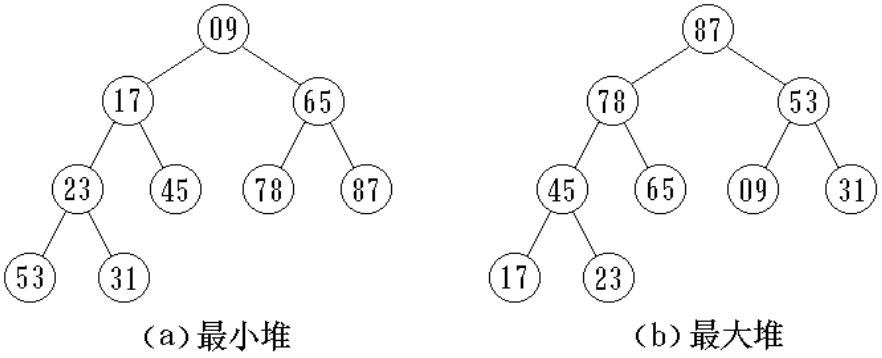
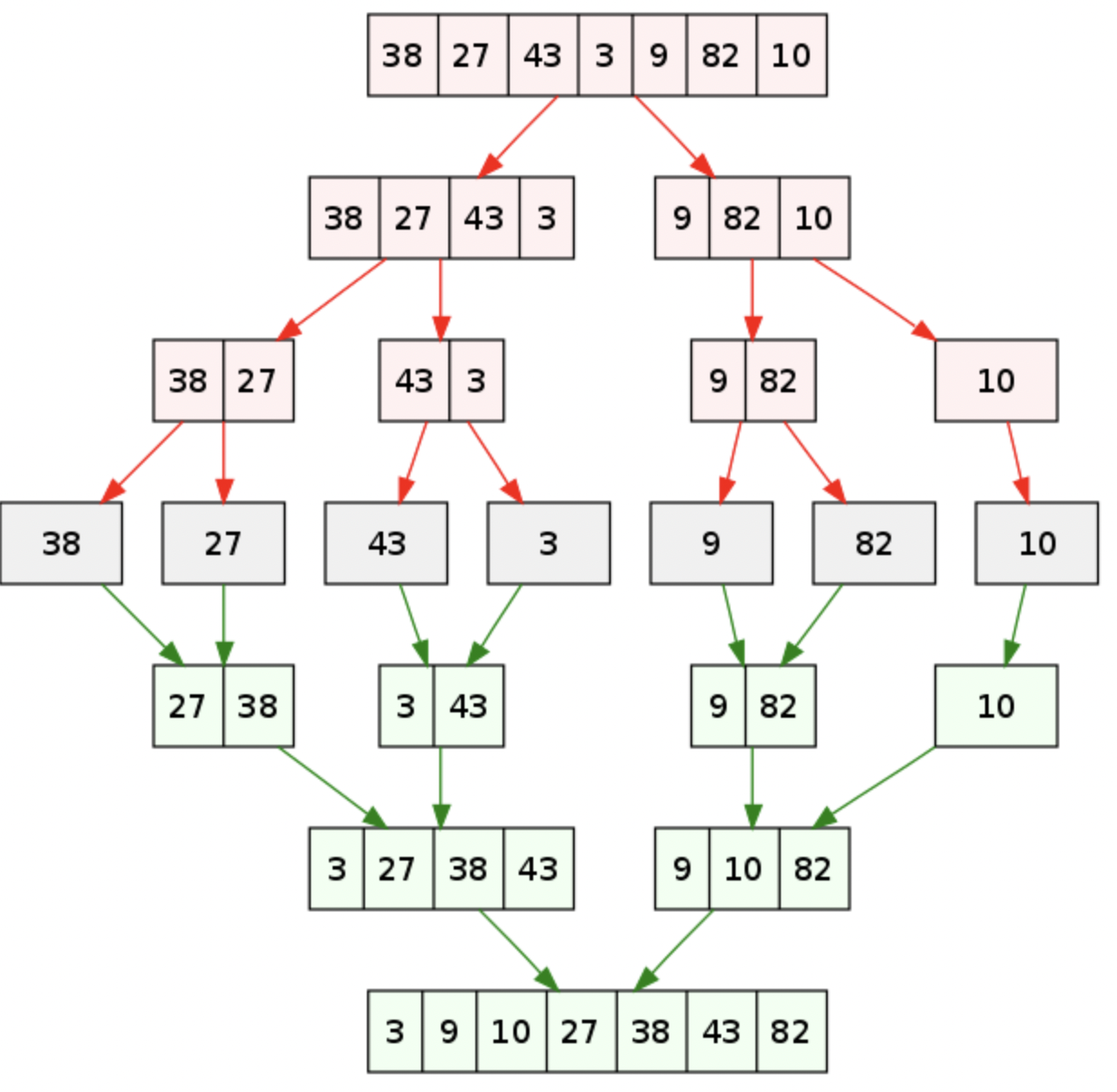
数据结构的定义
数据的逻辑结构
数据由多个数据元素(data element) 组成,而数据的逻辑结构(logical structure) 讨论的是数据元素之间的逻辑关系,一般可以用 “节点” 、“前驱” 、“后继” 等概念进行刻画。
一个逻辑结构可以在形式上被定义为二元组 B = ( D , R ) B = (D, R) B = ( D , R ) D D D R R R D D D r r r
设 a , b ∈ D a, b \in D a , b ∈ D ⟨ a , b ⟩ ∈ r \langle a, b \rangle \in r ⟨ a , b ⟩ ∈ r a a a b b b 前驱节点 ,称 b b b a a a 后继节点 ;如果不存在 a ∈ D a \in D a ∈ D ⟨ a , b ⟩ ∈ r \langle a, b \rangle \in r ⟨ a , b ⟩ ∈ r b b b 开始节点 ;如果不存在 b ∈ D b \in D b ∈ D ⟨ a , b ⟩ ∈ r \langle a, b \rangle \in r ⟨ a , b ⟩ ∈ r a a a 终端节点 ;既非开始节点又非终端节点的节点被称为内部节点 。
逻辑结构的分类:
数据的存储结构
数据及其逻辑关系在计算机中的存储方式称为数据的存储结构(storage structure) ,这是数据的逻辑结构在计算机中所需的存储空间 、空间的构成结构 以及对该存储结构的访问方式 等的总称。
数据的存储结构建立了一种由逻辑结构到存储结构的映射 :
建立节点集合 D D D M M M N → M N \rightarrow M N → M n ∈ N n \in N n ∈ N c ∈ M c \in M c ∈ M
将每一个关系元组 ⟨ a , b ⟩ ∈ r \langle a, b \rangle \in r ⟨ a , b ⟩ ∈ r
存储结构的分类:
顺序存储(sequential storage): 将一组节点存放在地址相邻的存储单元内,节点间的逻辑关系由存储单元的自然顺序关系来表达。
链接存储(linked storage): 通过在节点的存储结构中附加指针字段来存储节点间的逻辑关系,可以表达任意的逻辑关系。
索引存储(indexed storage) 将索引值映射到节点的存储地址,从而形成一个存储指针的索引表,可处理大小不等的数据节点。
散列存储(hash storage): 利用哈希函数(hash function) 进行索引值的计算,通过索引表求出节点的地址。
组合存储: 将以上 4 种基本存储结构灵活地组合使用,实现复杂逻辑结构地存储。
数据结构的操作
查找(search): 在数据种查找具有指定关键词值的数据元素(记录);插入(insert): 向数据种插入新的数据元素;删除(delete): 从数据中删除指定的数据元素;修改(modify): 修改指定数据元素某些数据项的值;排序(sort): 对数据中所有数据元素按关键词值升序或降序排列;遍历(traversal): 以某种方式访问数据中所有数据元素。
算法基本概念
算法的定义
一个算法就是一个有穷规则的集合,其中的规则规定了解决某一特定类型的一个运算序列。算法与数据结构密切相关,一方面算法设计依赖具体的数据结构,另一方面数据结构直接影响算法的执行效率。
算法的特性:
有限性: 每条指令都只能执行有限次,整个算法在有限时间内结束;确定性: 算法中的每条指令都必须明确,没有二义性;输入: 没有或具有多个输入;输出: 具有一个或多个输出;可行性: 算法的所有操作都是充分基本的,原则上仅由人用纸和笔在有限时间内也可以完成。
算法的评价准则:
正确性 可读性 时间复杂度 空间复杂度 健壮性(robustness): 对有缺失、噪声或错误的输入数据,算法有较强的应对能力。例如能对输入数据进行语法、语义检验,提出修改错误的建议并提供重新输入的机会等。
灵活性、可重用性、自适应性等也很重要。
最优算法: 在假定算法正确的前提下,一般用时间复杂度 作为评价算法优劣的标准。对于某一算法 A A A S A ( A ∈ S A ) S_A(A \in S_A) S A ( A ∈ S A ) A A A A A A
算法的正确性证明
反证法: 要证明定理 T T T T T T
与已知条件矛盾
与公理矛盾
与证明过的定理矛盾
自相矛盾
由此可以推断出定理 T T T
第一数学归纳法: 设 n n n T T T n n n T T T
基础归纳:n = c n = c n = c T T T
归纳步骤:假设 n = k − 1 n = k - 1 n = k − 1 T T T n = k n = k n = k T T T c c c n ≥ c n \geq c n ≥ c
第二数学归纳法(强归纳法):
基础归纳:n = c n = c n = c T T T
归纳步骤:假设 T T T n n n k ( c ≤ k < n ) k \ (c \leq k < n) k ( c ≤ k < n ) T T T n n n
算法的时间复杂度
设某领域问题的输入规模为 n n n D n D_n D n i ∈ D n i \in D_n i ∈ D n P ( i ) P(i) P ( i ) i i i ∑ P ( i ) = 1 \sum P(i) = 1 ∑ P ( i ) = 1 T ( i ) T(i) T ( i ) i i i
E ( n ) = ∑ { P ( i ) ⋅ T ( i ) } E(n) = \sum \{ P(i) \cdot T(i) \}
E ( n ) = ∑ { P ( i ) ⋅ T ( i )}
该算法在最坏情况下的复杂度为:
W ( n ) = max { T ( i ) } W(n) = \max \{ T(i) \}
W ( n ) = max { T ( i )}
该算法的最好复杂度为:
W ( n ) = min { T ( i ) } W(n) = \min \{ T(i) \}
W ( n ) = min { T ( i )}
复杂度函数的渐近表示法:
在很多情况下,特别当输入规模 n n n O O O Ω \Omega Ω Θ \Theta Θ
O \bm{O} O f ( n ) f(n) f ( n ) T ( n ) T(n) T ( n ) T ( n ) T(n) T ( n ) f ( n ) f(n) f ( n ) C C C n 0 n_0 n 0 n ≥ n 0 n \geq n_0 n ≥ n 0 T ( n ) ≤ C f ( n ) T(n) \leq C f(n) T ( n ) ≤ C f ( n )
T ( n ) = O ( f ( n ) ) T(n) = O(f(n))
T ( n ) = O ( f ( n ))
n n n O O O T T T f ( n ) f(n) f ( n ) T ( n ) T(n) T ( n ) f ( n ) f(n) f ( n )
T ( n ) = O ( f ( n ) ) ⟺ lim n → ∞ T ( n ) f ( n ) ≤ C T(n) = O(f(n)) \iff \lim_{n \rightarrow \infty} \frac{T(n)}{f(n)} \leq C
T ( n ) = O ( f ( n )) ⟺ n → ∞ lim f ( n ) T ( n ) ≤ C
O ( 1 ) O(1) O ( 1 )
O ( log 2 n ) O(\log_2 n) O ( log 2 n ) O ( n ) O(n) O ( n ) O ( n 2 ) O(n^2) O ( n 2 ) O ( n 3 ) O(n^3) O ( n 3 ) O ( n m ) O(n^m) O ( n m ) O ( 2 n ) O(2^n) O ( 2 n ) m ≥ 1 m \geq 1 m ≥ 1
Ω \bm{\Omega} Ω T ( n ) T(n) T ( n ) f ( n ) f(n) f ( n ) C C C n 0 n_0 n 0 n ≥ n 0 n \geq n_0 n ≥ n 0 T ( n ) ≥ C f ( n ) T(n) \geq C f(n) T ( n ) ≥ C f ( n )
T ( n ) = Ω ( f ( n ) ) T(n) = \Omega(f(n))
T ( n ) = Ω ( f ( n ))
Ω \Omega Ω T T T f ( n ) f(n) f ( n ) T ( n ) T(n) T ( n ) f ( n ) f(n) f ( n )
T ( n ) = Ω ( f ( n ) ) ⟺ lim n → ∞ T ( n ) f ( n ) ≥ C T(n) = \Omega(f(n)) \iff \lim_{n \rightarrow \infty} \frac{T(n)}{f(n)} \geq C
T ( n ) = Ω ( f ( n )) ⟺ n → ∞ lim f ( n ) T ( n ) ≥ C
Θ \bm{\Theta} Θ T ( n ) T(n) T ( n ) f ( n ) f(n) f ( n ) C 1 C_1 C 1 C 2 C_2 C 2 n 0 n_0 n 0 n ≥ n 0 n \geq n_0 n ≥ n 0 C 1 f ( n ) ≤ T ( n ) ≤ C 2 f ( n ) C_1 f(n) \leq T(n) \leq C_2 f(n) C 1 f ( n ) ≤ T ( n ) ≤ C 2 f ( n )
T ( n ) = Θ ( f ( n ) ) T(n) = \Theta(f(n))
T ( n ) = Θ ( f ( n ))
Θ \Theta Θ T T T T ( n ) T(n) T ( n ) f ( n ) f(n) f ( n )
T ( n ) = Θ ( f ( n ) ) ⟺ C 1 ≤ lim n → ∞ T ( n ) f ( n ) ≤ C 2 T(n) = \Theta(f(n)) \iff C_1 \leq \lim_{n \rightarrow \infty} \frac{T(n)}{f(n)} \leq C_2
T ( n ) = Θ ( f ( n )) ⟺ C 1 ≤ n → ∞ lim f ( n ) T ( n ) ≤ C 2
一个时间复杂度为 Θ ( f ( n ) ) \Theta(f(n)) Θ ( f ( n ))
例:三重循环
1 2 3 4 5 int s = 0 ;for (int i = 0 ; i <= n; ++i) for (int j = 0 ; j <= i; ++j) for (int k = 0 ; k < j; ++k) ++s;
以++s为基本运算,对每个 i i i ( j , k ) (j, k) ( j , k )
当 j = 0 j = 0 j = 0 0 0 0
当 j = 1 j = 1 j = 1 1 1 1
以此类推,当 j = i j = i j = i i i i
因此,对每个 i i i ( j , k ) (j, k) ( j , k ) i ⋅ i + 1 2 i \cdot \dfrac{i + 1}{2} i ⋅ 2 i + 1
T ( n ) = ∑ i = 0 n i ⋅ i + 1 2 = n ( n + 1 ) ( n + 2 ) 6 \begin{aligned}
T(n) &= \sum_{i = 0}^n i \cdot \frac{i + 1}{2}\\
&= \frac{n(n + 1)(n + 2)}{6}
\end{aligned} T ( n ) = i = 0 ∑ n i ⋅ 2 i + 1 = 6 n ( n + 1 ) ( n + 2 )
可得算法时间复杂度为 O ( n 3 ) O(n^3) O ( n 3 )
例:二分查找算法
1 2 3 4 5 6 7 8 9 10 11 12 13 int binarySearch (const std::vector<int >& nums, int target) int left = 0 , right = nums.size () - 1 ; while (left <= right) { int mid = left + (right - left) / 2 ; if (nums[mid] == target) return mid; else if (nums[mid] < target) left = mid + 1 ; else right = mid - 1 ; } return -1 ; }
在最好的情况下,二分查找的目标值恰好为序列的中间值,此时的时间复杂度为 O ( 1 ) O(1) O ( 1 ) 1 1 1 n 2 k = 1 \dfrac{n}{2^k} = 1 2 k n = 1 k = log 2 n k = \log_2 n k = log 2 n O ( log 2 n ) O(\log_2 n) O ( log 2 n )
算法的时空分析
一个算法在不同的执行时间内,它所占用的内存空间量不尽相同,占用的空间量 y y y x x x y = f ( x ) y = f(x) y = f ( x )
∫ 0 t f ( x ) d x \int_0^t f(x) \mathrm{d}x
∫ 0 t f ( x ) d x
为该算法的时空积分 ,其中 t t t
基于时空积分,可以比较算法优劣,时空积分较小的算法较优。
线性表(Linear list)
一个线性表是由零个或多个具有相同类型的节点组成的有序集合,通常用 ( a 1 , a 2 , ⋯ , a n ) (a_1, a_2, \cdots, a_n) ( a 1 , a 2 , ⋯ , a n ) n ≥ 0 n \geq 0 n ≥ 0 a k a_k a k 1 ≤ k ≤ n 1 \leq k \leq n 1 ≤ k ≤ n
当 n = 0 n = 0 n = 0 空表(empty list) ;
当 n > 1 n > 1 n > 1 a 1 a_1 a 1 头节点(head node) ,a n a_n a n 尾节点(tail node) ,a i a_i a i a i + 1 a_{i + 1} a i + 1 a i + 1 a_{i + 1} a i + 1 a i a_i a i 1 ≤ i < n 1 \leq i < n 1 ≤ i < n
当 n = 1 n = 1 n = 1 a 1 a_1 a 1
线性表的基本操作:
创建线性表;
确定线性表的长度;
判断线性表是否为空;
存取线性表中第 k k k
查找指定字段值在线性表中的位置;
删除线性表中第 k k k
在线性表第 k k k
