1,A2,⋯,An 为 Ω 的一个 (有限)分割或完全事件组。
如果 P(Ai)>0 (i=1,2,⋯,n),则
B=i=1⋃nAiB,(AiB)(AjB)=∅
根据乘法公式得
P(B)=i=1∑nP(Ai)P(B∣Ai)
这个公式称为全概率公式,它是概率论的一个基本公式。
例:某车间有四个班组生产同一种产品,其产量分别占总产量的 15%、20%、30%、35%,次品率分别为 0.05、0.04、0.03、0.02,现从全部产品中任取一件,问恰好取到次品的概率是多少?
解:设 Ai 表示事件 “取到 i 组的产品”,i=1,2,3,4,B 表示事件 “恰好取到次品”,
P(B)=i=1∑4P(Ai)P(B∣Ai)=0.15×0.05+0.2×0.04+0.3×0.03+0.35×0.02=0.0315
贝叶斯(Bayes)公式
设 Ω 为试验 E 的基本空间,B 为任意事件,A1,A2,⋯,An 为 Ω 的一个划分,且 P(Ai)>0 (i=1,2,⋯,n),如果 P(B)>0,则
P(Aj∣B)=i=1∑nP(Ai)P(B∣Ai)P(Aj)P(B∣Aj), j=1,2,⋯,n
这个公式称为贝叶斯公式。
其中 P(Ai) 称为先验概率,它是由以往的经验得到的,是事件 B 的原因;条件概率 P(Ai∣B) 称为后验概率,它是事件 B 发生后,再对导致 B 发生的原因的可能性大小重新加以评估得到的。
例:学生在做一道有 4 个选项的选择题时,如果他不知道问题的正确答案,就做随机猜测。假设学生认为自己知道正确答案的概率为 0.2,试求学生确实知道正确答案的概率。
解:设事件 A 为 “题答对了”,事件 B 为 “知道正确答案”,则由题意得
P(A∣B)=1,P(A∣B)=0.25
所以由贝叶斯公式得
P(B∣A)=P(B)P(A∣B)+P(B)P(A∣B)P(B)P(A∣B)=0.2×1+0.8×0.250.2×1=0.5
所求概率即为 0.5。
事件的独立性
定义: 设 A,B 是试验 E 的两个随机事件,如果
P(AB)=P(A)P(B)
则称事件 A 和事件 B 相互独立。
容易得到如下结论:对于同一试验 E 的两个事件 A 与 B,如果 P(A)>0,则 A 与 B 相互独立的充分必要条件为 P(B∣A)=P(B);如果 P(B)>0,则 A 与 B 相互独立的充分必要条件为 P(A∣B)=P(A).
结论 1: 若事件 A 与 B 相互独立,则 A 与 B,B 与 A,A 与 B 均独立。
证明:因为
P(AB)=P(A)−P(AB)=P(A)−P(A)P(B)=P(A)[1−P(B)]=P(A)P(B)
因此事件 A 与事件 B 是相互独立的。同理,可证明其它结论。
结论 2: 若 P(A)>0,P(B)>0,则事件 A,B 相互独立与 A,B 互不相容不能同时成立。
结论 3: 必然事件 Ω 和不可能事件 Φ 与任何事件都是独立的。
三个事件的独立性: 对于同一试验的三个事件 A,B,C,如果满足
P(AB)=P(A)P(B)P(BC)=P(B)P(C)P(AC)=P(A)P(C)
则称三个事件 A,B,C 是两两相互独立的。此时如果
P(ABC)=P(A)P(B)P(C)
则称三个事件 A,B,C 是相互独立的。
n 个事件的独立性: 设 A1,A2,⋯,An 是同一试验的 n 个事件,如果对于任意正整数 k 及这 n 个事件中的任意 k (2≤k≤n) 个事件 Ai1,Ai2,⋯,Aik,都有等式
P(Ai1Ai2⋯Aik)=P(Ai1)P(Ai2)⋯+P(Aik)
成立,则称 n 个事件 A1,A2,⋯,An 是相互独立的。
n 个事件相互独立的含义是它们中的几个事件发生与否不影响另外一些事件发生的概率。在实际问题中,往往不是用定义去判断事件的独立性,而是根据问题的实际意义去确定。
伯努利(Bernoulli)概型
n 重伯努利试验概型:
- 试验重复做 n 次;
- 每次试验只有两个可能的结果:A 和 A,且 P(A)=p (0<p<1);
- 每次试验的结果与其他次试验无关,称这 n 次试验是相互独立的。
在 n 重伯努利概型中,事件 A 发生 k 次的概率为
Pn(k)=Cnkpk(1−p)n−k,k=0,1,2,⋯,n.
该式又称为二项概率公式。
概率很小的随机事件在一次试验中实际上几乎不发生,这一原理称为小概率事件的实际不可能原理,又称为实际推断原理。
例: 设每次试验的成功率为 p (0<p<1),将试验独立重复地进行,求直到第 n 次才取得第 r (1<r<n) 次成功的概率。
解:总共进行 n 次试验,其中有 r 次成功,且第 r 次成功,有 n−r 次失败,所以令 k=n−r,即得所求概率为
Cr+k−1r−1pr(1−p)k=Cr+(n−r)−1r−1pr(1−p)n−r=Cn−1r−1pr(1−p)n−r
随机变量及其分布
随机变量的分布函数
定义: 设随机试验 E 的样本空间为 Ω={ω}. 如果对每一个 ω∈Ω,都有一个实数 X(ω) 与之对应,则称 X=X(ω) (ω∈Ω) 为随机变量。
随机变量 X 是样本点 ω 的函数,其定义域为 Ω,值域为 R.
随机变量随着试验结果的不同而变化,常用大写字母 X,Y,Z 等表示。
由于随机变量的取值依赖于随机试验的结果,因此在试验之前我们只能知道它的所有可能取值,而不能预先知道它究竟取哪个值。因为试验的各个结果的出现都有一定的概率,所以随机变量取相应的值也有确定的概率。
用随机变量可以表示随机事件,{X=k},{a<X<b},{X>b} 等都是随机事件。
为了研究随机变量,我们引入分布函数的概念。
定义: 设 X 是一个随机变量,对于任意实数 x,令
F(x)=P{X≤x},x∈R,
称 F(x) 为随机变量 X 的分布函数。
随机变量 X 的分布函数 F(x) 是定义在 (−∞.+∞) 上的函数,是随机事件 {X≤x} 发生的概率。如果 X 是数轴上随机点的坐标,则分布函数值 F(a) 表示 X 落在区间 (−∞,a] 上的概率,如下图所示:
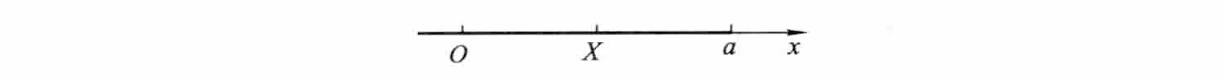
由于分布函数是普通的一元函数,因此通过它我们可以利用数学分析的方法来研究随机变量。
分布函数的基本性质:
性质 1: 对于任意实数 x,有 0≤F(x)≤1.
性质 2: 对于任意实数 x1,x2 (x1<x2),有
P{x1<X≤x2}=F(x2)−F(x1).
