一篇文章学完 Effective C++:条款 & 实践
虽然笔者和 C++ 结识已经很长时间了,但一直没有阅读过这本久负盛名的著作 Effective C++,在此,我将结合自己对 Modern C++ 的理解,记录自己的阅读笔记,并且将内容以条款 & 实践的方式呈现,以求更加清晰的理解。
第一章:让自己习惯 C++
条款 1:视 C++ 为一个语言联邦
C++ 拥有多种不同的编程范式,而这些范式集成在一个语言中,使得 C++ 是一门即灵活又复杂的语言:
- 传统的面向过程 C:区块,语句,预处理器,内置数据类型,数组,指针。
- 面向对象的 C with Classes:类,封装,继承,多态,动态绑定。
- 模板编程 Template C++ 和堪称黑魔法的模板元编程(TMP)。
- C++ 标准库 STL。
C++ 高效编程守则视情况而变化,程序设计没有银弹。
条款 2:尽量以 const, enum, inline 替换 #define
在原书写成时 C++11 中的constexpr还未诞生,现在一般认为应当用constexpr定义编译期常量来替代大部分的#define宏常量定义:
1 |
替代为:
1 | constexpr auto aspect_ratio = 1.653; |
我们也可以将编译期常量定义为类的静态成员:
1 | class GamePlayer { |
enum可以用于替代整型的常量,并且在模板元编程中应用广泛(见条款 48):
1 | class GamePlayer { |
大部分#define宏常量应当用内联模板函数替代:
1 |
替代为:
1 | template<typename T> |
需要注意的是,宏和函数的行为本身并不完全一致,宏只是简单的替换,并不涉及传参和复制。
条款 3:尽可能使用 const
若你想让一个常量只读,那你应该明确说出它是const常量,对于指针来说,更是如此:
1 | char greeting[] = "Hello"; |
对于 STL 迭代器,分清使用const还是const_iterator:
1 | const std::vector<int>::iterator iter = vec.begin(); // 迭代器不可修改,数据可修改 |
面对函数声明时,如果你不想让一个函数的结果被无意义地当作左值,请使用const返回值:
1 | const Rational operator*(const Rational& lhs, const Rational& rhs); |
const成员函数:
const成员函数允许我们操控const对象,这在传递常引用时显得尤为重要:
1 | class TextBlock { |
这样,const和non-const对象都有其各自的重载版本:
1 | void Print(const Textblock& ctb) { |
编译器对待const对象的态度通常是 bitwise constness,而我们在编写程序时通常采用 logical constness,这就意味着,在确保客户端不会察觉的情况下,我们认为const对象中的某些成员变量应当是允许被改变的,使用关键字mutable来标记这些成员变量:
1 | class CTextBlock { |
在重载const和non-const成员函数时,需要尽可能避免书写重复的内容,这促使我们去进行常量性转除。在大部分情况下,我们应当避免转型的出现,但在此处为了减少重复代码,转型是适当的:
1 | class TextBlock { |
需要注意的是,反向做法:令const版本调用non-const版本以避免重复——并不被建议,一般而言const版本的限制比non-const版本的限制更多,因此这样做会带来风险。
条款 4:确定对象在使用前已被初始化
无初值对象在 C/C++ 中广泛存在,因此这一条款就尤为重要。在定义完一个对象后需要尽快为它赋初值:
1 | int x = 0; |
对于类中的成员变量而言,我们有两种建议的方法完成初始化工作,一种是直接在定义处赋初值(since C++11):
1 | class CTextBlock { |
另一种是使用构造函数成员初始化列表:
1 | ABEntry::ABEntry(const std::string& name, const std::string& address, |
成员初始化列表也可以留空用来执行默认构造函数:
1 | ABEntry::ABEntry() |
需要注意的是,类中成员的初始化具有次序性,而这次序与成员变量的声明次序一致,与成员初始化列表的次序无关。
类中成员的初始化是可选的,但是引用类型必须初始化。
静态对象的初始化:
C++ 对于定义于不同编译单元内的全局静态对象的初始化相对次序并无明确定义,因此,以下代码可能会出现使用未初始化静态对象的情况:
1 | // File 1 |
在上面这个例子中,你无法确保位于不同编译单元内的tfs一定在tempDir之前初始化完成。
这个问题的一个有效解决方案是采用 Meyers’ singleton,将全局静态对象转化为局部静态对象:
1 | FileSystem& tfs() { |
这个手法的基础在于:C++ 保证,函数内的局部静态对象会在该函数被调用期间和首次遇上该对象之定义式时被初始化。
当然,这种做法对于多线程来说并不具有优势,最好还是在单线程启动阶段手动调用函数完成初始化。
第二章:构造/析构/赋值运算
条款 5:了解 C++ 默默编写并调用哪些函数
C++ 中的空类并不是真正意义上的空类,编译器会为它预留以下内容:
1 | class Empty { |
唯有当这些函数被调用时,它们才会真正被编译器创建出来,下面代码将造成上述每一个函数被创建:
1 | Empty e1; // 默认构造函数 & 析构函数 |
需要注意的是,拷贝赋值运算符只有在允许存在时才会自动创建,比如以下情况:
1 | class NamedObject { |
在该类中,我们有一个string引用类型,然而引用无法指向不同对象,因此编译器会拒绝为该类创建一个默认的拷贝赋值运算符。
除此之外,以下情形也会导致拷贝赋值运算符不会自动创建:
- 类中含有const成员。
- 基类中含有private的拷贝赋值运算符。
条款 6:若不想使用编译器自动生成的函数,就该明确拒绝
原书中使用的做法是将不想使用的函数声明为private,但在 C++11 后我们有了更好的做法:
1 | class Uncopyable { |
条款 7:为多态基类声明虚析构函数
当派生类对象经由一个基类指针被删除,而该基类指针带着一个非虚析构函数,其结果是未定义的,可能会无法完全销毁派生类的成员,造成内存泄漏。消除这个问题的方法就是对基类使用虚析构函数:
1 | class Base { |
如果你不想让一个类成为基类,那么在类中声明虚函数是是一个坏主意,因为额外存储的虚表指针会使类的体积变大。
只要基类的析构函数是虚函数,那么派生类的析构函数不论是否用virtual关键字声明,都自动成为虚析构函数。
虚析构函数的运作方式是,最深层派生的那个类的析构函数最先被调用,然后是其上的基类的析构函数被依次调用。
如果你想将基类作为抽象类使用,但手头上又没有别的虚函数,那么将它的析构函数设为纯虚函数是一个不错的想法。考虑以下情形:
1 | class Base { |
但若此时从该基类中派生出新的类,会发生报错,这是因为编译器无法找到基类的析构函数的实现。因此,即使是纯虚析构函数,也需要一个函数体:
1 | Base::~Base() {} |
或者以下写法也被允许:
1 | class Base { |
条款 8:别让异常逃离析构函数
在析构函数中吐出异常并不被禁止,但为了程序的可靠性,应当极力避免这种行为。
为了实现 RAII,我们通常会将对象的销毁方法封装在析构函数中,如下例子:
1 | class DBConn { |
但这样我们就需要在析构函数中完成对异常的处理,以下是几种常见的做法:
第一种:杀死程序:
1 | DBConn::~DBConn() { |
第二种:直接吞下异常不做处理,但这种做法不被建议。
第三种:重新设计接口,将异常的处理交给客户端完成:
1 | class DBConn { |
在这个新设计的接口中,我们提供了close函数供客户手动调用,这样客户也可以根据自己的意愿处理异常;若客户忘记手动调用,析构函数才会自动调用close函数。
当一个操作可能会抛出需要客户处理的异常时,将其暴露在普通函数而非析构函数中是一个更好的选择。