归并、拆分、复制、排序等等。
线性表的顺序存储结构
按逻辑顺序将线性表中的节点依次存放在一组地址连续的存储单元中,称为顺序表(sequence list) ,它的特点是逻辑顺序与物理顺序相同。线性表的模板类定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 template <typename T>class SeqList {public : SeqList () = default ; SeqList (std::size_t length, std::size_t size, T value) : pData (new T[size]), size (size), length (length) { if (length > size) { std::cerr << "length 不能大于 size" << std::endl; return ; } for (std::size_t i = 0 ; i < length; ++i) { pData[i] = value; } } ~SeqList () { delete [] pData; } SeqList (const SeqList&); SeqList& operator =(const SeqList&); bool insert (std::size_t pos, const T& value) bool remove (std::size_t pos) ... private : T* pData{ nullptr }; std::size_t size{ 0 }; std::size_t length{ 0 }; };
顺序表的插入操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 template <typename T>bool SeqList<T>::insert (std::size_t pos, const T& value) { if (pos < 0 || pos >= length) { std::cerr << "不合法的输入" << std::endl; return false ; } if (length + 1 >= size) { auto pOrigin = pData; pData = new T[length + 1 ]; for (std::size_t i = 0 ; i < size; ++i) { pData[i] = pOrigin[i]; } delete [] pOrigin; ++size; } for (std::size_t i = length; i > pos; --i) { pData[i] = pData[i - 1 ]; } pData[pos] = value; ++length; return true ; }
插入操作的基本运算为移动元素。令线性表的长度为 n n n D n D_n D n n + 1 n + 1 n + 1 P ( i ) = 1 n + 1 P(i) = \dfrac{1}{n + 1} P ( i ) = n + 1 1
E ( n ) = n + ( n − 1 ) + ( n − 2 ) + ⋯ + 1 + 0 n + 1 + 1 = n 2 + 1 = O ( n ) E(n) = \frac{n + (n - 1) + (n - 2) + \cdots + 1 + 0}{n + 1} + 1 = \frac{n}{2} + 1 = O(n)
E ( n ) = n + 1 n + ( n − 1 ) + ( n − 2 ) + ⋯ + 1 + 0 + 1 = 2 n + 1 = O ( n )
顺序表的删除操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 template <typename T>bool SeqList<T>::remove (std::size_t pos) { if (pos < 0 || pos >= length) { std::cerr << "不合法的输入" << std::endl; return false ; } for (auto i = pos; i < length - 1 ; ++i) { pData[i] = pData[i + 1 ]; } --length; return true ; }
删除操作的基本运算为移动元素。令线性表的长度为 n n n D n D_n D n n n n P ( i ) = 1 n P(i) = \dfrac{1}{n} P ( i ) = n 1
E ( n ) = ( n − 1 ) + ( n − 2 ) + ⋯ + 1 + 0 n + 1 = n − 1 2 = O ( n ) E(n) = \frac{(n - 1) + (n - 2) + \cdots + 1 + 0}{n + 1} = \frac{n - 1}{2} = O(n)
E ( n ) = n + 1 ( n − 1 ) + ( n − 2 ) + ⋯ + 1 + 0 = 2 n − 1 = O ( n )
顺序表的优点:
空间利用率高,简单,易于实现;
可以随机访问表中的任意元素,存取速度快。
顺序表的缺点: 插入和删除节点时间复杂度高(需移动元素,调整一批节点的地址)。
线性表的链式存储结构
用任意一组存储单元存储线性表,一个存储单元除了包含节点数据字段,还必须存放其逻辑相邻节点的地址信息,即指针字段。这样的线性表称为链表(linked list) 。
当线性表需要经常执行插入、删除操作时,链表的时间复杂度较小,效率较高;
当线性表需要经常存取,且存取操作比插入、删除操作频繁的情况下,顺序表的时间复杂度较小,效率较高。
单链表
拥有头节点 、尾节点 和头指针 ;
利用链接域 实现线性表元素之间的逻辑关系。
为了对使对表头节点执行插入、删除等操作更加方便,有时会在表的前端增加一个特殊的表头节点,称为哨兵节点(sentinel node) ,但并不会将其看作表中的实际节点。
单链表的模板类定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 template <typename T>class LinkedList {public : struct Node { T data; Node* pNext{ nullptr }; }; LinkedList () : pHead (new Node) {} ~LinkedList () { Node* pNode = pHead; while (pNode != nullptr ) { auto pOrigin = pNode; pNode = pNode->pNext; delete pOrigin; } } LinkedList (const LinkedList&); LinkedList& operator =(const LinkedList&); Node* find (std::size_t pos) ; std::size_t search (const T& value) const ; bool insert (std::size_t pos, const T& value) bool remove (std::size_t pos) void reverse () ... private : Node* pHead; };
单链表的查找操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 template <typename T>typename LinkedList<T>::Node* LinkedList<T>::find (std::size_t pos) { if (pos < 0 ) { std::cerr << "不合法的输入" << std::endl; return nullptr ; } Node* pNode = pHead; std::size_t count = 0 ; while (pNode != nullptr && count < pos) { pNode = pNode->pNext; ++count; } if (pNode == nullptr ) { std::cerr << "未找到节点" << std::endl; } return pNode; } template <typename T>std::size_t LinkedList<T>::search (const T& value) const { Node* pNode = pHead->pNext; std::size_t count = 1 ; while (pNode != nullptr && pNode->data != value) { pNode = pNode->pNext; ++count; } if (pNode == nullptr ) { std::cerr << "未找到节点" << std::endl; return -1 ; } return count; }
令线性表的长度为 n n n p o s < 1 , p o s = 1 , ⋯ , p o s = n , p o s > n pos < 1, pos = 1, \cdots, pos = n, pos > n p os < 1 , p os = 1 , ⋯ , p os = n , p os > n P ( i ) = 1 n + 2 P(i) = \dfrac{1}{n + 2} P ( i ) = n + 2 1
0 + 1 + ⋯ + n + ( n + 1 ) n + 2 = n + 1 2 = O ( n ) \frac{0 + 1 + \cdots + n + (n + 1)}{n + 2} = \frac{n + 1}{2} = O(n)
n + 2 0 + 1 + ⋯ + n + ( n + 1 ) = 2 n + 1 = O ( n )
因此,查找算法在最好情况下的时间复杂度为 O ( 1 ) O(1) O ( 1 ) O ( n ) O(n) O ( n )
单链表的插入操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 template <typename T>bool LinkedList<T>::insert (std::size_t pos, const T& value) { if (pos < 0 ) { std::cerr << "不合法的输入" << std::endl; return false ; } if (pos == 0 ) { Node* pNew = new Node (); pNew->data = value; pNew->pNext = pHead; pHead = pNew; return true ; } Node* pNode = pHead; std::size_t count = 0 ; while (pNode != nullptr && count < pos - 1 ) { pNode = pNode->pNext; ++count; } if (pNode == nullptr ) { std::cerr << "不合法的输入" << std::endl; return false ; } Node* pNew = new Node (); pNew->data = value; pNew->pNext = pNode->pNext; pNode->pNext = pNew; return true ; }
插入算法在最好情况下的时间复杂度为 O ( 1 ) O(1) O ( 1 ) O ( n ) O(n) O ( n )
单链表的删除操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 template <typename T>bool LinkedList<T>::remove (std::size_t pos) { if (pos < 0 ) { std::cerr << "不合法的输入" << std::endl; return false ; } if (pos == 0 ) { Node* pOrigin = pHead; pHead = pHead->pNext; delete pOrigin; return true ; } Node* pNode = pHead; std::size_t count = 0 ; while (pNode->pNext != nullptr && count < pos - 1 ) { pNode = pNode->pNext; ++count; } if (pNode->pNext == nullptr ) { std::cerr << "不合法的输入" << std::endl; return false ; } Node* pOrigin = pNode->pNext; pNode->pNext = pOrigin->pNext; delete pOrigin; return true ; }
删除算法在最好情况下的时间复杂度为 O ( 1 ) O(1) O ( 1 ) O ( n ) O(n) O ( n )
就地逆置法反转单链表:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 template <typename T>void LinkedList<T>::reverse () { if (pHead == nullptr || pHead->pNext == nullptr ){ return ; } Node* pBeg = pHead; Node* pEnd = pHead->pNext; while (pEnd != nullptr ) { pBeg->pNext = pEnd->pNext; pEnd->pNext = pHead; pHead = pEnd; pEnd = pBeg->pNext; } }
链表反转算法的时间复杂度为 O ( n ) O(n) O ( n )
单链表的优点:
单链表的缺点:
不能进行随机访问,只有从头节点开始才能访问链表中的全部节点;
从一个节点出发,只能访问到链接在它后面的节点,而无法访问位于前面的节点。
静态单链表: 一种借助数组来实现的线性链表,它将数据元素可能的存储范围局限于一维数组内,在数组内数据元素可以随意存放,即逻辑结构和存储结构不相同。
在静态单链表中,对于一个数据元素,除了需要存储该元素的值以外,还需要存储其直接后继在一维数组中的下标。
循环链表
将链接结构 “循环化”,即让尾节点的pNext指针指向头节点(或哨兵节点),而不是存放空指针。
循环链表使我们可以从链表的任何位置开始,访问链表中的任意节点。