性质 3:
F(−∞)=x→−∞lim(x)=0F(+∞)=x→+∞lim(x)=1
性质 4: F(x) 处处右连续,即 F(x+)=F(x).
性质 5: 对于任意实数 x1,x2 (x1<x2),由于
F(x2)−F(x1)=P{x1<X≤x2}≥0,
因此 F(x) 是一个单调不减函数。
由于 F(a)=P{X≤a},则
P{X=a}P{X<a}P{X>a}P{X≥a}=F(a)−F(a−0)=F(a−0)=1−F(a)=1−F(a−0)
离散型随机变量及其概率分布
定义 1: 如果一个随机变量 X 所有可能取到的不相同的值是有限个或可列无限多个,并且以确定的概率取这些不同的值,则称 X 为离散型随机变量。
定义 2: 设离散型随机变量 X 所有可能取的值为 xk (k=1,2,⋯),X 取各个可能值的概率,即事件 {X=xk} 的概率为
P{X=xk}=pk,k=1,2,⋯
并且 pk 满足以下两个条件:
- pk≥0,k=1,2,⋯;
- ∑k=1∞pk=1,
则称上式为离散型随机变量 X 的概率分布或分布律。
概率分布也可以用如下的表格来表示:

离散随机变量的分布函数:
F(x)=P{X≤x}=xk≤x∑P{X=xk}=xk≤x∑pk
离散型随机变量 X 的分布函数是一条阶梯形曲线,所有可能取值点为间断点,每个间断点处的跳跃度恰为取该点的概率值。
常用的离散型随机变量
离散型均匀分布:
若随机变量 X 的分布律为
P{X=xk}=n1,k=1,2,⋯,n.
当 i=j时,xi=xj,则称 X 服从离散型均匀分布。
(0-1) 分布:
若随机变量 X 只取 0 与 1 两个值,其概率分布为
P{X=0}=1−p,P{X=1}=p,
其中 0<p<1,则称 X 服从参数为 p 的 (0-1) 分布或两点分布。
分布律也可以写成
P{X=x}=px(1−p)1−x,x=0,1.
二项分布:
在 n 重伯努利试验中,以 X 表示事件 A 发生的次数,所有可能取值为 0,1,2,⋯,n,设 P(A)=p (0<p<1).
若随机变量 X 的分布律为
P{X=k}=Cnkpk(1−p)n−k,k=0,1,2,⋯,n,
其中 0<p<1,则称 X 服从参数为 n,p 的二项分布,记作 X∼B(n,p).
易得
P{X=k}=Cnkpk(1−p)n−k>0,k=0∑nP{X=k}=k=0∑nCnkpk(1−p)n−k=[p+(1−p)]n=1.
特别地,当 n=1 时,二项分布 B(1,p) 就是 (0-1) 分布。
二项分布的最可能取值为
k0={(n+1)p与(n+1)p−1,[(n+1)p]当(n+1)p是整数时当(n+1)p不是整数时
对于任意 j∈X,若 P{X=k}≥P{X=k},则称 k 为最可能出现的次数。记 pk=P{X=k}=Cnkpk(1−p)n−k,考虑
δ=pk−1pk=k(1−p)(n−k+1)p=1+k(1−p)(n+1)p−k≥1
则 k≤(n+1)p.
几何分布:
假设试验只有两个可能的对立结果 A 和 A,且 P(A)=p,P(A)=1−p,将试验独立重复地进行下去,直到 A 发生为止,以 X 表示实验进行的次数,这样得到的分布结果就是几何分布。
若随机变量 X 的分布律为
P{X=k}=(1−p)k−1p,k=1,2,⋯,
其中 0<p<1,则称随机变量 X 服从几何分布,记作 X∼G(p).
易得
(1−p)k−1p>0,k=0∑n(1−p)k−1p=1.
几何分布的无记忆性: 设 X∼G(p),n,m
为任意的两个自然数,则
P{X>n+m∣X>n}=P{X>m}
泊松(Poisson)分布:
如果随机变量 X 的所有可能取值为 0,1,2,⋯,并且
P{x=k}=k!λke−λ,k=0,1,2,⋯,
其中 λ>0 是常数,则称随机变量 X 服从参数为 λ 的泊松分布,记作 X∼P(λ) 或 π(λ).
易得
k!λke−λ>0,k=0∑nk!λke−λ=e−λ⋅eλ=1.
泊松定理: 设 λ>0 是常数,n 为任意正整数,npn=λ,则对任一固定的非负整数 k,有
n→∞limCnkpk(1−pn)n−k=k!λke−λ
泊松定理表明,当 n 很大而 p 很小时,有下面的近似公式
Cnkpk(1−pn)n−k≈k!λke−λ
连续型随机变量及其概率密度
定义: 对于随机变量 X 的分布函数 F(x),如果存在非负函数 f(x),使得对任意的 x,都有
F(x)=∫−∞xf(t)dt,
则称随机变量 X 是连续型随机变量,其中函数 f(x) 叫作 X 的概率密度函数,简称为概率密度,记作 X∼f(x).
由定义可知,连续型随机变量的分布函数处处连续。
概率密度的性质:
性质 1: f(x)≥0.
性质 2: ∫−∞+∞f(x)dx=1.
性质 3: 对于任意实数 a,b (a<b),有
P{a<X≤b}=F(b)−F(a)=∫abf(x)dx.
性质 4: 如果 f(x) 在点 x 处连续,则有
F′(x)=f(x).
性质 5: 对任意实数 a,P{X=a}=0. 即连续型随机变量取任意指定实数的概率均为零,因此有
P{x1<X<x2}=P{x1≤X≤x2}=∫x1x2f(x)dx
几何意义: 概率密度曲线总是位于 x 轴上方,并且介于它和 x 轴之间的面积等于 1;随机变量落在区间 (a,b] 的概率 P{a<X≤b} 等于区间 (a,b] 上曲线 y=f(x) 之下的曲边梯形的面积。
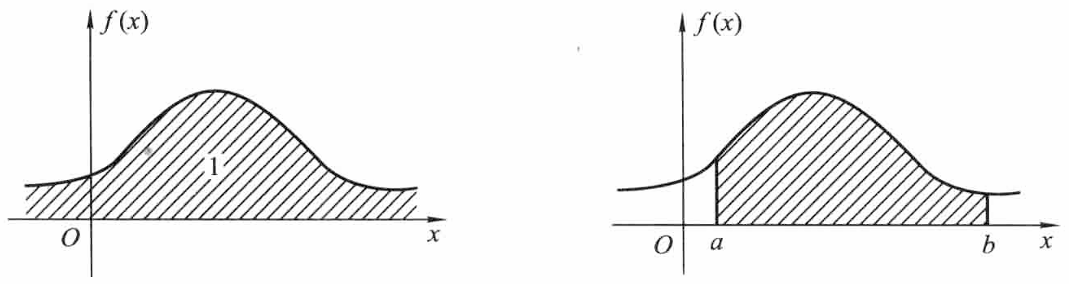
常用的连续型随机变量
均匀分布:
如果连续型随机变量 X 的概率密度为
f(x)=⎩⎨⎧b−a1,0,a<x<b,Other,
则称 X 在区间 (a,b) 上服从均匀分布,记作 X∼U(a,b). X 的分布函数为
F(x)=⎩⎨⎧0,b−ax−a,1,a<x<b,a≤x<b,x≥b.