条款 9:绝不在构造和析构过程中调用虚函数
在创建派生类对象时,基类的构造函数永远会早于派生类的构造函数被调用,而基类的析构函数永远会晚于派生类的析构函数被调用。
在派生类对象的基类构造和析构期间,对象的类型是基类而非派生类,因此此时调用虚函数会被编译器解析至基类的虚函数版本,通常不会得到我们想要的结果。
间接调用虚函数是一个比较难以发现的危险行为,需要尽量避免:
1 | class Transaction { |
如果想要基类在构造时就得知派生类的构造信息,推荐的做法是在派生类的构造函数中将必要的信息向上传递给基类的构造函数:
1 | class Transaction { |
注意此处的CreateLogString是一个静态成员函数,这是很重要的,因为静态成员函数可以确保不会使用未完成初始化的成员变量。
条款 10:令 operator= 返回一个指向 *this 的引用
虽然并不强制执行此条款,但为了实现连锁赋值,大部分时候应该这样做:
1 | class Widget { |
条款 11:在 operator= 中处理“自我赋值”
自我赋值是合法的操作,但在一些情况下可能会导致意外的错误,例如在复制堆上的资源时:
1 | Widget& operator+=(const Widget& rhs) { |
但若rhs和*this指向的是相同的对象,就会导致访问到已删除的数据。
最简单的解决方法是在执行后续语句前先进行证同测试(Identity test):
1 | Widget& operator=(const Widget& rhs) { |
另一个常见的做法是只关注异常安全性,而不关注是否自我赋值:
1 | Widget& operator=(const Widget& rhs) { |
仅仅是适当安排语句的顺序,就可以做到使整个过程具有异常安全性。
还有一种取巧的做法是使用 copy and swap 技术,这种技术聪明地利用了栈空间会自动释放的特性,这样就可以通过析构函数来实现资源的释放:
1 | Widget& operator=(const Widget& rhs) { |
上述做法还可以写得更加巧妙,就是利用按值传参,自动调用构造函数:
1 | Widget& operator=(Widget rhs) { |
条款 12:复制对象时勿忘其每一个成分
这个条款正如其字面意思,当你决定手动实现拷贝构造函数或拷贝赋值运算符时,忘记复制任何一个成员都可能会导致意外的错误。
当使用继承时,继承自基类的成员往往容易忘记在派生类中完成复制,如果你的基类拥有拷贝构造函数和拷贝赋值运算符,应该记得调用它们:
1 | class PriorityCustomer : public Customer { |
注意,不要尝试在拷贝构造函数中调用拷贝赋值运算符,或在拷贝赋值运算符的实现中调用拷贝构造函数,一个在初始化时,一个在初始化后,它们的功用是不同的。
第三章:资源管理
条款 13:以对象管理资源
对于传统的堆资源管理,我们需要使用成对的new和delete,这样若忘记delete就会造成内存泄露。因此,我们应尽可能以对象管理资源,并采用RAII(Resource Acquisition Is Initialize,资源取得时机便是初始化时机),让析构函数负责资源的释放。
原书此处关于智能指针的内容已经过时,在 C++11 中,通过专一所有权来管理RAII对象可以使用std::unique_ptr,通过引用计数来管理RAII对象可以使用std::shared_ptr。
1 | // Investment* CreateInvestment(); |
智能指针默认会自动delete所持有的对象,我们也可以为智能指针指定所管理对象的释放方式(删除器deleter):
1 | // void GetRidOfInvestment(Investment*) {} |
条款 14:在资源管理类中小心拷贝行为
我们应该永远保持这样的思考:当一个RAII对象被复制,会发生什么事?
选择一:禁止复制
许多时候允许RAII对象被复制并不合理,如果确是如此,那么就该明确禁止复制行为,条款 6 已经阐述了怎么做这件事。
选择二:对底层资源祭出“引用计数法”
正如std::shared_ptr所做的那样,每一次复制对象就使引用计数+1,每一个对象离开定义域就调用析构函数使引用计数-1,直到引用计数为0就彻底销毁资源。
选择三:复制底层资源
在复制对象的同时复制底层资源的行为又被称作深拷贝(Deep copying),例如在一个对象中有一个指针,那么在复制这个对象时就不能只复制指针,也要复制指针所指向的数据。
选择四:转移底层资源的所有权
和std::unique_ptr的行为类似,永远保持只有一个对象拥有对资源的管理权,当需要复制对象时转移资源的管理权。
条款 15:在资源管理类中提供对原始资源的访问
和所有的智能指针一样,STL 中的智能指针也提供了对原始资源的隐式访问和显式访问:
1 | Investment* pRaw = pSharedInv.get(); // 显式访问原始资源 |
当我们在设计自己的资源管理类时,也要考虑在提供对原始资源的访问时,是使用显式访问还是隐式访问的方法,还是两者皆可。
1 | class Font { |
一般而言显式转换比较安全,但隐式转换对客户比较方便。
条款 16:成对使用 new 和 delete 时要采用相同形式
使用new来分配单一对象,使用new[]来分配对象数组,必须明确它们的行为并不一致,分配对象数组时会额外在内存中记录“数组大小”,而使用delete[]会根据记录的数组大小多次调用析构函数,使用delete则仅仅只会调用一次析构函数。对于单一对象使用delete[]其结果也是未定义的,程序可能会读取若干内存并将其错误地解释为数组大小。
1 | int* array = new int[10]; |
需要注意的是,使用typedef定义数组类型会带来额外的风险:
1 | typedef std::string AddressLines[4]; |
条款 17:以独立语句将 newed 对象置入智能指针
原书此处所讲已过时,现在更好的做法是使用std::make_unique和std::make_shared:
1 | auto pUniqueInv = std::make_unique<Investment>(); // since C++14 |
第四章:设计与声明
条款 18:让接口容易被正确使用,不易被误用
- 好的接口很容易被正确使用,不易被误用。你应在在你的所有接口中努力达成这些性质。
- “促进正确使用”的办法包括接口的一致性,以及与内置类型的行为兼容。
- “阻止误用”的办法包括建立新类型、限制类型上的操作,束缚对象值,以及消除客户的资源管理责任。
1 | // 三个参数类型相同的函数容易造成误用 |
- 尽量使用智能指针,避免跨DLL的 new 和 delete,使用智能指针自定义删除器来解除互斥锁(mutexes)。
条款 19:设计 class 犹如设计 type
几乎在设计每一个 class 时,都要面对如下问题:
新 type 对象应该如何被创建和销毁?
这会影响到类中构造函数、析构函数、内存分配和释放函数(operator new,operator new[],operator delete,operator delete[])的设计。
对象的初始化和赋值该有什么样的差别?
这会影响到构造函数和拷贝赋值运算之间行为的差异。
新 type 的对象如果被按值传递,意味着什么?
这会影响到拷贝构造函数的实现。
什么是新 type 的合法值?
你的类中的成员函数必须对类中成员变量的值进行检查,如果不合法就要尽快解决或明确地抛出异常。
你的新 type 需要配合某个继承图系吗?
你的类是否受到基类设计地束缚,是否拥有该覆写地虚函数,是否允许被继承(若不想要被继承,应该声明为final)。
什么样的运算符和函数对此新 type 而言是合理的?
这会影响到你将为你的类声明哪些函数和重载哪些运算符。
什么样的标准函数应该被驳回?
这会影响到你将哪些标准函数声明为= delete。
谁该取用新 type 的成员?
这会影响到你将类中哪些成员设为 public,private 或 protected,也将影响到友元类和友元函数的设置。
什么是新 type 的“未声明接口”?
为未声明接口提供效率、异常安全性以及资源运用上的保证,并在实现代码中加上相应的约束条件。
你的新 type 有多么一般化?