缺点:在循环链表中访问某节点的前驱节点,需要遍历整个链表,时间复杂度为 O ( n ) O(n) O ( n )
双向链表
每个节点有两个指针域pPre和pNext,左指针指向前驱节点,右指针指向后继节点。
头节点的pPre指针和尾节点的pNext指针均为空指针。
在需要经常查找节点的前驱和后继的场合,使用双向链表比较合适。
将单链表中的节点数据进行修改:
1 2 3 4 5 struct Node { T data; Node* pPre{ nullptr }; Node* pNext{ nullptr }; };
双向链表的插入操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 template <typename T>bool LinkedList<T>::insert (std::size_t pos, const T& value) { if (pos < 0 ) { std::cerr << "不合法的输入" << std::endl; return false ; } if (pos == 0 ) { Node* pNew = new Node (); pNew->data = value; pNew->pNext = pHead; pHead->pPre = pNew; pHead = pNew; return true ; } Node* pNode = pHead; std::size_t count = 0 ; while (pNode != nullptr && count < pos - 1 ) { pNode = pNode->pNext; ++count; } if (pNode == nullptr ) { std::cerr << "不合法的输入" << std::endl; return false ; } Node* pNew = new Node (); pNew->data = value; if (pNode->pNext == nullptr ) { pNew->pPre = pNode; pNode->pNext = pNew; return true ; } pNew->pNext = pNode->pNext; pNew->pPre = pNode; pNode->pNext->pPre = pNew; pNode->pNext = pNew; return true ; }
双向链表的删除操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 template <typename T>bool LinkedList<T>::remove (std::size_t pos) { if (pos < 0 ) { std::cerr << "不合法的输入" << std::endl; return false ; } if (pos == 0 ) { delete pHead; pHead = nullptr ; return true ; } if (pos == 0 ) { Node* pOrigin = pHead; pHead = pHead->pNext; pHead->pPre = nullptr ; delete pOrigin; return true ; } Node* pNode = pHead; std::size_t count = 0 ; while (pNode->pNext != nullptr && count < pos - 1 ) { pNode = pNode->pNext; ++count; } if (pNode->pNext == nullptr ) { std::cerr << "不合法的输入" << std::endl; return false ; } Node* pOrigin = pNode->pNext; if (pOrigin->pNext == nullptr ) { pNode->pNext = nullptr ; delete pOrigin; return true ; } pNode->pNext = pOrigin->pNext; pOrigin->pNext->pPre = pNode; delete pOrigin; return true ; }
特殊的线性表:堆栈
堆栈(stack,简称栈) 是插入和删除操作只能在同一端进行的线性表,并按后进先出 的原则进行操作。执行插入和删除操作的一端称为栈顶 ,其另一端称为栈底 ;当表中没有元素时,称为空栈 。
栈的优点:
除了栈顶元素外,其他元素都不会被改变,因此栈的封闭性很好,使用起来很安全;
可以对输入序列部分或全局求逆,且任何符合后进先出特性的算法都可以用栈来实现,如十进制数与其它数制的转换,递归的实现,算数表达式求值等问题。
栈的基本操作:
创建栈;
入栈(push);
出栈(pop);
读取栈顶元素(peek);
判断栈是否为空;
判断栈是否为满;
将栈置空(clear)。
顺序栈
使用数组来存放栈元素,优点是效率高,缺点是若同时使用多个栈,将浪费大量空间。顺序栈的模板类定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 template <typename T>class SeqStack {public : SeqStack () = default ; SeqStack (std::size_t size) : pData (new T[size]), size (size) {} ~SeqStack () { delete [] pData; } SeqStack (const SeqStack&); SeqStack& operator =(const SeqStack&); bool push (const T& value) bool pop (T& value) bool peek (T& value) const bool empty () const return top == -1 ; } private : T* pData{ nullptr }; std::size_t top{ -1 }; std::size_t size{ 0 }; };
查看栈顶元素:
1 2 3 4 5 6 7 8 9 10 template <typename T>bool SeqStack<T>::peek (T& value) const { if (empty ()) { std::cerr << "空栈无法查看栈顶元素" << std::endl; return false ; } value = pData[top]; return true ; }
入栈操作:
1 2 3 4 5 6 7 8 9 10 11 template <typename T>bool SeqStack<T>::push (const T& value) { if (top + 1 >= size) { std::cerr << "栈满无法压入" << std::endl; return false ; } ++top; pData[top] = value; return true ; }
出栈操作:
1 2 3 4 5 6 7 8 9 10 11 template <typename T>bool SeqStack<T>::pop (T& value) { if (empty ()) { std::cerr << "空栈无法弹出" << std::endl; return false ; } value = pData[top]; --top; return true ; }
双向栈: 假设两个栈共享一个数组stack[maxnum],则可以利用栈的 “栈底位置不变,栈顶位置动态变化” 的特性,将两个栈底分别设为 1 和maxnum,而它们的栈顶都向中间延伸。
因此,只要整个数组stack[maxnum]未被沾满,则无论哪个栈在入栈时都不会发生上溢。
链式栈
用单链表来实现堆栈,需要为每个栈元素分配一个额外的指针空间,并使栈顶对应头节点,这样每次操作的时间复杂度均为 O ( 1 ) O(1) O ( 1 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 template <typename T>class LinkedStack {public : struct Node { T data; Node* pNext{ nullptr }; }; LinkedStack () = default ; ~LinkedStack () { Node* pNode = pTop; while (pNode != nullptr ) { auto pOrigin = pNode; pNode = pNode->pNext; delete pOrigin; } } LinkedStack (const LinkedStack&); LinkedStack& operator =(const LinkedStack&); void push (const T& value) bool pop (T& value) bool peek (T& value) const bool empty () const return pTop == nullptr ; } ... private : Node* pTop{ nullptr }; };
查看栈顶元素:
1 2 3 4 5 6 7 8 9 10 template <typename T>bool LinkedStack<T>::peek (T& value) const { if (empty ()) { std::cerr << "空栈无法查看栈顶元素" << std::endl; return false ; } value = pTop->data; return true ; }
入栈操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 template <typename T>void LinkedStack<T>::push (const T& value) { if (empty ()) { pTop = new Node (); pTop->data = value; return ; } Node* pNew = new Node (); pNew->data = value; pNew->pNext = pTop; pTop = pNew; }
出栈操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 template <typename T>bool LinkedStack<T>::pop (T& value) { if (empty ()) { std::cerr << "空栈无法弹出" << std::endl; return false ; } value = pTop->data; Node* pOrigin = pTop; pTop = pTop->pNext; delete pOrigin; return true ; }
算术表达式求值
中缀表达式: 运算符在操作数之间。
运算规则:
先计算括号内,再计算括号外;
乘除运算的优先级高于加减运算;
同一优先级运算,从左向右一次进行。
后缀表达式(逆波兰式): 运算符紧跟在两个操作数之后。
运算规则:
后缀表达式没有括号;
不存在优先级的差别;
计算过程完全按照运算符出现的先后顺序进行。
后缀表达式求值的方法:
从左到右读入后缀表达式,若读到的是操作数,则将其压入栈中;
若读到的是运算符,则从栈中连续弹出两个元素(操作数),先弹出的在运算符右边,后弹出的在运算符左边,进行运算后将结果压入栈中;
计算结束后,栈顶元素即为计算结果。
中缀表达式转换为后缀表达式的方法:
初始化一个运算符栈。
从左到右读入中缀表达式,若读到的是操作数,则直接连接到后缀表达式末尾。
若读到的是运算符,则和运算符栈栈顶的操作符进行比较:如果优先级比栈顶运算符高,则入栈;如果优先级比栈顶运算符低,则将栈顶的运算符出栈后连接到后缀表达式末尾。
若读到的是左括号,则直接入栈;若读到的是右括号,则弹出栈中第一个左括号前所有的操作符,同时将左括号弹出。
重复以上过程直到遇到结束符。
中缀表达式直接求值的方法:
初始化一个操作数栈和一个运算符栈。
从左到右读入中缀表达式,若读到的是操作数,则将其压入操作数栈中。
若读到的是运算符,则和运算符栈栈顶的操作符进行比较:如果优先级比栈顶运算符高,则入栈;如果优先级比栈顶运算符低,则弹出栈顶运算符,再从操作数栈中弹出 2 个操作数,对其进行运算,将结果压入操作数栈中。
若读到的是左括号,则直接入栈;若读到的是右括号,则弹出栈中第一个左括号前所有的运算符,每次同时弹出 2 个操作数进行运算,并将结果压入操作数栈中,最后将左括号弹出。
重复以上过程直到遇到结束符,若此时操作数栈不为空,则将所有操作符弹出,进行和上面相同的运算操作,最终栈顶元素即为计算结果。
特殊的线性表:队列
队列(queue) 是插入操作在一端进行而删除操作在另一端进行的线性表,并按先进先出 的原则进行操作。执行删除操作的一端称为队首(front) ,执行插入操作的一端称为队尾(rear) ;当表中没有元素时,称为空队列 。
队列的优点:
和栈类似,队列的封闭性也非常好,使用起来很安全;
可以对输入序列起到缓冲作用,且任何符合先进先出特性的算法都可以用队列来实现,如操作系统中的作业调度,图的广度优先搜索等问题。
队列的基本操作:
创建队列;
入队(插入);
出队(删除);
读取队首元素;
判断队列是否为空;
确定队列中的元素个数。
将队列置空。
顺序队列
使用普通的顺序存储结构会导致队列很容易出现假溢出 现象,这是因为顺序队列执行队头出队、队尾入队,会造成数组前面会出现空闲单元未被充分利用,而使用循环队列 则可以避免这个问题。
采用环状模型来实现队列(循环队列):
front指向队首位置,删除一个元素就将front顺时针移动一位;rear指向元素要插入的位置,插入一个元素就将rear顺时针移动一位;count代表队列中元素的个数,当count等于size时,就无法再向队列中插入元素。
顺序队列的模板类定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 template <typename T>class SeqQueue {public : SeqQueue () = default ; SeqQueue (std::size_t size) : pData (new T[size]), size (size) {} ~SeqQueue () { delete [] pData; } SeqQueue (const SeqQueue&); SeqQueue& operator =(const SeqQueue&); bool push (const T& value) bool pop (T& value) bool peek (T& value) const bool empty () const return count == 0 ; } ... private : T* pData{ nullptr }; std::size_t front{ 0 }; std::size_t rear{ 0 }; std::size_t count{ 0 }; std::size_t size{ 0 }; };