对于任意 x1,x2∈(a,b),若 x1<x2,则有
P{x1<X<x2}=∫x1x2f(x)dx=∫x1x2b−a1dx=b−ax2−x1.
这说明 X 取值落在 (a,b) 内任一子区间 (x1,x2) 内的概率,只依赖于子区间的长度 x2−x1,与子区间位置无关。
指数分布:
如果连续型随机变量 X 的概率密度为
f(x)={λe−λx,0,x>0,x≤0,
其中 λ>0 为常数,则称 X 服从参数为 λ 的指数分布。X 的分布函数为
F(x)={1−e−λx,0,x>0,x≤0.
指数分布无记忆性,例如:设随机变量 X 服从参数 θ=1 的指数分布,则 P{2<X<3∣X≥1}=P{2<X<3}=e−2−e−3.
正态分布
定义: 如果随机变量 X 具有概率密度
f(x)=2πσ1e−2σ2(x−μ)2,−∞<x<+∞,
其中 μ,σ (σ>0) 为常数,则称 X 服从参数为 μ,σ 的正态分布,记作 X∼N(μ,σ2).
X 的分布函数为
F(x)=2πσ1∫−∞xe−2σ2(t−μ)2dt,−∞<x<+∞,
X 的概率密度及分布函数的图像分别如下图所示:
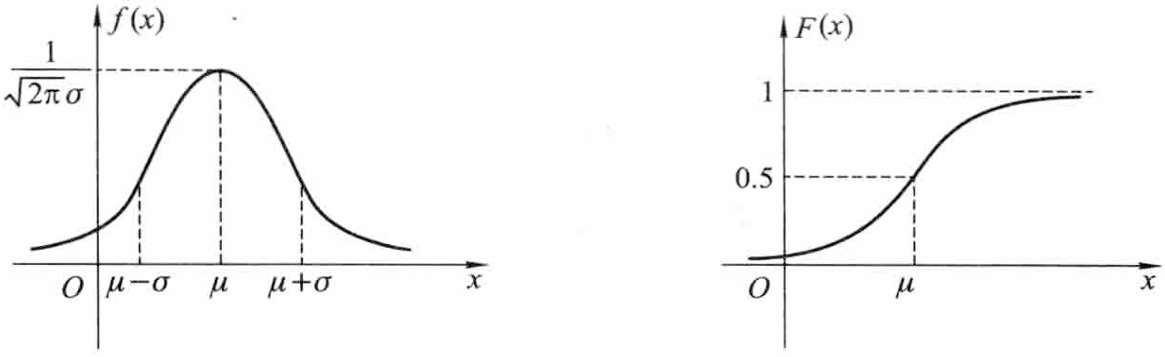
非负性: f(x)≥0.
规范性: ∫−∞+∞2πσ1e−2σ2(x−μ)2dx=1.
正态分布的密度曲线特点:
- 概率密度曲线 y=f(x) 关于直线 x=μ 对称,以 x 轴为水平渐近线,并在 x=μ 处取得最大值 2πσ1;
- 在横坐标 x=μ±σ 处有拐点;
- F(μ)=21.
正态分布的参数:
- 位置参数 μ:如果固定 σ,改变 μ 的值,则概率密度曲线沿着 x 轴平移,但形状不变,如下图所示:
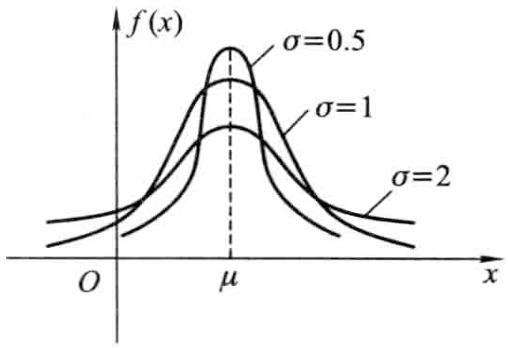
- 形状参数 σ:如果固定 μ,改变 σ 的值,则当 σ 越小时概率密度曲线在 x=μ 附近越陡峭,X 落在 x=μ 附近的概率越大;当 σ 越大时概率密度曲线越平坦。如下图所示:
正态分布的线性函数仍然服从正态分布,即若 X∼N(μ,σ2),则 Y=aX+b∼N(aμ+b,(aσ)2).
证明:X 的概率密度函数为
fX(x)=2πσ1e−2σ2(x−μ)2,−∞<x<+∞
令 y=g(x)=ax+b,由此解得 x=h(y)=ay−b,且 h′(y)=a1.
则 Y=aX+b (a=0) 的概率密度函数为
fY(y)=∣a∣1fX(ay−b),−∞<y<+∞
即
fY(y)=∣a∣2πσ1e−2σ2(ay−b−μ)2=∣a∣2πσ1e−2(aσ)2(y−(b+aμ))2,−∞<x<+∞
因此有
Y=aX+b∼N(aμ+b,(aσ)2)
标准正态分布:
定义: 设 X∼N(μ,σ2),如果 μ=0,σ=1,则称 X 服从标准正态分布,记作 X∼N(0,1).
服从标准正态分布的随机变量 X 的概率密度及分布函数分别记作 φ(x) 与 Φ(x),即
φ(x)=2π1e−2x2,−∞<x<+∞,Φ(x)=2π1∫−∞xe−2t2dt,−∞<x<+∞.
它们的图形分别如下所示:
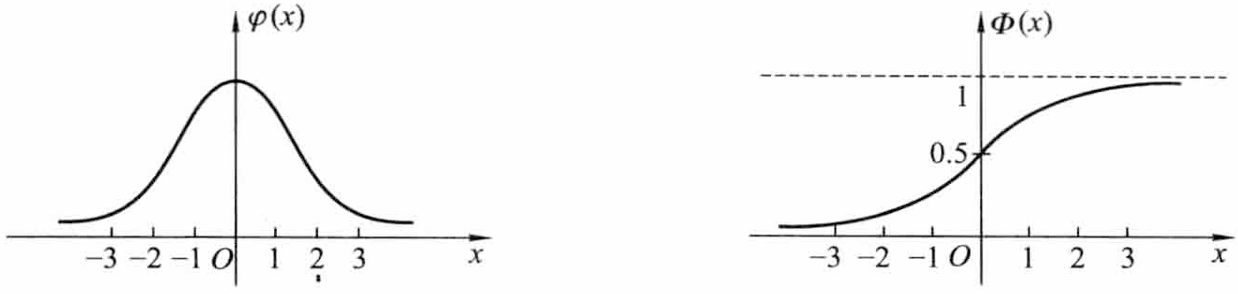
标准正态分布的性质:
- φ(x) 是偶函数,φ(−x)=φ(x),φ(0)=2π1.
- Φ(0)=21,Φ(−x)=1−Φ(x).
- P{∣x∣≤α}=2Φ(a)−1,P{∣x∣>α}=1−P{∣x∣≤α}=2−2Φ(a).