如果你想要一系列新 type 家族,应该优先考虑模板类。
条款 20:宁以按常引用传参替换按值传参
当使用按值传参时,程序会调用对象的拷贝构造函数构建一个在函数内作用的局部对象,这个过程的开销可能会较为昂贵。对于任何用户自定义类型,使用按常引用传参是较为推荐的:
1 | bool ValidateStudent(const Student& s); |
因为没有任何新对象被创建,这种传参方式不会调用任何构造函数或析构函数,所以效率比按值传参高得多。
使用按引用传参也可以避免对象切片(Object slicing) 的问题,参考以下例子:
1 | class Window { |
此处一个WindowWithScrollBars类继承自Window基类。
1 | void PrintNameAndDisplay(Window w) { // 按值传参,会发生对象切片 |
此处在传参时,调用了基类Window的拷贝构造函数而非派生类的拷贝构造函数,因此在函数种使用的是一个Window对象,调用虚函数时也只能调用到基类的虚函数Window::Display。
由于按引用传递不会创建新对象,这个问题就能得到避免:
1 | void PrintNameAndDisplay(const Window& w) { // 参数不会被切片 |
也并非永远都使用按引用传参,对于内置类型、STL的迭代器和函数对象,我们认为使用按值传参是比较合适的。
条款 21:必须返回对象时,别妄想返回其引用
返回一个指向函数内部局部变量的引用是严重的错误,因为局部变量在离开函数时就被销毁了,除此之外,返回一个指向局部静态变量的引用也是不被推荐的。
尽管返回对象会调用拷贝构造函数产生开销,但这开销比起出错而言微不足道。
条款 22:将成员变量声明为 private
出于对封装性的考虑,应该尽可能地隐藏类中的成员变量,并通过对外暴露函数接口来实现对成员变量的访问:
1 | class AccessLevels { |
通过为成员变量提供 getter 和 setter 函数,我们就能避免客户做出写入只读变量或读取只写变量这样不被允许的操作。
将成员变量隐藏在函数接口的背后,可以为“所有可能的实现”提供弹性。例如这可使得在成员变量被读或写时轻松通知其它对象,可以验证类的约束条件以及函数的提前和事后状态,可以在多线程环境中执行同步控制……
protected和public一样,都不该被优先考虑。假设我们有一个public成员变量,最终取消了它,那么所有使用它的客户代码都将被破坏;假设我们有一个protected成员变量,最终取消了它,那么所有使用它的派生类都将被破坏。
综合以上讨论,在类中应当将成员变量优先声明为 private。
条款 23:宁以非成员、非友元函数替换成员函数
假设有这样一个类:
1 | class WebBrowser { |
如果想要一次性调用这三个函数,那么需要额外提供一个新的函数:
1 | void ClearEverything(WebBrowser& wb) { |
注意,虽然成员函数和非成员函数都可以完成我们的目标,但此处更建议使用非成员函数,这是为了遵守一个原则:越少的代码可以访问数据,数据的封装性就越强。此处的ClearEverything函数仅仅是调用了WebBrowser的三个public成员函数,而并没有使用到WebBrowser内部的private成员,因此没有必要让其也拥有访问类中private成员的能力。
这个原则对于友元函数也是相同的,因为友元函数和成员函数拥有相同的权力,所以在能使用非成员函数完成任务的情况下,就不要使用友元函数和成员函数。
如果你觉得一个全局函数并不自然,也可以考虑将ClearEverything函数放在工具类中充当静态成员函数,或与WebBrowser放在同一个命名空间中:
1 | namespace WebBrowserStuff { |
条款 24:若所有参数皆需类型转换,请为此采用非成员函数
现在我们手头上拥有一个Rational类,并且它可以和int隐式转换:
1 | class Rational { |
当然,我们需要重载乘法运算符来实现Rational对象之间的乘法:
1 | class Rational { |
将运算符重载放在类中是行得通的,至少对于Rational对象来说是如此。但当我们考虑混合运算时,就会出现一个问题:
1 | Rational oneEight(1, 8); |
假如将乘法运算符写成函数形式,错误的原因就一目了然了:
1 | result = oneHalf.operator*(2); // 正确 |
在调用operator*时,int类型的变量会隐式转换为Rational对象,因此用Rational对象乘以int对象是合法的,但反过来则不是如此。
所以,为了避免这个错误,我们应当将运算符重载放在类外,作为非成员函数:
1 | const Rational operator*(const Rational& lhs, const Rational& rhs); |
条款 25:考虑写出一个不抛异常的swap函数
由于std::swap函数在 C++11 后改为了用std::move实现,因此几乎已经没有性能的缺陷,也不再有像原书中所说的为自定义类型去自己实现的必要。不过原书中透露的思想还是值得一学的。
如果想为自定义类型实现自己的swap方法,可以考虑使用模板全特化,并且这种做法是被 STL 允许的:
1 | class Widget { |
注意,由于外部函数并不能直接访问Widget的private成员变量,因此我们先是在类中定义了一个 public 成员函数,再由std::swap去调用这个成员函数。
然而若Widget和WidgetImpl是类模板,情况就没有这么简单了,因为 C++ 不支持函数模板偏特化,所以只能使用重载的方式:
1 | namespace std { |
但很抱歉,这种做法是被 STL 禁止的,因为这是在试图向 STL 中添加新的内容,所以我们只能退而求其次,在其它命名空间中定义新的swap函数:
1 | namespace WidgetStuff { |
我们希望在对自定义对象进行操作时找到正确的swap函数重载版本,这时候如果再写成std::swap,就会强制使用 STL 中的swap函数,无法满足我们的需求,因此需要改写成:
1 | using std::swap; |
这样,C++ 名称查找法则能保证我们优先使用的是自定义的swap函数而非 STL 中的swap函数。
C++ 名称查找法则:编译器会从使用名字的地方开始向上查找,由内向外查找各级作用域(命名空间)直到全局作用域(命名空间),找到同名的声明即停止,若最终没找到则报错。
函数匹配优先级:普通函数 > 特化函数 > 模板函数
第五章:实现
条款 26:尽可能延后变量定义式出现的时间
当变量定义出现时,程序需要承受其构造成本;当变量离开其作用域时,程序需要承受其析构成本。因此,避免不必要的变量定义,以及延后变量定义式直到你确实需要它。
延后变量定义式还有一个意义,即“默认构造+赋值”效率低于“直接构造”:
1 | // 效率低 |
对于循环中变量的定义,我们一般有两种做法:
A. 定义于循环外,在循环中赋值:
1 | Widget w; |
这种做法产生的开销:1 个构造函数 + 1 个析构函数 + n 个赋值操作
B. 定义于循环内:
1 | for (int i = 0; i < n; ++i) { |
这种做法产生的开销:n 个构造函数 + n 个析构函数
由于做法A会将变量的作用域扩大,因此除非知道该变量的赋值成本比“构造+析构”成本低,或者对这段程序的效率要求非常高,否则建议使用做法B。
条款 27:少做转型动作
C 式转型:
1 | (T)expression |
C++ 式转型:
1 | const_cast<T>(expression) |
const_cast用于常量性转除,这也是唯一一个有这个能力的 C++ 式转型。dynamic_cast用于安全地向下转型,这也是唯一一个 C 式转型无法代替的转型操作,它会执行对继承体系的检查,因此会带来额外的开销。只有拥有虚函数的基类指针能进行dynamic_cast。reinterpret_cast用于在任意两个类型间进行低级转型,执行该转型可能会带来风险,也可能不具备移植性。static_cast用于进行强制隐式转换,也是最常用的转型操作,可以将内置数据类型互相转换,也可以将void*和typed指针,基类指针和派生类指针互相转换。
尽量在 C++ 程序中使用 C++ 式转型,因为 C++ 式转型操作功能更明确,可以避免不必要的错误。
唯一使用 C 式转型的时机可能是在调用 explicit 构造函数时:
1 | class Widget { |
需要注意的是,转型并非什么都没有做,而是可能会更改数据的底层表述,或者为指针附加偏移值,这和具体平台有关,因此不要妄图去揣测转型后对象的具体布局方式。
避免对*this进行转型,参考以下例子:
1 | class Window { |