查看队首元素:
1 2 3 4 5 6 7 8 9 10 template <typename T>bool SeqQueue<T>::peek (T& value) const { if (empty ()) { std::cerr << "空队列无法查看队首元素" << std::endl; return false ; } value = pData[front]; return true ; }
循环队列的入队操作:
1 2 3 4 5 6 7 8 9 10 11 12 template <typename T>bool SeqQueue<T>::push (const T& value) { if (count == size) { std::cerr << "队列已满无法插入" << std::endl; return false ; } pData[rear] = value; rear = (rear + 1 ) % size; ++count; return true ; }
循环队列的出队操作:
1 2 3 4 5 6 7 8 9 10 11 12 template <typename T>bool SeqQueue<T>::pop (T& value) { if (empty ()) { std::cerr << "空队列无法删除" << std::endl; return false ; } value = pData[front]; front = (front + 1 ) % size; --count; return true ; }
链式队列
链式队列的模板类定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 template <typename T>class LinkedQueue {public : struct Node { T data; Node* pNext{ nullptr }; }; LinkedQueue () = default ; ~LinkedQueue () { Node* pNode = pFront; while (pNode != nullptr ) { auto pOrigin = pNode; pNode = pNode->pNext; delete pOrigin; } } LinkedQueue (const LinkedQueue&); LinkedQueue& operator =(const LinkedQueue&); void push (const T& value) bool pop (T& value) bool peek (T& value) const bool empty () const return pFront == nullptr ; } private : Node* pFront{ nullptr }; Node* pRear{ nullptr }; };
查看队首元素:
1 2 3 4 5 6 7 8 9 10 template <typename T>bool LinkedQueue<T>::peek (T& value) const { if (empty ()) { std::cerr << "空队列无法查看队首元素" << std::endl; return false ; } value = pFront->data; return true ; }
链式队列的入队操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 template <typename T>void LinkedQueue<T>::push (const T& value) { Node* pNew = new Node (); pNew->data = value; if (pFront == nullptr ) { pFront = pNew; } else { pRear->pNext = pNew; } pRear = pNew; }
链式队列的出队操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 template <typename T>bool LinkedQueue<T>::pop (T& value) { if (empty ()) { std::cerr << "空队列无法删除" << std::endl; return false ; } Node* pOrigin = pFront; value = pOrigin->data; pFront = pFront->pNext; delete pOrigin; if (pFront == nullptr ) { pRear = nullptr ; } return true ; }
双端队列(double ended queue,简称 deque): 同样是一个操作受限的线性表,限制只能再表的端点处进行插入和删除操作,但是它允许插入和删除操作可以在表的任意一端执行。
递归
递归不仅是数学中的一个概念,也是计算技术的重要方法之一。递归算法的设计实际上就是对问题进行抽象的过程,当抽象到每个小问题都有相同的特征时,就形成了递归。
从方法论意义上来说,递归是一种从简单到复杂,从低级到高级的可连续操作的解决问题的方法,在人们的思维过程中,普遍存在递归现象和递归机制。
递归的定义
如果一个对象部分地包含自己,或者利用自己定义自己的方式来进行描述,则称这个对象是递归的 ;如果一个过程直接或间接地调用自己,则称这个过程是一个递归过程 ;直接调用自身的递归过程称为直接递归 ,调用另一个过程并最终调用原过程的递归过程称为间接递归 。
一个递归过程由递归调用 和递归终止条件 构成。
分治策略(divide and conquer strategy): 对于一个比较复杂的问题,如果能把它分解为若干个相对简单的,解法相同或类似的子问题,那么当这些子问题都被解决时,原问题也就得到了解决。
以下三种问题适用于递归求解:
问题的定义是递归的;
问题所涉及的数据结构是递归的;
问题的解法满足递归的性质。
对于递归算法的正确性,通常采用数学归纳法证明;对于递归算法的时间复杂度分析,通常先定义其时间复杂度的递归数学表达式,然后求解该递归公式。
问题的定义是递归的: 如计算阶乘,幂函数和斐波那契数列等。
例: 写出求解阶乘函数的递归过程。
1 2 3 4 5 6 uint64_t factorial (uint64_t n) if (n == 0 ) return 1 ; else return n * factorial (n - 1 ); }
问题所涉及的数据结构是递归的: 如链表,树等数据结构。
例: 将两个升序链表合并为一个新的升序链表并返回,新链表是通过拼接给定的两个链表的所有节点组成的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Node* mergeTwoLists (Node* pList1, Node* pList2) { if (pList1 == nullptr ) return pList2; if (pList2 == nullptr ) return pList1; if (pList1->data <= pList2->data) { pList1->pNext = mergeTwoLists (pList1->pNext, pList2); return pList1; } pList2->pNext = mergeTwoLists (pList1, pList2->pNext); return pList2; }
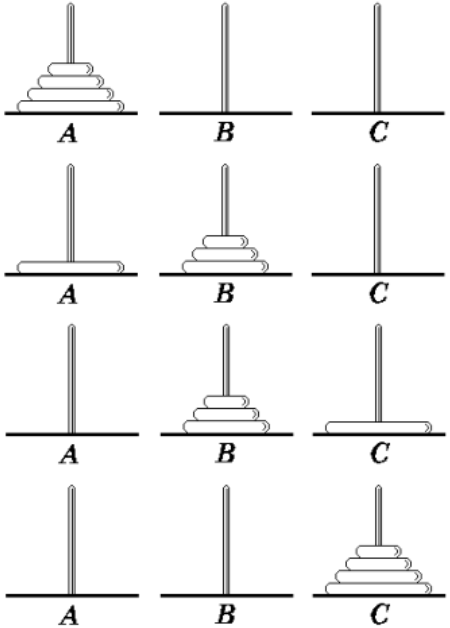
问题的解法满足递归的性质: 如汉诺塔问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void hanoi (int n, std::string a, std::string b, std::string c) if (n == 1 ) { std::cout << "move " << a << " to " << c << std::endl; } else { hanoi (n - 1 , a, c, b); std::cout << "move " << a << " to " << c << std::endl; hanoi (n - 1 , b, a, c); } }
基本递归过程
递归调用由外部调用和内部调用组成,通过外部调用开启一个递归过程,通过内部调用划分子任务。在高级语言中,递归调用是通过递归工作栈 来实现的,调用时执行入栈操作来保存现场,返回时执行出栈操作来恢复现场。
递归过程实现的基本思想:
产生新的子任务,对应入栈操作;
处理子任务对应出栈操作;
先处理的子任务后入栈;
后处理的子任务先入栈;
最后一次发生的递归过程必须最先完成。
例: 利用非递归方法解决汉诺塔问题:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 void hanoi (int n, std::string a, std::string b, std::string c) using StackData = std::tuple<int , std::string, std::string, std::string>; std::stack<StackData> hanoiStack; hanoiStack.push (StackData (n, a, b, c)); while (!hanoiStack.empty ()) { auto stackData = hanoiStack.top (); hanoiStack.pop (); auto n = std::get <0 >(stackData); auto a = std::get <1 >(stackData); auto b = std::get <2 >(stackData); auto c = std::get <3 >(stackData); if (n == 1 ) { std::cout << "move " << a << " to " << c << std::endl; } else { hanoiStack.push (StackData (n - 1 , b, a, c)); hanoiStack.push (StackData (1 , a, b, c)); hanoiStack.push (StackData (n - 1 , a, c, b)); } } }
递归的效率
递归算法的优点:
递归过程结构清晰;
递归程序可读性强,易于编写;
正确性证明相对容易。
递归算法的缺点:
函数调用空间开销大;
会出现重复计算,运行效率低。
数组与字符串
数组
数组是线性表的推广,采用顺序存储。一维数组是若干个元素的有限序列,元素本身就是一个数据结构;数组的元素必须具有相同类型,每个数组元素都占据相同大小的存储空间。
数组的每个元素都通过一个下标来指定,故一个一维数组对应一个下标函数。
一维数组的寻址公式: a [ n ] a[n] a [ n ] C C C
l o c ( a [ i ] ) = l o c ( a [ 0 ] ) + i ⋅ C loc(a[i]) = loc(a[0]) + i \cdot C
l oc ( a [ i ]) = l oc ( a [ 0 ]) + i ⋅ C
二维数组的寻址公式: a [ n ] [ m ] a[n][m] a [ n ] [ m ]
行优先存储:
l o c ( a [ i ] [ j ] ) = l o c ( a [ 0 ] [ 0 ] ) + i ⋅ n ⋅ C + j ⋅ C = l o c ( a [ 0 ] [ 0 ] ) + ( i ⋅ n + j ) ⋅ C \begin{aligned}
loc(a[i][j]) &= loc(a[0][0]) + i \cdot n \cdot C + j \cdot C\\
&= loc(a[0][0]) + (i \cdot n + j) \cdot C
\end{aligned} l oc ( a [ i ] [ j ]) = l oc ( a [ 0 ] [ 0 ]) + i ⋅ n ⋅ C + j ⋅ C = l oc ( a [ 0 ] [ 0 ]) + ( i ⋅ n + j ) ⋅ C
列优先存储:
l o c ( a [ i ] [ j ] ) = l o c ( a [ 0 ] [ 0 ] ) + j ⋅ m ⋅ C + i ⋅ C = l o c ( a [ 0 ] [ 0 ] ) + ( j ⋅ m + i ) ⋅ C \begin{aligned}
loc(a[i][j]) &= loc(a[0][0]) + j \cdot m \cdot C + i \cdot C\\
&= loc(a[0][0]) + (j \cdot m + i) \cdot C
\end{aligned} l oc ( a [ i ] [ j ]) = l oc ( a [ 0 ] [ 0 ]) + j ⋅ m ⋅ C + i ⋅ C = l oc ( a [ 0 ] [ 0 ]) + ( j ⋅ m + i ) ⋅ C
三维数组的寻址公式: a [ n ] [ m ] [ p ] a[n][m][p] a [ n ] [ m ] [ p ]
行优先存储:
l o c ( a [ i ] [ j ] [ k ] ) = l o c ( a [ 0 ] [ 0 ] [ 0 ] ) + ( i ⋅ n ⋅ p + j ⋅ p + k ) ⋅ C loc(a[i][j][k]) = loc(a[0][0][0]) + (i \cdot n \cdot p + j \cdot p + k) \cdot C
l oc ( a [ i ] [ j ] [ k ]) = l oc ( a [ 0 ] [ 0 ] [ 0 ]) + ( i ⋅ n ⋅ p + j ⋅ p + k ) ⋅ C
列优先存储:
l o c ( a [ i ] [ j ] [ k ] ) = l o c ( a [ 0 ] [ 0 ] [ 0 ] ) + ( k ⋅ m ⋅ n + j ⋅ m + i ) ⋅ C loc(a[i][j][k]) = loc(a[0][0][0]) + (k \cdot m \cdot n + j \cdot m + i) \cdot C