正态分布的标准化: 若 X∼N(μ,σ2),分布函数为 F(x),则令
Y=σX−μ∼N(0,1),F(x)=Φ(σx−μ)
所以有
P{a<X<b}=F(b)−F(a)=Φ(σb−μ)−Φ(σa−μ)=P(σa−μ≤Y≤σb−μ)
设随机变量 X 服从正态分布 N(μ,σ2),则随着 σ2 的增大,概率 P{∣X−μ∣<σ} 保持不变。
证:令 Y=σX−μ,因为 X∼N(μ,σ2),故 Y∼N(0,1),从而有 P{∣X−μ∣<σ}=P{∣Y∣<1} 是一个固定值。
标准正态分布上的 α 分位点:
定义: 设 X∼N(0,1). 对于给定的 α (0<α<1),如果 uα 满足条件
P{X≥uα}=2π1e−2x2dx=α,
则称点 uα 为标准正态分布的上 α 分位点。
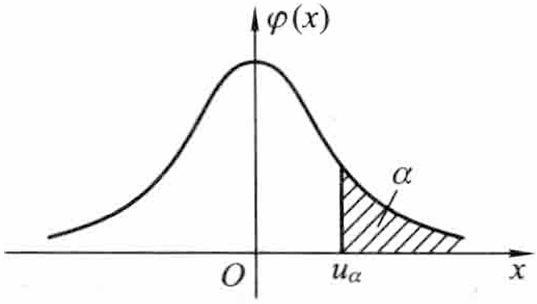
Φ(uα)=1−α,−uα=u1−α.
常用数据:u0.05=1.645,u0.025=1.96.
随机变量函数的分布
设 X 是随机变量,函数 y=g(x),如果 Y=g(x),Y 是随机变量 X 的函数。已知 X 的分布,考虑 Y 的分布。
方法:将与 Y 有关的事件转化成与 X 有关的事件。
离散型随机变量的函数的分布: 确定随机变量 Y=g(X) 的所有可能取值及相应概率,遇到多个 X 取值造成同一个 Y 值,则将对应概率加和。
连续型随机变量的函数的分布: 设 X 为连续型随机变量,其概率密度为 fX(x),又 Y=g(X),且 Y 也是连续型随机变量,求 Y 的概率密度 fY(y).
方法一(分布函数法):先借助 X 分布函数表达 Y 的分布函数 FY(y),再对 y 求导,得 Y 的概率密度函数
fY(y)=⎩⎨⎧dydFY(y),0,可导,不可导.
方法二(公式法):连续型随机变量 X 的概率密度 fX(x) (−∞<x<+∞),函数 g(x) 是处处可导的单调函数,则随机变量 Y=g(X) 的概率密度为
fY(y)={fX(h(y))∣h′(y)∣,0,α<y<β,else,
其中 α=min{g(−∞),g(+∞)},β=max{g(−∞),g(+∞)},h(y) 是 g(x) 的反函数。
当 f(x) 在有限区间 [a,b] 外为 0 时,只需考虑 g(x) 在区间内是否单调可导。
例(对数正态分布):如果 Y=lnX 服从正态部分 N(μ,σ2),则称随机变量 X 为服从参数为 μ,σ2 的对数正态分布。求对数正态分布的概率密度。
解:由 X=eY,Y=lnX∼N(μ,σ2),
当 x>0 时,
FX(x)=P{X≤x}=P{eY≤x}=P{Y≤lnx}=FY(lnx)
当 x≤0 时,FX(x)=0.
综上所述,
fx(x)=FX′(x)=⎩⎨⎧x1fY(lnx),0,x>0,x≤0,=⎩⎨⎧2πσx1e−2σ2(lnx−μ)2,0,x>0,x≤0.
二维随机变量及其分布
二维随机变量及其分布函数
定义 1: 设随机试验 E 的样本空间为 Ω,X 和 Y 是定义在 Ω 上的两个随机变量,由它们构成的向量 (X,Y) 称为二维随机变量或二维随机向量。
定义 2: 设 (X,Y) 是二维随机变量。对于任意实数 x 和 y,记事件 {X≤x} 与 {Y≤y} 的交事件为 {X≤x,Y≤y},称二元函数
F(x,y)=P{X≤x,Y≤y},(x,y)∈R2
为二维随机变量 (X,Y) 的分布函数,或称为随机变量 X 和 Y 的联合分布函数。
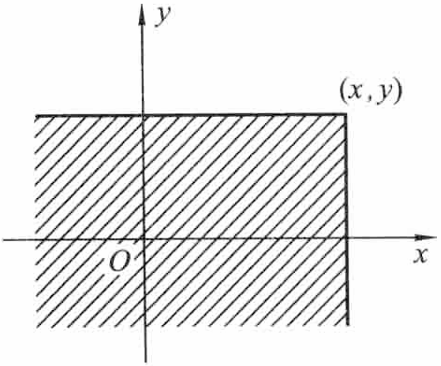
几何意义: 如果我们将二维随机变量 (X,Y) 看作 xOy 平面上随机点的坐标,则分布函数 F(x,y) 在点 (x,y) 处的函数值就是随机点落在以 (x,y) 为顶点且位于该点左下方的无界域内的概率,如下图所示
分布函数 F(x,y) 具有以下性质:
性质 1: 0≤F(x,y)≤1,且
F(−∞,−∞)=y→−∞x→−∞lim(x,y)=0F(+∞,+∞)=y→+∞x→+∞lim(x,y)=1
对于任意固定的 x,有 F(x,−∞)=y→−∞lim(x,y)=0;
对于任意固定的 y,有 F(−∞,y)=x→−∞lim(x,y)=0.
性质 2: F(x,y) 对于每个变量是单调不减函数,即对于任意固定的 y,当 x1<x2 时,有
F(x1,y)≤F(x2,y)
对于任意固定的 x,当 y1<y2 时,有
F(x,y1)≤F(x,y2)
性质 3: F(x,y) 关于 x 右连续,关于 y 右连续,即有
F(x+,y)=F(x,y),F(x,y+)=F(x,y)
性质 4: 对于任意的 x1<x2,y1<y2,有
P{x1<X≤x2,y1<Y≤y2}=F(x2,y2)−F(x1,y2)−F(x2,y1)+F(x1,y1).
该公式用于利用分布函数计算概率。
边缘分布
定义: 设二维随机变量 (X,Y) 的分布函数为 F(x,y),记随机变量 X 的分布函数为 FX(x),随机变量 Y 的分布函数为 FY(y),分别称为二维随机变量 (X,Y) 关于 X 和关于 Y 的边缘分布函数。
我们有
FX(x)=P{X≤x}=P{X≤x,Y<+∞}=F(x,+∞),x∈R,FY(x)=P{Y≤y}=P{X<+∞,Y≤y}=F(+∞,y),y∈R.
二维随机变量 (X,Y) 的边缘分布函数完全由联合分布函数 F(x,y) 确定;但是,一般地,由边缘分布函数不能确定联合分布函数。
二维随机变量的独立性
定义: 设二维随机变量 (X,Y) 的分布函数及其关于 X 和关于 Y 的边缘分布函数为 F(x,y),Fx(x),FY(y),如果对于任意实数 x,y,都有
F(x,y)=FX(x)FY(y)
则称随机变量 X 与 Y 是相互独立的。
X 与 Y 相互独立就是对 ∀x,y∈R,两事件 {X≤x} 和 {Y≤y} 相互独立。
若 X 与 Y 相互独立,对任意连续函数 h,g,则 h(X) 与 g(Y) 也相互独立。
二维离散型随机变量及其概率分布
定义 1: 若二维随机变量 (X,Y) 所有可能取得值是有限对或可列无限对,则称 (X,Y) 是二维离散型随机变量。
设 (X,Y) 所有可能取的值为 (xi,yj) (i,j=1,2,⋯),记事件 {X=xi} 与事件 {Y=yj} 的交事件为 {X=xi,Y=yj} (i,j=1,2,⋯).