这段代码试图通过转型*this来调用基类的虚函数,然而这是严重错误的,这样做会得到一个新的Window副本并在该副本上调用函数,而非在原本的对象上调用函数。
正确的做法如下:
1 | class SpecialWindow : public Window { |
当你想知道一个基类指针是否指向一个派生类对象时,你需要用到dynamic_cast,如果不满足,则会产生报错。但是对于继承体系的检查可能是非常慢的,所以在注重效率的程序中应当避免使用dynamic_cast,改用static_cast或别的代替方法。
条款 28:避免返回 handles 指向对象的内部成分
考虑以下Rectangle类:
1 | struct RectData { |
这段代码看起来没有任何问题,但其实是在做自我矛盾的事情:我们通过const成员函数返回了一个指向成员变量的引用,这使得成员变量可以在外部被修改,而这是违反 logical constness 的原则的。换句话说,你绝对不应该令成员函数返回一个指针指向“访问级别较低”的成员函数。
改成返回常引用可以避免对成员变量的修改:
1 | const Point& UpperLeft() const { return pData->ulhc; } |
但是这样依然会带来一个称作 dangling handles(空悬句柄) 的问题,当对象不复存在时,你将无法通过引用获取到返回的数据。
采用最保守的做法,返回一个成员变量的副本:
1 | Point UpperLeft() const { return pData->ulhc; } |
避免返回 handles(包括引用、指针、迭代器)指向对象内部。遵循这个条款可增加封装性,使得const成员函数的行为符合常量性,并将发生 “空悬句柄” 的可能性降到最低。
条款 29:为“异常安全”而努力是值得的
异常安全函数提供以下三个保证之一:
基本承诺:
如果异常被抛出,程序内的任何事物仍然保持在有效状态下,没有任何对象或数据结构会因此败坏,所有对象都处于一种内部前后一致的状态,然而程序的真实状态是不可知的,也就是说客户需要额外检查程序处于哪种状态并作出对应的处理。
强烈保证:
如果异常被抛出,程序状态完全不改变,换句话说,程序会回复到“调用函数之前”的状态。
不抛掷(nothrow)保证:
承诺绝不抛出异常,因为程序总是能完成原先承诺的功能。作用于内置类型身上的所有操作都提供 nothrow 保证。
原书中实现 nothrow 的方法是throw(),不过这套异常规范在 C++11 中已经被弃用,取而代之的是noexcept关键字:
1 | int DoSomething() noexcept; |
注意,使用noexcept并不代表函数绝对不会抛出异常,而是在抛出异常时,将代表出现严重错误,会有意想不到的函数被调用(可以通过set_unexpected设置),接着程序会直接崩溃。
当异常被抛出时,带有异常安全性的函数会:
- 不泄漏任何资源。
- 不允许数据败坏。
考虑以下PrettyMenu的ChangeBackground函数:
1 | class PrettyMenu { |
很明显这个函数不满足我们所说的具有异常安全性的任何一个条件,若在函数中抛出异常,mutex会发生资源泄漏,bgImage和imageChanges也会发生数据败坏。
通过以对象管理资源,使用智能指针和调换代码顺序,我们能将其变成一个具有强烈保证的异常安全函数:
1 | void PrettyMenu::ChangeBackground(std::vector<uint8_t>& imgSrc) { |
另一个常用于提供强烈保证的方法是我们所提到过的 copy and swap,为你打算修改的对象做出一份副本,对副本执行修改,并在所有修改都成功执行后,用一个不会抛出异常的swap方法将原件和副本交换:
1 | struct PMImpl { |
当一个函数调用其它函数时,函数提供的“异常安全保证”通常最高只等于其所调用的各个函数的“异常安全保证”中的最弱者。
强烈保证并非永远都是可实现的,特别是当函数在操控非局部对象时,这时就只能退而求其次选择不那么美好的基本承诺,并将该决定写入文档,让其他人维护时不至于毫无心理准备。
条款 30:透彻了解 inlining 的里里外外
将函数声明为内联一共有两种方法,一种是为其显式指定inline关键字,另一种是直接将成员函数的定义式写在类中,如下所示:
1 | class Person { |
在inline诞生之初,它被当作是一种对编译器的优化建议,即将“对此函数的每一个调用”都以函数本体替换之。但在编译器的具体实现中,该行为完全被优化等级所控制,与函数是否内联无关。
在现在的 C++ 标准中,inline作为优化建议的含义已经被完全抛弃,取而代之的是“允许函数在不同编译单元中多重定义”,使得可以在头文件中直接给出函数的实现。
在 C++17 中,引入了一个新的inline用法,使静态成员变量可以在类中直接定义:
1 | class Person { |
条款 31:将文件间的编译依存关系降至最低
C++ 坚持将类的实现细节放置于类的定义式中,这就意味着,即使你只改变类的实现而不改变类的接口,在构建程序时依然需要重新编译。这个问题的根源出在编译器必须在编译期间知道对象的大小,如果看不到类的定义式,就没有办法为对象分配内存。也就是说,C++ 并没有把“将接口从实现中分离”这件事做得很好。
用“声明的依存性”替换“定义的依存性”:
我们可以玩一个“将对象实现细目隐藏于一个指针背后”的游戏,称作 pimpl idiom(pimpl 是 pointer to implemention 的缩写):将原来的一个类分割为两个类,一个只提供接口,另一个负责实现该接口,称作句柄类(handle class):
1 | // person.hpp 负责声明类 |
这样,假如我们要修改Person的private成员,就只需要修改PersonImpl中的内容,而PersonImpl的具体实现是被隐藏起来的,对它的任何修改都不会使得Person客户端重新编译,真正实现了“类的接口和实现分离”。
如果使用对象引用或对象指针可以完成任务,就不要使用对象本身:
你可以只靠一个类型声明式就定义出指向该类型的引用和指针;但如果定义某类型的对象,就需要用到该类型的定义式。
如果能够,尽量以类声明式替换类定义式:
当你在声明一个函数而它用到某个类时,你不需要该类的定义;但当你触及到该函数的定义式后,就必须也知道类的定义:
1 | class Date; // 类的声明式 |
为声明式和定义式提供不同的头文件:
为了避免频繁地添加声明,我们应该为所有要用的类声明提供一个头文件,这种做法对 template 也适用:
1 |
|
此处的头文件命名方式"datefwd.h"取自标准库中的<iosfwd>。
上面我们讲述了接口与实现分离的其中一个方法——提供句柄类,另一个方法就是将句柄类定义为抽象基类,称作接口类(interface class):
1 | class Person { |
为了将Person对象实际创建出来,我们一般采用工厂模式。可以尝试在类中塞入一个静态成员函数Create用于创建对象:
1 | class Person { |
但此时Create函数还无法使用,需要在派生类中给出Person类中的函数的具体实现:
1 | class RealPerson : public Person { |
完成Create函数的定义:
1 | static std::shared_ptr<Person> Person::Create() { |
毫无疑问的是,句柄类和接口类都需要额外的开销:句柄类需要通过 pimpl 取得对象数据,增加一层间接访问、指针大小和动态分配内存带来的开销;而接口类会增加存储虚表指针和实现虚函数跳转带来的开销。
而当这些开销过于重大以至于类之间的耦合度在相形之下不成为关键时,就以具象类(concrete class)替换句柄类和接口类。
第六章:继承与面向对象设计
条款 32:确定你的public继承塑模出 is-a 关系
“public继承”意味着 is-a,所谓 is-a,就是指适用于基类身上的每一件事情一定也适用于继承类身上,因为我们可以认为每一个派生类对象也都是一个基类对象。
这看似很自然,但在面对自然语言的表述时,往往会产生歧义。
考虑Bird类和Penguin类的继承关系:
1 | class Bird { |
Penguin类会获得来自Bird类的飞行方法,这就造成了误解,因为企鹅恰恰是不会飞的鸟类。一种解决方法是当调用Penguin类中的Fly函数时,抛出一个运行期错误,但这种做法通常不够直观;另一个解决方法是使用双继承,区分会飞和不会飞的鸟类:
1 | class Bird { |
但若要处理鸟类的多钟不同属性时,双继承模式就不太管用了,因此我们总是说程序设计没有银弹。
另一个常见的例子是用Square类继承自Rectangle类,从几何学的角度来讲这很自然,然而正方形的长宽是相等的,矩形却不是如此,因此Square类和Rectangle类也无法满足严格的 is-a 关系。
条款 33:避免遮掩继承而来的名称