l oc ( a [ i ] [ j ] [ k ]) = l oc ( a [ 0 ] [ 0 ] [ 0 ]) + ( k ⋅ m ⋅ n + j ⋅ m + i ) ⋅ C
高维数组的寻址公式: a [ m 1 ] [ m 2 ] ⋯ [ m n ] a[m_1][m_2]\cdots[m_n] a [ m 1 ] [ m 2 ] ⋯ [ m n ]
行优先存储:
l o c ( a [ i 1 ] ⋯ [ i n ] ) = l o c ( a [ 0 ] ⋯ [ 0 ] ) + [ ∑ k = 1 n − 1 ( i k ⋅ ∏ p = k + 1 n m p ) + i n ] ⋅ C loc(a[i_1]\cdots[i_n]) = loc(a[0]\cdots[0]) + \left[ \sum_{k = 1}^{n - 1}\left( i_k \cdot \prod_{p = k + 1}^n m_p \right) + i_n \right] \cdot C
l oc ( a [ i 1 ] ⋯ [ i n ]) = l oc ( a [ 0 ] ⋯ [ 0 ]) + k = 1 ∑ n − 1 i k ⋅ p = k + 1 ∏ n m p + i n ⋅ C
列优先存储:
l o c ( a [ i 1 ] ⋯ [ i n ] ) = l o c ( a [ 0 ] ⋯ [ 0 ] ) + [ ∑ k = 2 n ( i k ⋅ ∏ p = 1 k − 1 m p ) + i 1 ] ⋅ C loc(a[i_1]\cdots[i_n]) = loc(a[0]\cdots[0]) + \left[ \sum_{k = 2}^{n}\left( i_k \cdot \prod_{p = 1}^{k - 1} m_p \right) + i_1 \right] \cdot C
l oc ( a [ i 1 ] ⋯ [ i n ]) = l oc ( a [ 0 ] ⋯ [ 0 ]) + [ k = 2 ∑ n ( i k ⋅ p = 1 ∏ k − 1 m p ) + i 1 ] ⋅ C
高维数组在内存中按行优先的排列顺序为:第一维的下标变化最慢,最高维的下标变化最快。
矩阵
二维数组和矩阵相比:
数组的基本操作是加减,而矩阵的基本操作还有矩阵乘法、转置等。
数组的下标从 0 开始,而矩阵的下标一般从 1 开始。
数组元素用a[i][j]表示,而矩阵元素一般用a(i, j)表示。
一维数组实现矩阵乘法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 template <typename T>class Matrix {public : Matrix (int rows, int columns) : rows (rows), columns (columns), data (rows * columns) {} T& operator () (int i, int j) { return data[(i - 1 ) * rows + j - 1 ]; } const T& operator () (int i, int j) const return data[(i - 1 ) * rows + j - 1 ]; } const Matrix operator *(const Matrix& rhs) const { Matrix result (rows, rhs.columns) ; for (int i = 1 ; i <= rows; ++i) { for (int j = 1 ; j <= rhs.columns; ++j) { result (i, j) = 0 ; for (int k = 1 ; k <= columns; ++k) { result (i, j) += operator ()(i, k) * rhs (k, j); } } } return result; } ... private : std::vector<T> data; int rows, columns; };
对于两个矩阵 A m × p A_{m \times p} A m × p B p × n B_{p \times n} B p × n O ( m × n × p ) O(m \times n \times p) O ( m × n × p )
特殊矩阵的压缩存储:
对于特殊矩阵,如对称矩阵、三角矩阵、对角矩阵和稀疏矩阵等,如果用一维数组来实现,那么就会浪费大量存储空间存放重复信息或零元素。为了节省存储空间,提高算法效率,一般会采用压缩存储。
对角矩阵: 对于一个 n × n n \times n n × n n n n n n n d[n]来压缩存储对角矩阵,其中d[i - 1]存储M(i, i)的值。
三角矩阵: 以下三角矩阵为例,需要存储 n ( n + 1 ) 2 \dfrac{n(n + 1)}{2} 2 n ( n + 1 ) d[k]对应M(i, j)的值,其公式为:
k = 1 + 2 + ⋯ + ( i − 1 ) + ( j − 1 ) = i ( i − 1 ) 2 + ( j − 1 ) k = 1 + 2 + \cdots + (i - 1) + (j - 1) = \frac{i(i - 1)}{2} + (j - 1)
k = 1 + 2 + ⋯ + ( i − 1 ) + ( j − 1 ) = 2 i ( i − 1 ) + ( j − 1 )
对称矩阵: 需要存储 n ( n + 1 ) 2 \dfrac{n(n + 1)}{2} 2 n ( n + 1 )
i ≥ j i \geq j i ≥ j d [ k ] d[k] d [ k ] k = i ( i − 1 ) 2 + ( j − 1 ) k = \dfrac{i(i - 1)}{2} + (j - 1) k = 2 i ( i − 1 ) + ( j − 1 ) i < j i < j i < j d [ q ] d[q] d [ q ] q = j ( j − 1 ) 2 + ( i − 1 ) q = \dfrac{j(j - 1)}{2} + (i - 1) q = 2 j ( j − 1 ) + ( i − 1 )
稀疏矩阵
矩阵中非零元素的个数远远小于零元素的个数,且非零元素的分布没有规律,无法简单地通过一维数组和映射公式来实现压缩存储。
矩阵的每个非零元素可以通过一个三元组节点 ( i , j , a i j ) (i, j, a_{ij}) ( i , j , a ij )
三元组表: 将三元组节点按行优先的顺序排列,得到一个线性表,将此线性表用顺序存储结构进行存储,称为三元组表。注意在录入元素时,需要按照先行后列的升序顺序进行录入。
用三元组表实现稀疏矩阵的演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 template <typename T>class SparseMatrix {public : struct Node { T data; int row{ 0 }; int column{ 0 }; }; SparseMatrix (int rows, int columns) : rows (rows), columns (columns) {} SparseMatrix (int rows, int columns, std::size_t count) : SparseMatrix (rows, columns) { nodes.reserve (count); } T& operator () (int i, int j) { for (auto & node : nodes) { if (node.row == i && node.column == j) return node.data; } Node node; node.row = i; node.column = j; nodes.emplace_back (node); return nodes.back ().data; } const T operator () (int i, int j) const return at (i, j); } const T at (int i, int j) const for (const auto & node : nodes) { if (node.row == i && node.column == j) return node.data; } return T (); } SparseMatrix transpose () const ; ... private : std::vector<Node> nodes; int rows, columns; };
三元组表的转置算法(时间复杂度为 O ( n × t ) O(n \times t) O ( n × t )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 template <typename T>SparseMatrix<T> SparseMatrix<T>::transpose () const { SparseMatrix result (columns, rows) ; result.nodes.resize (nodes.size ()); std::size_t index = 0 ; for (int j = 1 ; j <= rows; ++j) { for (const auto & node : nodes) { if (node.column == j) { result.nodes[index].data = node.data; result.nodes[index].row = node.column; result.nodes[index].column = node.row; ++index; } } } return result; }
三元组表的快速转置算法(时间复杂度为 O ( n + t ) O(n + t) O ( n + t )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 template <typename T>SparseMatrix<T> SparseMatrix<T>::transpose () const { auto maxSize = nodes.size (); std::vector<int > num (columns) ; std::vector<int > pos (columns) ; for (std::size_t i = 0 ; i < maxSize; ++i) ++num[nodes[i].column - 1 ]; pos[0 ] = 0 ; for (int i = 1 ; i < columns; ++i) pos[i] = pos[i - 1 ] + num[i - 1 ]; SparseMatrix result (columns, rows) ; result.nodes.resize (maxSize); for (const auto & node : nodes) { auto col = node.column - 1 ; result.nodes[pos[col]].data = node.data; result.nodes[pos[col]].row = node.column; result.nodes[pos[col]].column = node.row; ++pos[col]; } return result; }
可以看出,三元组表不适合用于非零元的位置或个数需要经常发生变化的矩阵运算。
十字链表: 在节点中存储三元组的同时,存储指向右邻非零元素和下邻非零元素的指针;矩阵的每一行、每一列都设为由一个表头节点引导的循环链表,并将表头节点用顺序存储结构进行存储。
用十字链表实现稀疏矩阵的演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 template <typename T>class SparseMatrix {public : class Node { public : Node (int row, int column, T data) : row (row), column (column), data (data) {} T data; int row{ 0 }; int column{ 0 }; Node* pRight{ nullptr }; Node* pDown{ nullptr }; }; SparseMatrix (int rows, int columns) : rows (rows), columns (columns), rhead (rows), chead (columns) {} ~SparseMatrix () { for (auto & pNode : rhead) { while (pNode) { Node* pNext = pNode->pRight; delete pNode; pNode = pNext; } } } void insert (int i, int j, T data) const SparseMatrix operator +(const SparseMatrix&) const ; ... private : std::vector<Node*> rhead; std::vector<Node*> chead; int rows{ 0 }; int columns{ 0 }; std::size_t count{ 0 }; };
实现十字链表插入元素:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 template <typename T>void SparseMatrix<T>::insert (int i, int j, T data) { Node* pNew = new Node (i, j, data); ++count; if (rhead[i] == nullptr || rhead[i]->column > j) { pNew->pRight = rhead[i]; rhead[i] = pNew; } else { Node* pNode = rhead[i]; while (pNode->pRight != nullptr && pNode->pRight->column < j) pNode = pNode->pRight; pNew->pRight = pNode->pRight; pNode->pRight = pNew; } if (chead[j] == nullptr || chead[j]->row > i) { pNew->pDown = chead[j]; chead[j] = pNew; } else { Node* pNode = chead[j]; while (pNode->pDown && pNode->pDown->row < i) pNode = pNode->pDown; pNew->pDown = pNode->pDown; pNode->pDown = pNew; } }