定义 2: 设 (X,Y) 所有可能取的值为 (xi,yj) (i,j=1,2,⋯),如果
P{X=xi,Y=yj}=pij,i,j=1,2,⋯,
且满足
- pij≥0, (i,j=1,2,⋯);
- ∑i=1∞∑j=1∞pij=1,
则称上式为二维离散型随机变量 (X,Y) 的概率分布,或称为随机变量 X 和随机变量 Y 的联合概率分布或联合分布律。
(X,Y) 的概率分布可以用如下的表格表示:
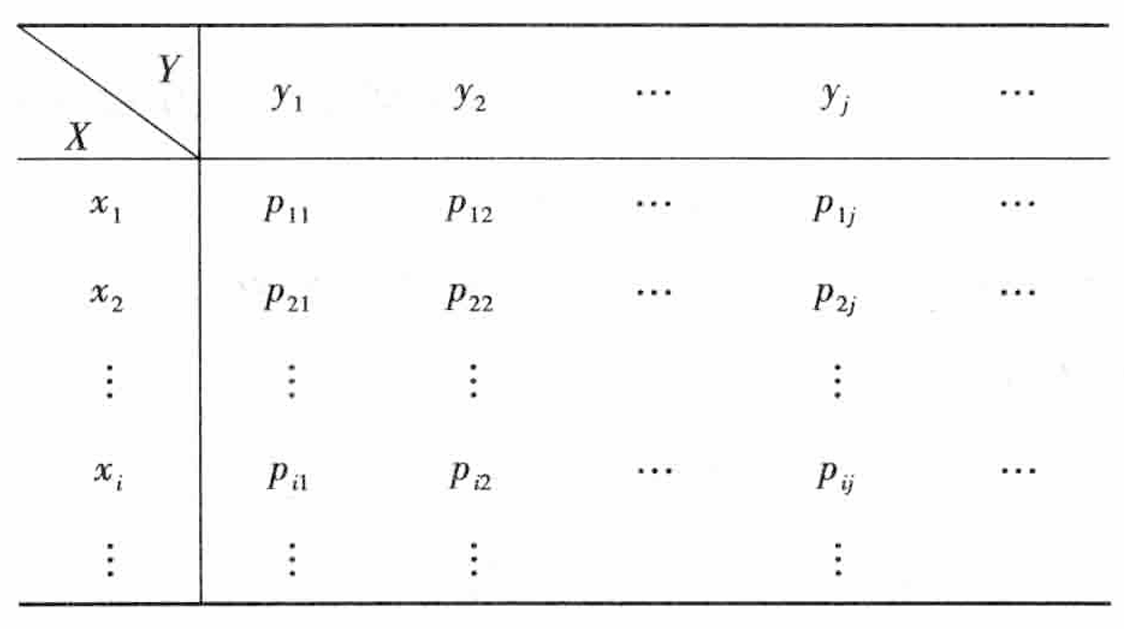
边缘概率分布: 设二维离散型随机变量 (X,Y) 的概率分布为
P{X=xi,Y=yj}=pij,i,j=1,2,⋯
随机变量 X 和 Y 的概率分布
P{X=xi}=pi⋅,i=1,2,⋯,P{Y=yj}=p⋅j,j=1,2,⋯,
分别称为 (X,Y) 关于 X 和关于 Y 的边缘概率分布或边缘分布律。
边缘分布律都是一维随机变量的分布;联合分布律可确定边缘分布律,反之不一定。
随机变量的独立性: 设二维离散型随机变量 (X,Y),X 与 Y 相互独立的充要条件是对任意的 i,j,都有
P{X=xi,Y=yj}=P{X=xi}P{Y=yj},i,j=1,2,⋯,
即
pij=pi⋅p⋅ji,j=1,2,⋯.
二维连续型随机变量及其概率密度
定义: 设二维随机变量 (X,Y) 的分布函数为 F(x,y),如果存在非负的二元函数 f(x,y),对于任意实数 x,y,有
F(x,y)=∫−∞x∫−∞yf(u,v)dudv
则称 (X,Y) 为二维连续型随机变量,f(x,y) ((x,y)∈R2) 称为二维连续型随机变量 (X,Y) 的概率密度,或称为随机变量 X 和 Y 的联合概率密度。
概率密度 f(x,y) 具有下列性质:
性质 1: f(x,y)≥0.
性质 2: ∫−∞+∞∫−∞+∞f(x,y)dxdy=1.
性质 3: 如果 f(x,y) 在点 (x,y) 处连续,则
f(x,y)=∂x∂y∂2F(x,y).
性质 4: 设 G 是 xOy 面上的一个区域,则
P{(X,Y)∈G}=∬Gf(x,y)dxdy.