之前我们了解过 C++ 名称查找法则,这在继承体系中也是类似的,当我们在派生类中使用到一个名字时,编译器会优先查找派生类覆盖的作用域,如果没找到,再去查找基类的作用域,最后再查找全局作用域。
考虑以下情形:
1 | class Base { |
这样会导致派生类无法使用来自基类的重载函数,因为派生类中的名称mf掩盖了来自基类的名称mf。
对于名称掩盖问题的一种方法是使用using关键字:
1 | class Derived : public Base { |
using关键字会将基类中所有使用到名称mf的函数全部包含在派生类中,包括其重载版本。
若有时我们不想要一个函数的全部版本,只想要单一版本(特别是在private继承时),可以考虑使用转发函数(forwarding function):
1 | class Base { |
条款 34:区分接口继承和实现继承
-
接口继承和实现继承不一样。在public继承下,派生类总是继承基类的接口。
-
声明一个纯虚函数的目的,是为了让派生类只继承函数接口。
-
声明简朴的非纯虚函数的目的,是让派生类继承该函数的接口和缺省实现。
-
声明非虚函数的目的,是为了令派生类继承函数的接口及一份强制性实现。
通常而言,我们不会为纯虚函数提供具体实现,然而这样做是被允许的,并且用于替代简朴的非纯虚函数,提供更平常更安全的缺省实现。
用非纯虚函数提供缺省的默认实现:
1 | class Airplane { |
这是最简朴的做法,但是这样做会带来的问题是,由于不强制对虚函数的覆写,在定义新的派生类时可能会忘记进行覆写,导致错误地使用了缺省实现。
使用纯虚函数并提供默认实现:
1 | class Airplane { |
上述写法可以替代为:
1 | class Airplane { |
条款 35:考虑虚函数以外的其它选择
藉由非虚接口手法实现 template method:
非虚接口(non-virtual interface,NVI) 设计手法的核心就是用一个非虚函数作为 wrapper,将虚函数隐藏在封装之下:
1 | class GameCharacter { |
NVI手法的一个优点就是在 wrapper 中做一些前置和后置工作,确保得以在一个虚函数被调用之前设定好适当场景,并在调用结束之后清理场景。如果你让客户直接调用虚函数,就没有任何好办法可以做这些事。
NVI手法允许派生类重新定义虚函数,从而赋予它们“如何实现机能”的控制能力,但基类保留诉说“函数何时被调用”的权利。
在NVI手法中虚函数除了可以是private,也可以是protected,例如要求在派生类的虚函数实现内调用其基类的对应虚函数时,就必须得这么做。
藉由函数指针实现 Strategy 模式:
参考以下例子:
1 | class GameCharacter; |
同一个人物类型的不同实体可以有不同的健康计算函数,并且该计算函数可以在运行期变更。
这间接表明健康计算函数不再是GameCharacter继承体系内的成员函数,它也无权使用非public成员。为了填补这个缺陷,我们唯一的做法是弱化类的封装,引入友元或提供public访问函数。
藉由 std::function 完成 Strategy 模式
std::function是 C++11 中引入的函数包装器,使用它能提供比函数指针更强的灵活度:
1 | class GameCharacter; |
看起来并没有很大的改变,但当我们需要时,std::function就能展现出惊人的弹性:
1 | // 使用返回值不同的函数 |
古典的 Strategy 模式:
在古典的 Strategy 模式中,我们并非直接利用函数指针(或包装器)调用函数,而是内含一个指针指向来自HealthCalcFunc继承体系的对象:
1 | class GameCharacter; |
这个设计模式的好处在于足够容易辨认,想要添加新的计算函数也只需要为HealthCalcFunc基类添加一个派生类即可。
条款 36:绝不重新定义继承而来的非虚函数
非虚函数和虚函数具有本质上的不同:非虚函数执行的是静态绑定(statically bound,又称前期绑定,early binding),由对象类型本身(称之静态类型)决定要调用的函数;而虚函数执行的是动态绑定(dynamically bound,又称后期绑定,late binding),决定因素不在对象本身,而在于“指向该对象之指针”当初的声明类型(称之动态类型)。
前面我们已经说过,public继承意味着 is-a 关系,而在基类中声明一个非虚函数将会为该类建立起一种不变性(invariant),凌驾其特异性(specialization)。而若在派生类中重新定义该非虚函数,则会使人开始质疑是否该使用public继承的形式;如果必须使用,则又打破了基类“不变性凌驾特异性”的性质,就此产生了设计上的矛盾。
综上所述,在任何情况下都不该重新定义一个继承而来的非虚函数。
条款 37:绝不重新定义继承而来的缺省参数值
在条款 36 中我们已经否定了重新定义非虚函数的可能性,因此此处我们只讨论带有缺省参数值的虚函数。
虚函数是动态绑定而来,意思是调用一个虚函数时,究竟调用哪一份函数实现代码,取决于发出调用的那个对象的动态类型。但与之不同的是,缺省参数值却是静态绑定,意思是你可能会在“调用一个定义于派生类的虚函数”的同时,却使用基类为它所指定的缺省参数值。考虑以下例子:
1 | class Shape { |
此时若对派生类对象调用Draw函数,则会发现:
1 | Shape* pr = new Rectangle; |
这就迫使我们在指定虚函数时使用相同的缺省参数值,为了避免不必要的麻烦和错误,可以考虑条款 35 中列出的虚函数的替代设计,例如NVI手法:
1 | class Shape { |
条款 38:通过复合塑模出 has-a 或“根据某物实现出”
所谓复合(composition),指的是某种类型的对象内含它种类型的对象。复合通常意味着 has-a 或根据某物实现出(is-implemented-in-terms-of) 的关系,当复合发生于应用域(application domain)内的对象之间,表现出 has-a 的关系;当它发生于实现域(implementation domain)内则是表现出“根据某物实现出”的关系。
下面是一个 has-a 关系的例子:
1 | class Address { ... }; |
下面是一个“根据某物实现出”关系的例子:
1 | // 将 list 应用于 Set |
条款 39:明智而审慎地使用private继承
private继承的特点:
- 如果类之间是private继承关系,那么编译器不会自动将一个派生类对象转换为一个基类对象。
- 由private继承来的所有成员,在派生类中都会变为private属性,换句话说,private继承只继承实现,不继承接口。
private继承的意义是“根据某物实现出”,如果你读过条款 38,就会发现private继承和复合具有相同的意义,事实上也确实如此,绝大部分private继承的使用场合都可以被“public继承+复合”完美解决:
1 | class Timer { |
替代为:
1 | class Widget { |
使用后者比前者好的原因有以下几点:
- private继承无法阻止派生类重新定义虚函数,但若使用public继承定义
WidgetTimer类并复合在Widget类中,就能防止在Widget类中重新定义虚函数。 - 可以仅提供
WidgetTimer类的声明,并将WidgetTimer类的具体定义移至实现文件中,从而降低Widget的编译依存性。
然而private继承并非完全一无是处,一个适用于它的极端情况是空白基类最优化(empty base optimization,EBO),参考以下例子:
1 | class Empty {}; |
一个没有非静态成员变量、虚函数的类,看似不需要任何存储空间,但实际上 C++ 规定凡是独立对象都必须有非零大小,因此此处sizeof(HoldsAnInt)必然大于sizeof(int),通常会多出一字节大小,但有时考虑到内存对齐之类的要求,可能会多出更多的空间。
使用private继承可以避免产生额外存储空间,将上面的代码替代为:
1 | class HoldsAnInt : private Empty { |
条款 40:明智而审慎地使用多重继承
多重继承是一个可能会造成很多歧义和误解的设计,因此反对它的声音此起彼伏,下面我们来接触几个使用多重继承的场景。
最先需要认清的一件事是,程序有可能从一个以上的基类继承相同名称,那会导致较多的歧义机会:
1 | class BorrowableItem { |
如果真遇到这种情况,必须明确地指出要调用哪一个基类中的函数:
1 | mp.BorrowableItem::CheckOut(); // 使用 BorrowableItem::CheckOut |
在使用多重继承时,我们可能会遇到要命的“钻石型继承(菱形继承)”:
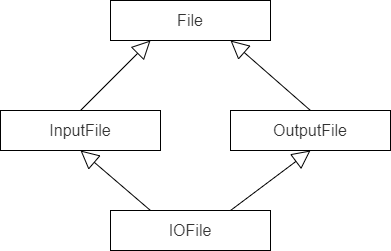
1 | class File { ... }; |