十字链表实现稀疏矩阵的加法操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 template <typename T>const SparseMatrix<T> SparseMatrix<T>::operator +(const SparseMatrix& rhs) const { SparseMatrix<T> result (rows, columns) ; for (int i = 0 ; i < rows; ++i) { Node* p1 = rhead[i]; Node* p2 = rhs.rhead[i]; while (p1 != nullptr && p2 != nullptr ) { if (p1->column == p2->column) { auto sum = p1->data + p2->data; if (sum != 0 ) result.insert (i, p1->column, sum); p1 = p1->pRight; p2 = p2->pRight; } else if (p1->column < p2->column) { result.insert (i, p1->column, p1->data); p1 = p1->pRight; } else { result.insert (i, p2->column, p2->data); p2 = p2->pRight; } } while (p1 != nullptr ) { result.insert (i, p1->column, p1->data); p1 = p1->pRight; } while (p2 != nullptr ) { result.insert (i, p2->column, p2->data); p2 = p2->pRight; } } return result; }
双向十字链表(舞蹈链): 带哨兵节点的双向循环十字链表,每个节点拥有四个指针域。在搜索问题中,所需存储的矩阵往往随着递归的加深会变得越来越稀疏,在这种情况下使用舞蹈链来存储矩阵,往往会取得比较好的效果。
字符串
串的定义: 串是由零个或多个字符顺序排列组成的有限序列,字符串 S S S
S = a 0 a 1 ⋯ a n − 1 S = a_0 a_1 \cdots a_{n - 1}
S = a 0 a 1 ⋯ a n − 1
S S S n n n
串是数据元素受限的线性表。
子串: 主串中任意个连续字符组成的序列。子串在主串中第一次出现时,其首字符序号称为该子串在主串中的位置。
字符串的基本操作:
串长统计;
串的定位;
串的复制;
串的插入;
串的删除;
串的拼接。
字符串的存储方式
串的顺序存储: 将一个串所包含的字符序列相继存入连续的字节。演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class SeqString {public : SeqString () = default ; SeqString (const char * p) { const char * q = p; while (*q != '\0' ) { ++length; ++q; } pData = new char [length + 1 ]; for (std::size_t i = 0 ; i < length; ++i) { pData[i] = p[i]; } pData[length] = '\0' ; } ~SeqString () { delete [] pData; } SeqString (const SeqString&); SeqString& operator =(const SeqString&); ... private : char * pData{ nullptr }; std::size_t length{ 0 }; };
串的链式存储:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 class LinkedString {public : struct Node { char data{ 0 }; Node* pNext{ nullptr }; }; LinkedString () : pHead (new Node) {} LinkedString (const char * p) : pHead (new Node) { const char * q = p; while (*q != '\0' ) { ++length; ++q; } auto pNode = pHead; pNode->data = p[0 ]; for (std::size_t i = 1 ; i < length; ++i) { auto pNew = new Node (); pNew->data = p[i]; pNode->pNext = pNew; pNode = pNew; } auto pNew = new Node (); pNew->data = '\0' ; pNode->pNext = pNew; } ~LinkedString () { Node* pNode = pHead; while (pNode != nullptr ) { auto pOrigin = pNode; pNode = pNode->pNext; delete pOrigin; } } LinkedString (const LinkedString&); LinkedString& operator =(const LinkedString&); bool insert (std::size_t pos, const LinkedString& str) ... private : Node* pHead; std::size_t length{ 0 }; };
链式存储字符串的插入操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 bool LinkedString::insert (std::size_t pos, const LinkedString& str) if (pos < 0 || pos > length) { std::cerr << "不合法的输入" << std::endl; return false ; } if (str.length <= 0 ) return true ; length += str.length; auto pSrc = new Node (); pSrc->data = str.pHead->data; auto pNode = str.pHead->pNext; auto pTail = pSrc; while (pNode->data != '\0' ) { pTail->pNext = new Node (); pTail = pTail->pNext; pTail->data = pNode->data; pNode = pNode->pNext; } if (pos == 0 ) { pTail->pNext = pHead; pHead = pSrc; return true ; } pNode = pHead; std::size_t count = 0 ; while (count < pos - 1 ) { pNode = pNode->pNext; ++count; } pTail->pNext = pNode->pNext; pNode->pNext = pSrc; return true ; }
模式匹配算法
给定两个字符串 S S S P P P S S S n n n P P P m m m m ≤ n m \leq n m ≤ n S S S P P P P P P S S S − 1 -1 − 1
朴素模式匹配算法: 是一种暴力算法,该匹配算法过程简单,但效率较低。该算法的演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 std::size_t stringMatching (const std::string& source, const std::string& pattern) { std::size_t i = 0 ; while (i <= source.length () - pattern.length ()) { std::size_t j = 0 ; while (source[i] == pattern[j]) { ++i; ++j; } if (j == pattern.length ()) { return i - pattern.length (); } i = i - j + 1 ; } return -1 ; }
该算法的基本运算为字符比较,最好时间复杂度为 m m m
m ⋅ ( n − m + 1 ) = O ( n ⋅ m ) m \cdot (n - m + 1) = O(n \cdot m)
m ⋅ ( n − m + 1 ) = O ( n ⋅ m )
设 P P P S S S q q q S S S
E ( m , n ) = ∑ i ∈ D m , n { P ( i ) ⋅ T ( i ) } = q n − m + 1 ( m + m + 1 2 + m + ⋯ + m + 1 2 ( n − m ) + m ) + ( 1 − q ) m + 1 2 ( n − m + 1 ) = q [ 1 4 ( m + 1 ) ( n − m ) − 1 2 ( m + 1 ) ( n − m + 1 ) + m ] + 1 2 ( n − m + 1 ) ( m + 1 ) = O ( n ⋅ m ) \begin{aligned}
E(m, n) &= \sum_{i \in D_{m, n}} \{ P(i) \cdot T(i) \}\\
&= \frac{q}{n - m + 1}\left( m + \frac{m + 1}{2} + m + \cdots + \frac{m + 1}{2}(n - m) + m \right)\\
&+ (1 - q)\frac{m + 1}{2}(n - m + 1)\\
&= q\left[ \frac{1}{4}(m + 1)(n - m) - \frac{1}{2}(m + 1)(n - m + 1) + m \right]\\
&+ \frac{1}{2}(n - m + 1)(m + 1)\\
&= O(n \cdot m)
\end{aligned} E ( m , n ) = i ∈ D m , n ∑ { P ( i ) ⋅ T ( i )} = n − m + 1 q ( m + 2 m + 1 + m + ⋯ + 2 m + 1 ( n − m ) + m ) + ( 1 − q ) 2 m + 1 ( n − m + 1 ) = q [ 4 1 ( m + 1 ) ( n − m ) − 2 1 ( m + 1 ) ( n − m + 1 ) + m ] + 2 1 ( n − m + 1 ) ( m + 1 ) = O ( n ⋅ m )
KMP 算法: 朴素模式匹配算法效率不高的主要原因是进行了重复的字符比较,在很多时候执行了没必要的指针回退。而为了避免这种情况,KMP 算法花费了额外的空间来记录一些信息,称作 next 数组 ,表示模式串匹配失败时,需要向后移动的距离。
例:模式串 abcabcacabca 的 next 数组如下:
序号j
1
2
3
4
5
6
7
8
9
10
11
12
模式串
a
b
c
a
b
c
a
c
a
b
c
a
next[j - 1]
0
1
1
1
2
3
4
5
1
2
3
4
该算法的演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 std::vector<std::size_t > getPatternNext (const std::string& pattern) { std::vector<std::size_t > next (pattern.length()) ; next[0 ] = 0 ; std::size_t i = 1 , j = 0 ; while (i < pattern.length ()) { if (j == 0 || pattern[i - 1 ] == pattern[j - 1 ]) { ++i; ++j; next[i - 1 ] = j; } else { j = next[j - 1 ]; } } return next; } std::size_t stringMatching (const std::string& source, const std::string& pattern) { auto next = getPatternNext (pattern); std::size_t i = 1 , j = 1 ; while (i <= source.length () && j <= pattern.length ()) { if (j == 0 || source[i - 1 ] == pattern[j - 1 ]) { ++i; ++j; } else { j = next[j - 1 ]; } } if (j > pattern.length ()) { return i - pattern.length () - 1 ; } return -1 ; }
计算 next 数组的时间复杂度为 O ( m ) O(m) O ( m ) O ( m + n ) O(m + n) O ( m + n )
next 数组的改进:在pattern[i - 1] == pattern[j - 1]成立时,继续对i、j自增后的pattern[i - 1]和pattern[j - 1]的值做判断。改进后的 next 数组可以避免更多不必要的匹配。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 std::vector<std::size_t > getPatternNextval (const std::string& pattern) { std::vector<std::size_t > next (pattern.length()) ; next[0 ] = 0 ; std::size_t i = 1 , j = 0 ; while (i < pattern.length ()) { if (j == 0 || pattern[i - 1 ] == pattern[j - 1 ]) { ++i; ++j; if (pattern[i - 1 ] != pattern[j - 1 ]) { next[i - 1 ] = j; } else { next[i - 1 ] = next[j - 1 ]; } } else { j = next[j - 1 ]; } } return next; }