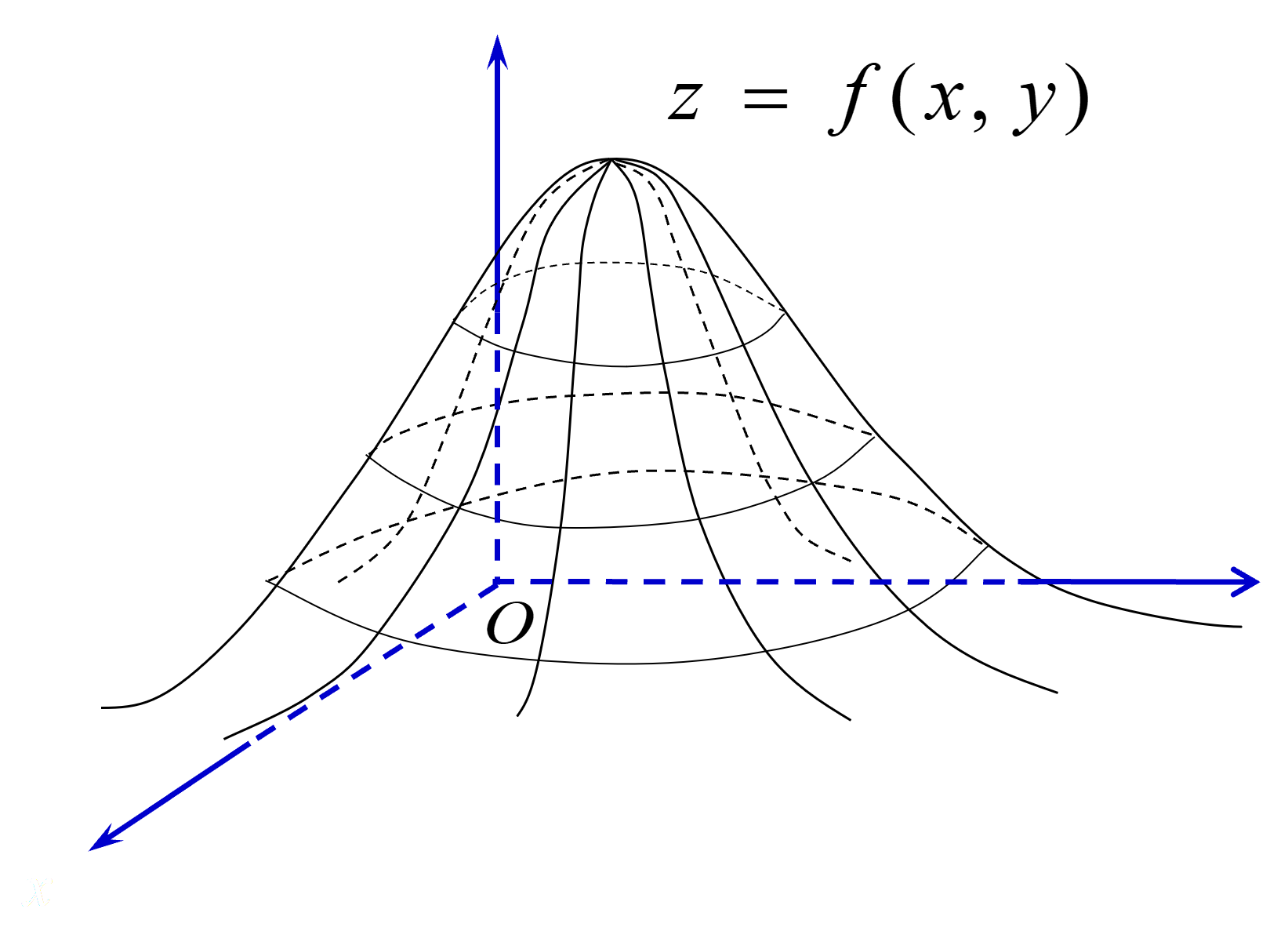
几何意义: z=f(x,y) 表示空间 Oxyz 中的一张曲面。性质 1 和性质 2 表明,曲面 z=f(x,y) 位于 xOy 平面上方,介于它和 xOy 平面之间的体积为 1. 性质 4 表明,随机点 (X,Y) 落在区域 G 内的概率 P{(X,Y)∈G} 等于以 G 为底、以曲面 z=f(x,y) 为顶的曲顶柱体体积的数值。
边缘概率密度: 设二维连续型随机变量 (X,Y) 的概率密度为 f(x,y),(x,y)∈R2,将一元函数
fX(x)=∫−∞+∞f(x,y)dy,x∈R,fY(y)=∫−∞+∞f(x,y)dx,y∈R
分别称为二维随机变量 (X,Y) 关于 X 和关于 Y 的边缘概率密度。
随机变量的独立性: 设二维连续型随机变量 (X,Y),X 与 Y 相互独立的充要条件是对任意实数 x,y,都有
f(x,y)=fX(x)fY(y),(−∞<x,y<+∞).
二维均匀分布与正态分布
二维均匀分布:
设 D 是 xOy 面上的有界区域,其面积为 A. 如果二维随机变量 (X,Y) 具有概率密度
f(x,y)=⎩⎨⎧A1,0,(x,y)∈D,else,
则称 (X,Y) 在区域 D 上服从均匀分布。
例:设二维随机变量 (X,Y) 在区域 D={(x,y)∣0≤y≤x,0≤x≤1} 上服从均匀分布。
(1)求 (X,Y) 的概率密度。
解:区域 D 的面积为 S=21,故 (X,Y) 的概率密度为
f(x,y)={2,0,(x,y)∈D,else.
(2)求 P{21<X<43,0<Y<43}.
P{21<X<43,0<Y<43}=梯形∬f(x,y)dxdy=∫2143dx∫ox2dy=165
二维正态分布:
设二维随机变量 (X,Y) 的概率密度为
f(x,y)=2πσ1σ21−ρ21⋅exp{2(1−ρ2)−1[σ12(x−μ1)2−2ρσ1σ2(x−μ1)(y−μ2)+σ22(y−μ2)2]},(x,y)∈R2
其中 μ1,μ2,σ1,σ2,ρ 都是常数,且 σ1>0,σ2>0,−1<ρ<1,则称 (X,Y) 服从参数为 μ1,μ2,σ1,σ2,ρ 的二维正态分布,记作 (X,Y)∼N(μ1,μ2,σ12,σ22,ρ).
二维正态分布的性质:
- 若 (X,Y)∼N(μ1,μ2,σ12,σ22,ρ),则 X∼N(μ1,σ12),Y∼N(μ2,σ22),即二维正态分布的边缘分布式一维正态分布。
只要给定二维正态分布的前 4 个参数,关于 X 和关于 Y 的边缘分布也就确定了,和 ρ 无关。
- X 和 Y 相互独立的充要条件是 ρ=0.
独立正态随机变量的非零线性组合仍服从正态分布,例如若 X,Y 相互独立,X∼N(μ1,σ12),Y∼N(μ2,σ22),则
- X+Y∼N(μ1+μ2,σ12+σ22);
- aX+bY∼N(aμ1+bμ2,a2σ12+b2σ22);
- X−Y∼N(μ1−μ2,σ12+σ22).
条件分布
离散型随机变量的条件分布: 设 (X,Y) 是二维离散型随机变量,对于固定的 j,如果 P{Y=yj}=p⋅j>0,则称
P{X=xi∣Y=yj}=P{Y=yj}P{X=xi,Y=yj}=p⋅jpij,i=1,2,⋯
为在条件 Y=yj 下随机变量 X 的条件概率分布。对于固定的 i,若 pi⋅>0,则称
P{Y=yj∣X=xi}=P{X=xi}P{X=xi,Y=yj}=pi⋅pij,j=1,2,⋯
为在条件 X=xi 下随机变量 Y 的条件概率分布。
连续型随机变量的条件分布:
在 Y=y 条件下,X 的条件概率密度为
fX∣Y(x∣y)=fY(y)f(x,y)
X 的条件分布函数为
FX∣Y(x∣y)=∫−∞xfX∣Y(x∣y)dx
在 X=x 条件下,Y 的条件概率密度为
fY∣X(y∣x)=fX(x)f(x,y)
Y 的条件分布函数为
FY∣X(y∣x)=∫−∞yfY∣X(y∣x)dy
二维随机变量的函数的分布
设 (X,Y) 为二维随机变量,g(x,y) 为二元函数,则一维随机变量 Z=g(X,Y) 是二维随机变量 (X,Y) 的函数。
二维离散型随机变量的函数的分布:
如果 X 与 Y 相互独立,则有
X∼P(λ1),Y∼P(λ2)⇒X+Y∼P(λ1+λ2)X∼B(m,p),Y∼B(n,p)⇒X+Y∼B(m+n,p)
二维连续型随机变量的函数的分布:
已知 (X,Y) 概率密度,求 Z=g(X,Y) 的概率密度。
1. 一般情形:
- 先求随机变量 Z 的分布函数
FZ(z)=P{Z≤z}=P{g(X,Y)≤z}=g(x,y)≤z∬f(x,y)dxdy
- 对 FZ(z) 求导,得 Z 的概率密度函数为
fZ(z)=FZ′(z)
2. Z=X+Y 的概率密度:
fZ(z)=∫−∞+∞f(z−y,y)dy
或
fZ(z)=∫−∞+∞f(x,z−x)dx
若 X,Y 相互独立,则 Z=X+Y 的密度函数为
fZ(z)=∫−∞+∞fX(z−y)fY(y)dy
或
fZ(z)=∫−∞+∞fX(x)fY(z−x)dy
上式称为卷积公式。
3. X 与 Y 相互独立,M=maxX,Y 的分布函数:
Fmax(z)=P{M≤z}=P{X≤z,Y≤z}=P{X≤z}P{Y≤z}=FX(z)FY(z)
4. X 与 Y 相互独立,N=minX,Y 的分布函数:
Fmin(z)=P{N≤z}=1−P{N>z}=1−P{X>z,Y>z}=1−P{X>z}P{Y>z}=1−[1−P{X≤z}][1−P{Y≤z}]=1−[1−FX(z)][1−FY(z)]
推广: 设 n 个随机变量 X1,X2,⋯,Xn 相互独立,分布函数分别为 FX1(x1),FX2(x2),⋯,FXn(xn),则 M=max{X1,X2,⋯,Xn} 的分布函数为
Fmax(z)=FX1(z)FX2(z)⋯FXn(z)
N=min{X1,X2,⋯,Xn} 的分布函数为
Fmin(z)=1−[1−FX1(z)][1−FX2(z)]⋯[1−FXn(z)]
随机变量的数字特征
数学期望
数学期望是一个常数,它是一种加权平均,表示随机变量所有取值的平均值,具有重要的统计意义。
定义: 设离散型随机变量 X 的概率分布为 P{X=xk}=pk,k=1,2,⋯,如果无穷级数 ∑k=1∞xkpk 绝对收敛,则称无穷级数 ∑k=1∞xkpk 的和为离散型随机变量 X 的数学期望或均值,记作 E(X) 或 EX,即
E(X)=k=1∑∞xkpk.