这时候必须面对这样一个问题:是否打算让基类内的成员变量经由每一条路径被复制?如果不想要这样,应当使用虚继承,指出其愿意共享基类:
1 | class File { ... }; |
然而由于虚继承会在派生类中额外存储信息来确认成员来自于哪个基类,虚继承通常会付出更多空间和速度的代价,并且由于虚基类的初始化责任是由继承体系中最底层的派生类负责,就导致了虚基类必须认知其虚基类并且承担虚基类的初始化责任。因此我们应当遵循以下两个建议:
- 非必要不使用虚继承。
- 如果必须使用虚继承,尽可能避免在虚基类中放置数据。
多重继承可用于结合public继承和private继承,public继承用于提供接口,private继承用于提供实现:
1 | // IPerson 类指出要实现的接口 |
第七章:模板与泛型编程
条款 41:了解隐式接口和编译期多态
类与模板都支持接口和多态。对于类而言接口是显式的,以函数签名为中心,多态则是通过虚函数发生于运行期;而对模板参数而言,接口是隐式的,奠基于有效表达式,多态则是通过模板具现化和函数重载解析(function overloading resolution)发生于编译期。
考虑以下例子:
1 | template<typename T> |
以上代码中,T类型的隐式接口要求:
- 提供一个名为
size的成员函数,该函数的返回值可与int(10 的类型)执行operator>,或经过隐式转换后可执行operator>。 - 必须支持一个
operator!=函数,接受T类型和someNastyWidget的类型,或其隐式转换后得到的类型。
此处没有考虑
operator&&被重载的可能性。
加诸于模板参数身上的隐式接口,就像加诸于类对象身上的显式接口“一样真实”,两者都在编译期完成检查,你无法在模板中使用“不支持模板所要求之隐式接口”的对象(代码无法通过编译)。
条款 42:了解 typename 的双重含义
在模板声明式中,使用class和typename关键字并没有什么不同,但在模板内部,typename拥有更多的一重含义。
为了方便解释,我们首先需要引入一个模板相关的概念:模板内出现的名称如果相依于某个模板参数,我们称之为从属名称(dependent names);如果从属名称在类内呈嵌套状,我们称之为嵌套从属名称(nested dependent name);如果一个名称并不倚赖任何模板参数的名称,我们称之为非从属名称(non-dependent names)。
考虑以下模板代码:
1 | template<typename C> |
这段代码看起来没有任何问题,但实际编译时却会报错,这一切的罪魁祸首便是C::const_iterator。此处的C::const_iterator是一个指向某类型的嵌套从属类型名称(nested dependent type name),而嵌套从属名称可能会导致解析困难,因为在编译器知道C是什么之前,没有任何办法知道C::const_iterator是否为一个类型,这就导致出现了歧义状态,而 C++ 默认假设嵌套从属名称不是类型名称。
显式指明嵌套从属类型名称的方法就是将typename关键字作为其前缀词:
1 | typename C::const_iterator iter(container.begin()); |
同样地,若嵌套从属名称出现在模板函数声明部分,也需要显式地指明是否为类型名称:
1 | template<typename C> |
这一规则的例外是,typename不可以出现在基类列表内的嵌套从属类型名称之前,也不可以在成员初始化列表中作为基类的修饰符:
1 | template<typename T> |
在类型名称过于复杂时,可以使用using或typedef来进行简化:
1 | using value_type = typename std::iterator_traits<IterT>::value_type; |
条款 43:学习处理模板化基类内的名称
在模板编程中,模板类的继承并不像普通类那么自然,考虑以下情形:
1 | class MsgInfo { ... }; |
很明显,由于直到模板类被真正实例化之前,编译器并不知道MsgSender<Company>具体长什么样,有可能它是一个全特化的版本,而在这个版本中不存在SendClear函数。由于 C++ 的设计策略是宁愿较早进行诊断,所以编译器会拒绝承认在基类中存在一个SendClear函数。
为了解决这个问题,我们需要令 C++“进入模板基类观察”的行为生效,有三种办法达成这个目标:
第一种:在基类函数调用动作之前加上this->:
1 | this->SendClear(info); |
第二种:使用using声明式:
1 | using MsgSender<Company>::SendClear; |
第三种:明白指出被调用的函数位于基类内:
1 | MsgSender<Company>::SendClear(info); |
第三种做法是最不令人满意的,如果被调用的是虚函数,上述的明确资格修饰(explicit qualification)会使“虚函数绑定行为”失效。
条款 44:将与参数无关的代码抽离模板
模板可以节省时间和避免代码重复,编译器会为填入的每个不同模板参数具现化出一份对应的代码,但长此以外,可能会造成代码膨胀(code bloat),生成浮夸的二进制目标码。
基于共性和变性分析(commonality and variability analysis) 的方法,我们需要分析模板中重复使用的部分,将其抽离出模板,以减轻模板具现化带来的代码量。
-
因非类型模板参数而造成的代码膨胀,往往可以消除,做法是以函数参数或类成员变量替换模板参数。
-
因类型模板参数而造成的代码膨胀,往往可以降低,做法是让带有完全相同二进制表述的具现类型共享实现代码。
参考以下矩阵类的例子:
1 | template<typename T, std::size_t n> |
修改为:
1 | template<typename T> |
Invert并不是我们唯一要使用的矩阵操作函数,而且每次都往基类传递矩阵尺寸显得太过繁琐,我们可以考虑将数据放在派生类中,在基类中储存指针和矩阵尺寸。修改代码如下:
1 | template<typename T> |
然而这种做法并非永远能取得优势,硬是绑着矩阵尺寸的那个版本,有可能生成比共享版本更佳的代码。例如在尺寸专属版中,尺寸是个编译期常量,因此可以在编译期藉由常量的广传达到最优化;而在共享版本中,不同大小的矩阵只拥有单一版本的函数,可减少可执行文件大小,也就因此降低程序的 working set(在“虚内存环境”下执行的进程所使用的一组内存页),并强化指令高速缓存区内的引用集中化(locality of reference),这些都可能使程序执行得更快速。究竟哪个版本更佳,只能经由具体的测试后决定。
同样地,上面的代码也使用到了牺牲封装性的protected,可能会导致资源管理上的混乱和复杂,考虑到这些,也许一点点模板代码的重复并非不可接受。
条款 45:运用成员函数模板接受所有兼容类型
C++ 视模板类的不同具现体为完全不同的的类型,但在泛型编程中,我们可能需要一个模板类的不同具现体能够相互类型转换。
考虑设计一个智能指针类,而智能指针需要支持不同类型指针之间的隐式转换(如果可以的话),以及普通指针到智能指针的显式转换。很显然,我们需要的是模板拷贝构造函数:
1 | template<typename T> |
使用get获取原始指针,并将在原始指针之间进行类型转换本身提供了一种保障,如果原始指针之间不能隐式转换,那么其对应的智能指针之间的隐式转换会造成编译错误。
模板构造函数并不会阻止编译器暗自生成默认的构造函数,所以如果你想要控制拷贝构造的方方面面,你必须同时声明泛化拷贝构造函数和普通拷贝构造函数,相同规则也适用于赋值运算符:
1 | template<typename T> |
条款 46:需要类型转换时请为模板定义非成员函数
该条款与条款 24 一脉相承,还是使用原先的例子:
1 | template<typename T> |
上述失败启示我们:模板实参在推导过程中,从不将隐式类型转换纳入考虑。虽然以oneHalf推导出Rational<int>类型是可行的,但是试图将int类型隐式转换为Rational<T>是绝对会失败的。
由于模板类并不依赖模板实参推导,所以编译器总能够在Rational<T>具现化时得知T,因此我们可以使用友元声明式在模板类内指涉特定函数:
1 | template<typename T> |
在模板类内,模板名称可被用来作为“模板及其参数”的简略表达形式,因此下面的写法也是一样的:
1 | template<typename T> |
当对象oneHalf被声明为一个Rational<int>时,Rational<int>类于是被具现化出来,而作为过程的一部分,友元函数operator*也就被自动声明出来,其为一个普通函数而非模板函数,因此在接受参数时可以正常执行隐式转换。
为了使程序能正常链接,我们需要为其提供对应的定义式,最简单有效的方法就是直接合并至声明式处:
1 | friend const Rational operator*(const Rational& lhs, const Rational& rhs) { |
由于定义在类内的函数都会暗自成为内联函数,为了降低内联带来的冲击,可以使operator*调用类外的辅助模板函数:
1 | template<typename T> class Rational; |
条款 47:请使用 traits classes 表现类型信息
traits classes 可以使我们在编译期就能获取某些类型信息,它被广泛运用于 C++ 标准库中。traits 并不是 C++ 关键字或一个预先定义好的构件:它们是一种技术,也是 C++ 程序员所共同遵守的协议,并要求对用户自定义类型和内置类型表现得一样好。
设计并实现一个 trait class 的步骤如下:
- 确认若干你希望将来可取得的类型相关信息。
- 为该类型选择一个名称。
- 提供一个模板和一组特化版本,内含你希望支持的类型相关信息。
以迭代器为例,标准库中拥有多种不同的迭代器种类,它们各自拥有不同的功用和限制:
input_iterator_tag:单向输入迭代器,只能向前移动,一次一步,客户只可读取它所指的东西。output_iterator_tag:单向输出迭代器,只能向前移动,一次一步,客户只可写入它所指的东西。forward_iterator_tag:单向访问迭代器,只能向前移动,一次一步,读写均允许。bidirectional_iterator_tag:双向访问迭代器,去除了只能向前移动的限制。random_access_iterator_tag:随机访问迭代器,没有一次一步的限制,允许随意移动,可以执行“迭代器算术”。
标准库为这些迭代器种类提供的卷标结构体(tag struct)的继承关系如下:
1 | struct input_iterator_tag {}; |
将iterator_category作为迭代器种类的名称,嵌入容器的迭代器中,并且确认使用适当的卷标结构体:
1 | template< ... > |
为了做到类型的 traits 信息可以在类型自身之外获得,标准技术是把它放进一个模板及其一个或多个特化版本中。这样的模板在标准库中有若干个,其中针对迭代器的是iterator_traits:
1 | template<class IterT> |
为了支持指针迭代器,iterator_traits特别针对指针类型提供一个偏特化版本,而指针的类型和随机访问迭代器类似,所以可以写出如下代码:
1 | template<class IterT> |
当我们需要为不同的迭代器种类应用不同的代码时,traits classes 就派上用场了:
1 | template<typename IterT, typename DisT> |
但这些代码实际上是错误的,我们希望类型的判断能在编译期完成。iterator_category是在编译期决定的,然而if却是在运行期运作的,无法达成我们的目标。
在 C++17 之前,解决这个问题的主流做法是利用函数重载(也是原书中介绍的做法):
1 | template<typename IterT, typename DisT> |
在 C++17 之后,我们有了更简单有效的做法——使用if constexpr:
1 | template<typename IterT, typename DisT> |
条款 48:认识模板元编程
模板元编程(Template metaprogramming,TMP)是编写基于模板的 C++ 程序并执行于编译期的过程,它并不是刻意被设计出来的,而是当初 C++ 引入模板带来的副产品,事实证明模板元编程具有强大的作用,并且现在已经成为 C++ 标准的一部分。实际上,在条款 47 中编写 traits classes 时,我们就已经在进行模板元编程了。
由于模板元程序执行于 C++ 编译期,因此可以将一些工作从运行期转移至编译期,这可以帮助我们在编译期时发现一些原本要在运行期时才能察觉的错误,以及得到较小的可执行文件、较短的运行期、较少的内存需求。当然,副作用就是会使编译时间变长。
模板元编程已被证明是“图灵完备”的,并且以“函数式语言”的形式发挥作用,因此在模板元编程中没有真正意义上的循环,所有循环效果只能藉由递归实现,而递归在模板元编程中是由 “递归模板具现化(recursive template instantiation)” 实现的。
常用于引入模板元编程的例子是在编译期计算阶乘:
1 | template<unsigned n> // Factorial<n> = n * Factorial<n-1> |
模板元编程很酷,但对其进行调试可能是灾难性的,因此在实际应用中并不常见。我们可能会在下面几种情形中见到它的出场:
- 确保量度单位正确。
- 优化矩阵计算。
- 可以生成客户定制之设计模式(custom design pattern)实现品。
第八章:定制 new 和 delete
条款 49:了解 new-handler 的行为
当operator new无法满足某一内存分配需求时,会不断调用一个客户指定的错误处理函数,即所谓的 new-handler,直到找到足够内存为止,调用声明于<new>中的set_new_handler可以指定这个函数。new_handler和set_new_handler的定义如下:
1 | namespace std { |
一个设计良好的 new-handler 函数必须做以下事情之一:
让更多的内存可被使用:
可以让程序一开始执行就分配一大块内存,而后当 new-handler 第一次被调用,将它们释还给程序使用,造成operator new的下一次内存分配动作可能成功。
安装另一个 new-handler:
如果目前这个 new-handler 无法取得更多内存,可以调换为另一个可以完成目标的 new-handler(令 new-handler 修改“会影响 new-handler 行为”的静态或全局数据)。
卸除 new-handler:
将nullptr传给set_new_handler,这样会使operator new在内存分配不成功时抛出异常。
抛出 bad_alloc(或派生自 bad_alloc)的异常:
这样的异常不会被operator new捕捉,因此会被传播到内存分配处。
不返回:
通常调用std::abort或std::exit。
有的时候我们或许会希望在为不同的类分配对象时,使用不同的方式处理内存分配失败情况。这时候使用静态成员是不错的选择:
1 | public: |
Widget的客户应该类似这样使用其 new-handling:
1 | void OutOfMem(); |
实现这一方案的代码并不因类的不同而不同,因此对这些代码加以复用是合理的构想。一个简单的做法是建立起一个“mixin”风格的基类,让其派生类继承它们所需的set_new_handler和operator new,并且使用模板确保每一个派生类获得一个实体互异的currentHandler成员变量:
1 | template<typename T> |
注意此处的模板参数T并没有真正被当成类型使用,而仅仅是用来区分不同的派生类,使得模板机制为每个派生类具现化出一份对应的currentHandler。
这个做法用到了所谓的 CRTP(curious recurring template pattern,奇异递归模板模式) ,除了在上述设计模式中用到之外,它也被用于实现静态多态:
1 | template <class Derived> |
除了会调用 new-handler 的operator new以外,C++ 还保留了传统的“分配失败便返回空指针”的operator new,称为 nothrow new,通过std::nothrow对象来使用它:
1 | Widget* pw1 = new Widget; // 如果分配失败,抛出 bad_alloc |
nothrow new 对异常的强制保证性并不高,使用它只能保证operator new不抛出异常,而无法保证像new (std::nothrow) Widget这样的表达式不会导致异常,因此实际上并没有使用 nothrow new 的必要。
条款 50:了解 new 和 delete 的合理替换时机
以下是常见的替换默认operator new和operator delete的理由:
用来检测运用上的错误:
如果将“new 所得内存”delete 掉却不幸失败,会导致内存泄漏;如果在“new 所得内存”身上多次 delete 则会导致未定义行为。如果令operator new持有一串动态分配所得地址,而operator delete将地址从中移除,就很容易检测出上述错误用法。此外各式各样的编程错误可能导致 “overruns”(写入点在分配区块尾端之后) 和 “underruns”(写入点在分配区块起点之前),以额外空间放置特定的 byte pattern 签名,检查签名是否原封不动就可以检测此类错误,下面给出了一个这样的范例:
1 | static const int signature = 0xDEADBEEF; // 调试“魔数” |
实际上这段代码不能保证内存对齐,并且有许多地方不遵守 C++ 规范,我们将在条款 51 中进行详细讨论。
为了收集使用上的统计数据:
定制 new 和 delete 动态内存的相关信息:分配区块的大小分布,寿命分布,FIFO(先进先出)、LIFO(后进先出)或随机次序的倾向性,不同的分配/归还形态,使用的最大动态分配量等等。
为了增加分配和归还的速度:
泛用型分配器往往(虽然并非总是)比定制型分配器慢,特别是当定制型分配器专门针对某特定类型之对象设计时。类专属的分配器可以做到“区块尺寸固定”,例如 Boost 提供的 Pool 程序库。又例如,编译器所带的内存管理器是线程安全的,但如果你的程序是单线程的,你也可以考虑写一个不线程安全的分配器来提高速度。当然,这需要你对程序进行分析,并确认程序瓶颈的确发生在那些内存函数身上。
为了降低缺省内存管理器带来的空间额外开销:
泛用型分配器往往(虽然并非总是)还比定制型分配器使用更多内存,那是因为它们常常在每一个分配区块身上招引某些额外开销。针对小型对象而开发的分配器(例如 Boost 的 Pool 程序库)本质上消除了这样的额外开销。
为了弥补缺省分配器中的非最佳内存对齐(suboptimal alignment):
许多计算机体系架构要求特定的类型必须放在特定的内存地址上,如果没有奉行这个约束条件,可能导致运行期硬件异常,或者访问速度变低。std::max_align_t用来返回当前平台的最大默认内存对齐类型,对于malloc分配的内存,其对齐和max_align_t类型的对齐大小应当是一致的,但若对malloc返回的指针进行偏移,就没有办法保证内存对齐。
在 C++11 中,提供了以下内存对齐相关方法:
1 | // alignas 用于指定栈上数据的内存对齐要求 |
在 C++17 后,可以使用std::align_val_t来重载需求额外内存对齐的operator new:
1 | void* operator new(std::size_t count, std::align_val_t al); |
为了将相关对象成簇集中:
如果你知道特定的某个数据结构往往被一起使用,而你又希望在处理这些数据时将“内存页错误(page faults)”的频率降至最低,那么可以考虑为此数据结构创建一个堆,将它们成簇集中在尽可能少的内存页上。一般可以使用 placement new 达成这个目标(见条款 52)。
为了获得非传统的行为:
有时候你会希望operator new和operator delete做编译器版不会做的事情,例如分配和归还共享内存(shared memory),而这些事情只能被 C API 完成,则可以将 C API 封在 C++ 的外壳里,写在定制的 new 和 delete 中。
条款 51:编写 new 和 delete 时需固守常规
我们在条款 49 中已经提到过一些operator new的规矩,比如内存不足时必须不断调用 new-handler,如果无法供应客户申请的内存,就抛出std::bad_alloc异常。C++ 还有一个奇怪的规定,即使客户需求为0字节,operator new也得返回一个合法的指针,这种看似诡异的行为其实是为了简化语言其他部分。
根据这些规约,我们可以写出非成员函数版本的operator new代码:
1 | void* operator new(std::size_t size) { |
operator new的成员函数版本一般只会分配大小刚好为类的大小的内存空间,但是情况并不总是如此,比如假设我们没有为派生类声明其自己的operator new,那么派生类会从基类继承operator new,这就导致派生类可以使用其基类的 new 分配方式,但派生类和基类的大小很多时候是不同的。
处理此情况的最佳做法是将“内存申请量错误”的调用行为改为采用标准的operator new:
1 | void* Base::operator new(std::size_t size) { |
注意在operator new的成员函数版本中我们也不需要检测分配的大小是否为0了,因为在条款 39 中我们提到过,非附属对象必须有非零大小,所以sizeof(Base)无论如何也不能为0。
如果你打算实现operator new[],即所谓的 array new,那么你唯一要做的一件事就是分配一块未加工的原始内存,因为你无法对 array 之内迄今尚未存在的元素对象做任何事情,实际上你甚至无法计算这个 array 将含有多少元素对象。
operator delete的规约更加简单,你需要记住的唯一一件事情就是 C++ 保证 “删除空指针永远安全”:
1 | void operator delete(void* rawMemory) noexcept { |
operator delete的成员函数版本要多做的唯一一件事就是将大小有误的删除行为转交给标准的operator delete:
1 | void Base::operator delete(void* rawMemory, std::size_t size) noexcept { |
如果即将被删除的对象派生自某个基类而后者缺少虚析构函数,那么 C++ 传给operator delete的size大小可能不正确,这或许是“为多态基类声明虚析构函数”的一个足够的理由,能作为对条款 7 的补充。
条款 52:写了 placement new 也要写 placement delete
placement new 最初的含义指的是“接受一个指针指向对象该被构造之处”的operator new版本,它在标准库中的用途广泛,其中之一是负责在 vector 的未使用空间上创建对象,它的声明如下:
1 | void* operator new(std::size_t, void* pMemory) noexcept; |
我们此处要讨论的是广义上的 placement new,即带有附加参数的operator new,例如下面这种:
1 | void* operator new(std::size_t, std::ostream& logStream); |
当我们在使用 new 表达式创建对象时,共有两个函数被调用:一个是用以分配内存的operator new,一个是对象的构造函数。假设第一个函数调用成功,而第二个函数却抛出异常,那么会由 C++ runtime 调用operator delete,归还已经分配好的内存。
这一切的前提是 C++ runtime 能够找到operator new对应的operator delete,如果我们使用的是自定义的 placement new,而没有为其准备对应的 placement delete 的话,就无法避免发生内存泄漏。因此,合格的代码应该是这样的:
1 | class Widget { |
另一个要注意的问题是,由于成员函数的名称会掩盖其外部作用域中的相同名称(见条款 33),所以提供 placement new 会导致无法使用正常版本的operator new:
1 | class Base { |
同样道理,派生类中的operator new会掩盖全局版本和继承而得的operator new版本:
1 | class Derived : public Base { |
为了避免名称遮掩问题,需要确保以下形式的operator new对于定制类型仍然可用,除非你的意图就是阻止客户使用它们:
1 | void* operator(std::size_t) throw(std::bad_alloc); // normal new |
一个最简单的实现方式是,准备一个基类,内含所有正常形式的 new 和 delete:
1 | class StadardNewDeleteForms{ |
凡是想以自定义形式扩充标准形式的客户,可以利用继承和using声明式(见条款 33)取得标准形式:
1 | class Widget: public StandardNewDeleteForms{ |
第九章:杂项讨论
条款 53:不要轻忽编译器的警告
- 严肃对待编译器发出的警告信息。努力在你的编译器的最高(最严苛)警告级别下争取“无任何警告”的荣誉。
- 不要过度依赖编译器的警告能力,因为不同的编译器对待事情的态度不同。一旦移植到另一个编译器上,你原本依赖的警告信息可能会消失。
条款 54:让自己熟悉包括 TR1 在内的标准程序库
如今 TR1 草案已完全融入 C++ 标准当中,没有再过多了解 TR1 标准库的必要。
条款 55:让自己熟悉 Boost
Boost 是若干个程序库的集合,并且当中的许多库已经被 C++ 吸纳为标准库的一部分。不过在现在的 Modern C++ 时代,是否该在项目中使用 Boost 仍然有一定的争议,一些 Boost 组件并无法做到像 C++ 标准库那样高性能,零开销抽象,但毫无疑问的是,Boost 的参考价值是无法忽视的,你可以在 Boost 中找到许多非常值得学习和借鉴的实现。