树与二叉树
树结构在现实世界中大量存在,在计算机领域中也有着广泛的应用,例如:在程序编译中,用树来表示源程序的语法结构;在数据库系统中,用树来组织信息;在分析算法时,用树来描述其执行过程。
树的递归定义: 一棵树可以用节点的有限集合 T T T T T T T T T
唯一一个没有前驱的节点,称为该树的根(root) ;
其余节点被分成若干个互不相交的子集 T 1 , T 2 , ⋯ , T m ( m ≥ 0 ) T_1, T_2, \cdots, T_m\ (m \geq 0) T 1 , T 2 , ⋯ , T m ( m ≥ 0 ) 子树(subtree) 。
树的非递归定义: 树是包含 n ( n ≥ 0 ) n\ (n \geq 0) n ( n ≥ 0 )
存在一个唯一的节点 v 0 v_0 v 0
任何非根节点都有且仅有一个前驱节点,称为该节点的父节点;
任何节点都可能有多个 ( ≤ n − 1 ) (\leq n - 1) ( ≤ n − 1 ) 叶子节点(leaf node) ;
任一非根节点 v k v_k v k v 0 v_0 v 0 v 0 → v 1 → ⋯ → v k v_0 \to v_1 \to \cdots \to v_k v 0 → v 1 → ⋯ → v k v i v_i v i v i − 1 ( 1 ≤ i ≤ k ) v_{i - 1}\ (1 \leq i \leq k) v i − 1 ( 1 ≤ i ≤ k )
树中节点的各个子树从左到右有序的称为有序树 ,无序的则称为无序树 。
节点的层数:
根节点的层数为 0;
其余节点的层数为其父节点的层数加 1。
节点的深度: 根节点到该节点的路径所经过的边数,等价于该节点的祖先个数。一棵树的深度即为该树中所有节点的深度的最大值。
节点的高度: 该节点到叶子节点的最长路径所经过的边数,叶子节点的高度为 0。一棵树的高度即为其根节点的高度,同时也是树中节点的最大层数。
树的基本操作:
创建树;
遍历树;
判断树是否为空;
获取树的根节点;
获取节点的父节点;
获取节点的子节点;
获取节点的兄弟节点;
求树的深度。
二叉树
二叉树的特征:
二叉树每个节点最多有 2 个子节点;
二叉树的子树有左右之分;
二叉树是有有序树;
树和二叉树是两种不同的数据结构,不能认为二叉树是树的特例。
性质 1: 二叉树中层数为 i i i 2 i ( i ≥ 0 ) 2^i\ (i \geq 0) 2 i ( i ≥ 0 )
性质 2: 高度为 k k k k + 1 ( k ≥ 1 ) k + 1\ (k \geq 1) k + 1 ( k ≥ 1 ) 2 k + 1 − 1 ( k ≥ 0 ) 2^{k + 1} - 1\ (k \geq 0) 2 k + 1 − 1 ( k ≥ 0 ) k k k k − 1 ( k ≥ 1 ) k - 1\ (k \geq 1) k − 1 ( k ≥ 1 )
性质 3: 设 T T T n n n n 0 n_0 n 0 n 2 n_2 n 2 n 0 = n 2 + 1 n_0 = n_2 + 1 n 0 = n 2 + 1
证明:设度为 1 的节点个数为 n 1 n_1 n 1 n n n e e e
n = n 0 + n 1 + n 2 n = n_0 + n_1 + n_2
n = n 0 + n 1 + n 2
根据子节点和父节点的连接,可以写出
e = n − 1 e = n - 1
e = n − 1
根据所有发出分支的节点,可以写出
e = 2 n 2 + n 1 e = 2n_2 +n_1
e = 2 n 2 + n 1
因此,有
2 n 2 + n 1 = n 0 + n 1 + n 2 − 1 n 2 = n 0 − 1 n 0 = n 2 + 1 \begin{aligned}
2n_2 + n_1 &= n_0 + n_1 + n_2 -1\\
n_2 &= n_0 - 1\\
n_0 &= n_2 + 1
\end{aligned} 2 n 2 + n 1 n 2 n 0 = n 0 + n 1 + n 2 − 1 = n 0 − 1 = n 2 + 1
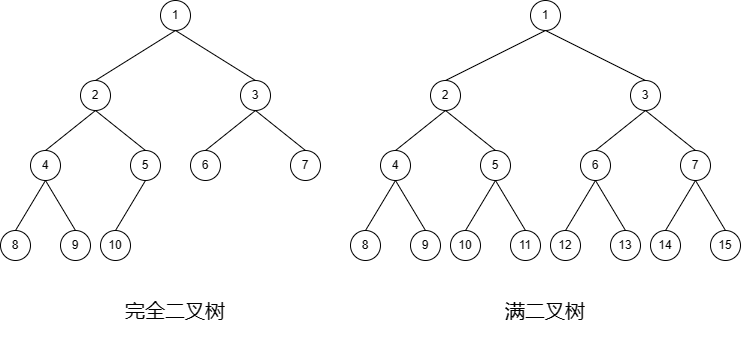
满二叉树: 高度为 k ( k ≥ 0 ) k\ (k \geq 0) k ( k ≥ 0 ) 2 k + 1 − 1 2^{k + 1} - 1 2 k + 1 − 1
满二叉树的特点是:
叶子节点都在第 k k k
每个分支节点都有两个子节点;
叶子节点的个数等于非叶子节点的个数加 1。
完全二叉树: 高度为 k k k k k k k k k
若将一棵具有 n n n i ( 1 ≤ n ≤ n ) i\ (1 \leq n \leq n) i ( 1 ≤ n ≤ n )
若 i ≠ 1 i \neq 1 i = 1 i i i ⌊ i 2 ⌋ \left\lfloor \dfrac{i}{2} \right\rfloor ⌊ 2 i ⌋
若 2 i ≤ n 2i \leq n 2 i ≤ n i i i 2 i 2i 2 i
若 2 i + 1 ≤ n 2i + 1 \leq n 2 i + 1 ≤ n i i i 2 i + 1 2i + 1 2 i + 1
定理: 具有 n n n ⌊ log 2 n ⌋ \left\lfloor \log_2 n \right\rfloor ⌊ log 2 n ⌋
证明:设二叉树的高度为 k k k k − 1 k - 1 k − 1 k k k
2 k − 1 < n ≤ 2 k + 1 − 1 2^k - 1 < n \leq 2^{k + 1} - 1
2 k − 1 < n ≤ 2 k + 1 − 1
从而有 2 k ≤ n < 2 k + 1 2^k \leq n < 2^{k + 1} 2 k ≤ n < 2 k + 1
k ≤ log 2 n < k + 1 k \leq \log_2 n < k + 1
k ≤ log 2 n < k + 1
因为 k k k k = ⌊ log 2 n ⌋ k = \left\lfloor \log_2 n \right\rfloor k = ⌊ log 2 n ⌋
二叉树的存储方式
二叉树的顺序存储: 将二叉树的所有节点按层次顺序存放在一块连续的存储空间内,同时要反映除二叉树中节点间的逻辑关系。
对于含 n n n A[n]进行存储,其中A[0]存储二叉树的根节点,A[i - 1]存储二叉树中编号为 i i i A[i - 1]的左子节点(如果存在)存放在A[2i - 1]处,而A[i - 1]的右子节点(如果存在)存放在A[2i]处。
但将这种存储方式应用到非完全二叉树时,会遇到很多问题,例如编号无法一一对应,此时若使用虚节点将非完全二叉树转化为完全二叉树,又会增加用于存储虚节点的空间。
二叉树的链接存储: 二叉树的所有节点被随机存放在内存中,节点之间的关系用指针表示。
二叉链表表示法(无父节点指针):
1 2 3 4 5 6 template <typename T>struct BinaryTreeNode { T data; BinaryTreeNode* pLeft{ nullptr }; BinaryTreeNode* pRight{ nullptr }; };
三叉链表表示法(有父节点指针):
1 2 3 4 5 6 7 template <typename T>struct BinaryTreeNode { T data; BinaryTreeNode* pParent{ nullptr }; BinaryTreeNode* pLeft{ nullptr }; BinaryTreeNode* pRight{ nullptr }; };
二叉树的遍历
若按子树递归遍历二叉树,则有三种遍历的顺序:
遍历顺序
前序(preorder)
中序(inorder)
后序(postorder)
步骤一
访问根节点
遍历左子树
遍历左子树
步骤二
遍历左子树
访问根节点
遍历右子树
步骤三
遍历右子树
遍历右子树
访问根节点
三种遍历所生成的序列的叶子节点间的相对次序是相同的,叶子节点都是按照从左到右的次序排列,区别仅在于非叶子节点间的次序以及非叶子节点和叶子节点间的次序。
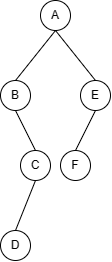
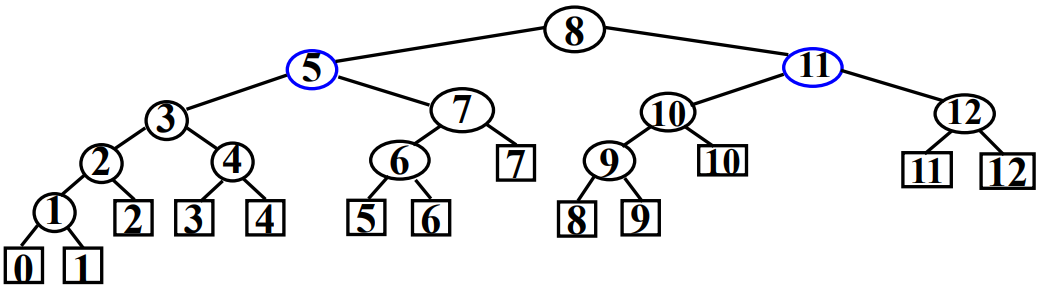
例:写出该树的遍历序列。
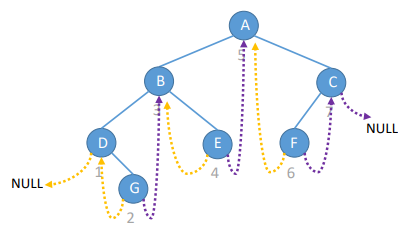
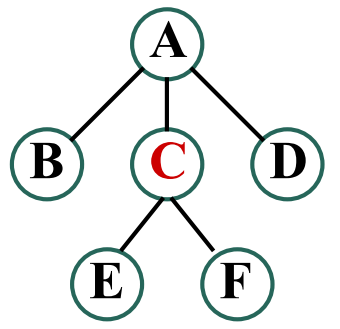
前序遍历序列:A B C D E F
通过前序遍历序列和中序遍历序列,或中序遍历序列和后序遍历序列都可以唯一确定一棵二叉树,但通过前序遍历序列和后序遍历序列却不可以,因为无法确定根节点的左子树与右子树的边界。
二叉树的模板类定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 template <typename T>struct BinaryTreeNode { T data; BinaryTreeNode* pLeft{ nullptr }; BinaryTreeNode* pRight{ nullptr }; }; template <typename T>class BinaryTree {public : BinaryTree () = default ; BinaryTree (BinaryTreeNode<T>* pRoot) : pRoot (pRoot) {} ~BinaryTree (); BinaryTree (const BinaryTree&); BinaryTree& operator =(const BinaryTree&); BinaryTreeNode<T>* root () { return pRoot; } const BinaryTreeNode<T>* root () const return pRoot; } void traversal () const traversal (pRoot); } ... private : void traversal (BinaryTreeNode<T>* pNode) const BinaryTreeNode<T>* pRoot{ nullptr }; };
前序遍历的递归算法:
1 2 3 4 5 6 7 8 9 10 11 template <typename T>void BinaryTree<T>::traversal (BinaryTreeNode<T>* pNode) const { if (pNode == nullptr ) { return ; } std::cout << pNode->data << std::endl; traversal (pNode->pLeft); traversal (pNode->pRight); }
中序遍历的递归算法:
1 2 3 4 5 6 7 8 9 10 11 12 template <typename T>void BinaryTree<T>::traversal (BinaryTreeNode<T>* pNode) const { if (pNode == nullptr ) { return ; } traversal (pNode->pLeft); std::cout << pNode->data << std::endl; traversal (pNode->pRight); }
后序遍历的递归算法:
1 2 3 4 5 6 7 8 9 10 11 template <typename T>void BinaryTree<T>::traversal (BinaryTreeNode<T>* pNode) const { if (pNode == nullptr ) { return ; } traversal (pNode->pLeft); traversal (pNode->pRight); std::cout << pNode->data << std::endl; }
前序遍历的非递归算法: 用栈保存待处理的子任务,先访问节点数据并入栈,然后处理左子树,最后将节点出栈并处理右子树。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 template <typename T>void BinaryTree<T>::traversal () const { std::stack<BinaryTreeNode<T>*> nodeStack; auto pNode = pRoot; while (pNode != nullptr || !nodeStack.empty ()) { while (pNode != nullptr ) { std::cout << pNode->data << std::endl; nodeStack.push (pNode); pNode = pNode->pLeft; } pNode = nodeStack.top (); nodeStack.pop (); pNode = pNode->pRight; } }
中序遍历的非递归算法: 先将节点入栈并处理左子树,然后访问节点数据并出栈,最后处理右子树。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 template <typename T>void BinaryTree<T>::traversal () const { std::stack<BinaryTreeNode<T>*> nodeStack; auto pNode = pRoot; while (pNode != nullptr || !nodeStack.empty ()) { while (pNode != nullptr ) { nodeStack.push (pNode); pNode = pNode->pLeft; } pNode = nodeStack.top (); nodeStack.pop (); std::cout << pNode->data << std::endl; pNode = pNode->pRight; } }