设连续型随机变量 X 的概率密度为 f(x),如果反常积分 ∫−∞+∞xf(x)dx 绝对收敛,则称 ∫−∞+∞xf(x)dx 的值为连续型变量 X 的数学期望或均值,即
E(X)=∫−∞+∞xf(x)dx.
随机变量的函数的数学期望:
定理 1: 设随机变量 Y 是随机变量 X 的函数:Y=g(X),其中 g 是一元连续函数。
- 若 X 是离散型随机变量,其概率分布为 P{X=xk}=pk,k=1,2,⋯,如果无穷级数 ∑k=1∞xkpk 绝对收敛,则随机变量 Y 的数学期望为
E(Y)=E[g(X)]=k=1∑∞g(xk)pk
- 若 X 是连续型随机变量,其概率分布为 f(x),如果反常积分 ∫−∞+∞g(x)f(x)dx 绝对收敛,则随机变量 Y 的数学期望为
E(Y)=E[g(X)]=∫−∞+∞g(x)f(x)dx
根据这一定理求随机变量 Y=g(X) 的数学期望时,只需直到 X 的分布,无需求出 Y 的分布。
定理 2: 设 Z 是随机变量 X 和 Y 的函数:Z=g(X,Y),其中 g 是二元连续函数。
- 设 X,Y 的联合分布律为 P{X=xi,Y=yj}=pij,i,j=1,2,⋯,如果 ∑i=1∞∑j=1∞g(xi,yj)pij 绝对收敛,则
E(Z)=E[g(X,Y)]=j=1∑∞i=1∑∞g(xi,yj)pij
- 设 X,Y 的联合概率密度为 f(x,y),如果广义积分 ∫−∞+∞∫−∞+∞g(x,y)f(x,y)dxdy 绝对收敛,则
E(Z)=E[g(X,Y)]=∫−∞+∞∫−∞+∞g(x,y)f(x,y)dxdy
数学期望的性质:
性质 1: 设 c 为常数,E(c)=c.
性质 2: 设 c 为常数,E(cX)=cE(X).
性质 3: E(X±Y)=E(X)±E(Y).
性质 4: 若 X,Y 相互独立,则 E(XY)=E(X)E(Y).
性质 5(柯西-施瓦茨不等式): 设随机变量 X,Y,若 E(X2) 和 E(Y2) 都存在,则
[E(XY)]2≤E(X2)E(Y2).
方差
在许多问题中,除了要直到随机变量的均值外,还要研究随机变量与其均值之间的偏离程度,因此引入了方差的概念。
定义: 设 X 是一个随机变量,如果 E{[X−E(X)]2} 存在,则称之为随机变量 X 的方差,记作 D(X) 或 DX,即
D(X)=E{[X−E(X)]2}.
称 D(X) 为随机变量 X 的标准差或均方差,记作 σ(X),即
σ(X)=D(X).
随机变量 X 的方差反映了 X 与其数学期望 E(X) 的偏离程度。如果 X 取值集中在 E(X) 附近,则 D(X) 较小;如果 X 取值比较分散,则 D(X) 较大。
离散型随机变量:
D(X)=k=1∑∞[xk−E(X)]2pk
连续型随机变量:
D(X)=∫−∞+∞[x−E(X)]2f(x)dx
方差的性质:
性质 1: 设 c 为常数,则 D(c)=0.
性质 2: D(cX)=c2D(X)
性质 3: D(X+c)=D(X)
性质 4: 若 X 与 Y 相互独立,则 D(X±Y)=D(X)+D(Y).
性质 5: 随机变量 X 的方差 D(X)=0 的充分必要条件是 X 以概率 1 取常数 C=E(X),即 P{X=C}=1.
常见分布的数学期望与方差:
| 分布 |
数学期望 |
方差 |
| (0-1)分布 |
p |
p(1−p) |
| 二项分布 B(n,p) |
np |
np(1−p) |
| 泊松分布 P(λ) |
λ |
λ |
| 几何分布 |
1/p |
(1−p)/p2 |
| 均匀分布 U(a,b) |
(a+b)/2 |
(b−a)2/12 |
| 正态分布 N(μ,σ2) |
μ |
σ2 |
| 指数分布 E(λ) |
1/λ |
1/λ2 |
随机变量的标准化: 设随机变量 X 具有数学期望 E(X)=μ 及方差 D(X)=σ2>0,则称
X∗=σX−μ
为 X 的标准化随机变量。
显然,E(X∗)=0,D(X∗)=1.
若 X∼N(μ,σ2) (σ>0),则
X∗=σX−μ∼N(0,1).
协方差与相关系数
定义: 设随机变量 X 和 Y 的数学期望 E(X) 和 E(Y) 都存在,称 E{[X−E(X)][Y−E(Y)]} 为 X 与 Y 的协方差,记作
Cov(X,Y)=E{[X−E(X)][Y−E(Y)]}
将上式展开,易得
Cov(X,Y)=E(XY)−E(X)E(Y)
这是常用的协方差计算公式。
Cov(X,X)=D(X)
协方差的性质:
性质 1: Cov(X,Y)=Cov(Y,X)
性质 2: Cov(aX,bY)=abCov(X,Y)
性质 3: Cov(X+Y,Z)=Cov(X,Z)+Cov(Y,Z)
性质 4: D(X±Y)=D(X)+D(Y)±2Cov(X,Y)
定义: 设随机变量 X 和 Y 的方差都存在且不等于零,协方差 Cov(X,Y) 存在,称
ρXY=D(X)D(Y)Cov(X,Y)
为 X,Y 的相关系数。当 ρXY=0 时,称 X 与 Y 不相关。
相关系数的常用计算公式为
ρXY=D(X)D(Y)E(XY)−E(X)E(Y).
相关系数的性质:
性质 1: ∣ρXY∣≤1
性质 2: 如果 X 和 Y 相互独立,则 ∣ρXY∣=0.
性质 3: ∣ρXY∣=1 的充分必要条件是:存在常数 a,b,使得
P{Y=a+bX}=1.
相关系数的含义: 相关系数表示了随机变量 X 和 Y 的线性相关的程度:
- 当 ∣ρXY∣=1 时,X,Y 几乎就是线性关系;
- 当 ∣ρXY∣ 较大时,X,Y 的线性关系较为密切;
- 当 ∣ρXY∣ 较小时,X,Y 的线性关系较弱;
- 当 ρXY=0 时,X,Y 之间没有线性关系(不相关)。
若 ρXY>0,则 X,Y 正相关;若 ρXY<0,则 X,Y 负相关。
对于随机变量 X,Y,以下命题等价:
- Cov(X,Y)=0;
- X 与 Y 不相关;
- E(XY)=E(X)E(Y);
- D(X+Y)=D(X)+D(Y).
这里假设上述命题中出现的数字特征都是存在的。
二维正态分布的结论: 如果 (X,Y)∼N(μ1,μ2,σ12,σ22,ρ),则
- ρ=ρXY;
即二维正态随机变量 (X,Y) 的分布完全由 X 与 Y 的数学期望,方差以及 X 与 Y 的相关系数所确定。
-
X 与 Y 相互独立 ⟺ X 与 Y 不相关;
-
Cov(X,Y)=ρσ1σ2.
矩
定义: 对于随机变量 X,Y,
- 称 E(Xk)=μk (k=1,2,⋯) 为 X 的 k 阶原点矩;
- 称 E{[X−E(X)]k} 为 X 的 k 阶中心矩;
- 称 E(XkYl) (k,l=1,2,⋯) 为 X 和 Y 的 k+l 阶混合原点矩;
- 称 E{[X−E(X)]k[Y−E(Y)]l} 为 X 和 Y 的 k+l 阶混合中心矩。
显然,随机变量 X 的数学期望 E(X) 是 X 的一阶原点矩,方差 D(X) 是 X 的二阶中心矩,随机变量 X 和 Y 的协方差 Cov(X,Y) 是 X 和 Y 的二阶混合中心矩。
协方差矩阵:
对于二维随机变量 (X1,X2),记
c11c12c21c22=E{(X1−EX1)2}=D(X1)=E{(X1−EX1)(X2−EX2)}=Cov(X1,X2)=E{(X2−EX2)(X1−EX1)}=Cov(X2,X1)=E{(X2−EX2)2}=Cov(X2,X1)
如果它们都存在,写成矩阵的形式
C=[c11c21c12c22]
称此矩阵为二维随机变量 (X1,X2) 的协方差矩阵。
设 n 维随机变量 (X1,X2,⋯,Xn) 关于 X1,X2,⋯,Xn 的二阶中心矩和二阶混合中心矩
cij=E{[Xi−E(Xi)][Xj−E(Xj)]},i,j=1,2,⋯,n
都存在,则称矩阵
C=c11c21⋮cn1c12c22⋮cn2⋯⋯⋱⋯c1nc2n⋮cnn
为 n 维随机变量 (X1,X2,⋯,Xn) 的协方差矩阵。由于 cij=cji (i=j,i,j=1,2,⋯,n),所以 C 是对称矩阵。
二维正态分布的矩阵表达式: 设 (X,Y)∼N(μ1,μ2,σ12,σ22,ρ),密度函数也表示为
f(x,y)=(2π)2/2∣C∣1/21exp{−21(X−μ)TC−1(X−μ)}
其中 C=[σ12ρσ1σ2ρσ1σ2σ22] 为协方差矩阵,行列式为
∣C∣=σ12σ22(1−ρ2)
并且
C−1=∣C∣1[σ22−ρσ1σ2−ρσ1σ2σ12],X=[xy],μ=[μ1μ2]
n 维正态随机变量的性质:
-
n 维随机变量 (X1,X2,⋯,Xn) 服从 n 维正态分布的充分必要条件是:X1,X2,⋯,Xn 的任意线性组合
k1X1+k2X2+⋯+knXn
都服从一维正态分布,其中 k1,k2,⋯,kn 是不全为零的常数。
-
设 (X1,X2,⋯,Xn) 服从 n 维正态分布,如果 Y1,Y2,⋯,Ym 是 Xi (i=1,2,⋯,n) 的线性函数,则 Y1,Y2,⋯,Ym 也服从多维正态分布。
-
如果 (X1,X2,⋯,Xn) 服从 n 维正态分布,则 “随机变量 X1,X2,⋯,Xn 相互独立” 与 “X1,X2,⋯,Xn 两两不相关” 等价。
大数定律与中心极限定理
切比雪夫不等式
定理: 设随机变量 X 具有数学期望 E(X)=μ 和方差 D(X)=σ2,则对于任意给定的整数 ε,有
P{∣X−E(X)∣≥ε}≤ε2D(X)
这一不等式称为切比雪夫(Chebyshev)不等式,它的等价形式是
P{∣X−E(X)∣<ε}≥1−ε2D(X)
大数定律
定义: 设 X1,X2,⋯,Xn,⋯ 是一个随机变量序列,a 是一个常数。如果对于任意给定的正数 ε,有
n→∞limP{∣Xn−a∣<ε}=1
则称随机变量序列 X1,X2,⋯,Xn,⋯ 依概率收敛于 a,记作 Xn→Pa.
性质: 设 Xn→Pa,Yn→Pb,函数 g(x,y) 在点 (a,b) 连续,则 g(Xn,Yn)→Pg(a,b).
切比雪夫大数定律: 设 X1,X2,⋯,Xn,⋯ 是相互独立的随机变量序列,具有数学期望 E(Xk) 及方差 D(Xk),且方差一致有上界,即存在正数 M 使得 D(Xk)≤M. 则对任意给定的正数 ε,恒有
n→∞limP{n1k=1∑nXk−n1k=1∑nE(Xk)<ε}=1
当 n 充分大时,n1∑i=1nXi 差不多不再是随机的了,取值接近于其数学期望的概率接近于 1.
伯努利大数定理: 设 nA 是 n 次独立重复试验中事件 A 发生的次数,p 是事件 A 在每次试验中发生的概率,则对任给的正数 ε,有
n→∞limP{nnA−p<ε}=1
等价形式:
n→∞limP{nnA−p≥ε}=0
伯努利定理表明,当 n 充分大时,事件 A 在 n 次独立重复试验中发生的频率 nnA 依概率收敛于其发生的概率 p.
辛钦(Khintchine)大数定理: 设 X1,X2,⋯,Xn,⋯ 是相互独立的随机变量序列,服从同一分布,具有数学期望 E(Xk)=μ,k=1,2,⋯,则对任意给定的正数 ε,有
n→∞limP{n1k=1∑nXk−μ<ε}=1
中心极限定理