后序遍历的非递归算法: 前 / 中序遍历的非递归算法,一个节点只需进出栈一次,可以判断访问根节点的位置就在进 / 出栈时;而后序遍历需要在处理完右子树后再访问根节点,需要节点进出栈多次,并对所处状态进行标记。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 template <typename T>void BinaryTree<T>::traversal () const { using StackNode = std::pair<BinaryTreeNode<T>*, uint8_t >; std::stack<StackNode> nodeStack; nodeStack.push (StackNode (pRoot, 0 )); while (!nodeStack.empty ()) { StackNode node = nodeStack.top (); nodeStack.pop (); if (node.second == 0 ) { nodeStack.push (StackNode (node.first, 1 )); if (node.first->pLeft != nullptr ) { nodeStack.push (StackNode (node.first->pLeft, 0 )); } } else if (node.second == 1 ) { nodeStack.push (StackNode (node.first, 2 )); if (node.first->pRight != nullptr ) { nodeStack.push (StackNode (node.first->pRight, 0 )); } } else if (node.second == 2 ) { std::cout << node.first->data << std::endl; } } }
二叉树的层次遍历: 按层数从小到大,同层从左到右的顺序访问节点,需要一个队列来辅助实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 template <typename T>void BinaryTree<T>::traversal () const { std::queue<BinaryTreeNode<T>*> nodeQueue; BinaryTreeNode<T>* pNode = pRoot; if (pNode != nullptr ) { nodeQueue.push (pNode); } while (!nodeQueue.empty ()) { pNode = nodeQueue.front (); nodeQueue.pop (); std::cout << pNode->data << std::endl; if (pNode->pLeft != nullptr ) nodeQueue.push (pNode->pLeft); if (pNode->pRight != nullptr ) nodeQueue.push (pNode->pRight); } }
二叉树的其它操作
创建二叉树: 以包含空指针信息的前序遍历序列为输入,当读入stop所指数据时,将其初始化为一个空指针;否则生成一个新节点并对其父节点的子节点指针进行初始化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 template <typename T>BinaryTreeNode<T>* createBinaryTreeNode (std::vector<T>& data, const T& stop) { if (data.empty ()) return nullptr ; auto value = data.front (); data.erase (data.begin ()); BinaryTreeNode<T>* pNode = nullptr ; if (value != stop) { pNode = new BinaryTreeNode <T>(); pNode->data = value; pNode->pLeft = createBinaryTreeNode (data, stop); pNode->pRight = createBinaryTreeNode (data, stop); } return pNode; } template <typename T>BinaryTree<T> createBinaryTree (std::vector<T> data, const T& stop) { return BinaryTree <T>(createBinaryTreeNode (data, stop)); }
创建二叉树的非递归算法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 template <typename T>BinaryTreeNode<T>* createBinaryTree (const std::vector<T>& data, const T& stop) { if (data.empty ()) return nullptr ; std::stack<BinaryTreeNode<T>*> nodeStack; std::stack<int > stateStack; BinaryTreeNode<T>* pRoot = nullptr ; if (data[0 ] != stop) { pRoot = new BinaryTreeNode <T>(); pRoot->data = data[0 ]; nodeStack.push (pRoot); stateStack.push (0 ); } for (std::size_t i = 1 ; i < data.size (); ++i) { auto pNode = nodeStack.top (); auto state = stateStack.top (); stateStack.pop (); if (pNode == nullptr ) return nullptr ; if (state == 0 ) { stateStack.push (1 ); if (data[i] == 0 ) pNode->pLeft = nullptr ; else { pNode->pLeft = new BinaryTreeNode <T>(); pNode->pLeft->data = data[i]; nodeStack.push (pNode->pLeft); stateStack.push (0 ); } } else if (state == 1 ) { nodeStack.pop (); if (data[i] == 0 ) pNode->pRight = nullptr ; else { pNode->pRight = new BinaryTreeNode <T>(); pNode->pRight->data = data[i]; nodeStack.push (pNode->pRight); stateStack.push (0 ); } } } return pRoot; }
利用中序序列和后序序列重建二叉树:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 template <typename T>BinaryTreeNode<T>* buildBinaryTreeNode (const std::vector<T>& inorder, std::size_t inorderBegin, std::size_t inorderEnd, const std::vector<T>& postorder, std::size_t postorderBegin, std::size_t postorderEnd) if (inorderEnd <= inorderBegin || postorderEnd <= postorderBegin) return nullptr ; auto rootValue = postorder[postorderEnd - 1 ]; auto pRoot = new BinaryTreeNode <T>(); pRoot->data = rootValue; if (postorderEnd - postorderBegin == 1 ) { if (inorder[inorderBegin] != postorder[postorderBegin]) throw std::runtime_error ("Invalid input" ); else return pRoot; } std::size_t mid = inorderBegin; while (mid < inorderEnd && inorder[mid] != rootValue) { ++mid; } if (mid == inorderEnd) throw std::runtime_error ("Invalid input" ); pRoot->pLeft = buildBinaryTreeNode (inorder, inorderBegin, mid, postorder, postorderBegin, postorderBegin + mid - inorderBegin); pRoot->pRight = buildBinaryTreeNode (inorder, mid + 1 , inorderEnd, postorder, postorderBegin + mid - inorderBegin, postorderEnd - 1 ); return pRoot; } template <typename T>BinaryTreeNode<T>* buildBinaryTree (const std::vector<T>& inorder, const std::vector<T>& postorder) { return buildBinaryTreeNode (inorder, 0 , inorder.size (), postorder, 0 , postorder.size ()); }
释放二叉树: 定义二叉树模板类中的析构函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 template <typename T>void releaseBinaryTreeNode (BinaryTreeNode<T>* pNode) if (pNode == nullptr ) return ; releaseBinaryTreeNode (pNode->pLeft); releaseBinaryTreeNode (pNode->pRight); delete pNode; } template <typename T>BinaryTree<T>::~BinaryTree () { releaseBinaryTreeNode (pRoot); }
拷贝二叉树: 定义二叉树模板类中的拷贝构造函数和拷贝赋值运算符。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 template <typename T>BinaryTreeNode<T>* copyBinaryTreeNode (BinaryTreeNode<T>* pNode) { if (pNode == nullptr ) return nullptr ; BinaryTreeNode<T>* pNew = new BinaryTreeNode <T>(); pNew->data = pNode->data; pNew->pLeft = copyBinaryTreeNode (pNode->pLeft); pNew->pRight = copyBinaryTreeNode (pNode->pRight); return pNew; } template <typename T>BinaryTree<T>::BinaryTree (const BinaryTree& rhs) { pRoot = copyBinaryTreeNode (rhs.pRoot); } template <typename T>BinaryTree<T>& BinaryTree<T>::operator =(const BinaryTree& rhs) { pRoot = copyBinaryTreeNode (rhs.pRoot); return *this ; }
搜索拥有指定数据的节点:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 template <typename T>BinaryTreeNode<T>* searchBinaryTreeNode (BinaryTreeNode<T>* pNode, const T& value) { if (pNode == nullptr ) return nullptr ; if (pNode->data == value) return pNode; BinaryTreeNode<T>* pResult = searchBinaryTreeNode (pNode->pLeft, value); if (pResult != nullptr ) return pResult; return searchBinaryTreeNode (pNode->pRight, value); } template <typename T>BinaryTreeNode<T>* BinaryTree<T>::search (const T& value) { return searchBinaryTreeNode (pRoot, value); }
查找给定节点的父节点:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 template <typename T>BinaryTreeNode<T>* findBinaryTreeNodeParent (BinaryTreeNode<T>* pRoot, BinaryTreeNode<T>* pNode) { if (pNode == nullptr || pRoot == nullptr || pNode == pRoot) return nullptr ; if (pRoot->pLeft == pNode || pRoot->pRight == pNode) return pRoot; BinaryTreeNode<T>* pParent = findBinaryTreeNodeParent (pRoot->pLeft, pNode); if (pParent != nullptr ) return pParent; return findBinaryTreeNodeParent (pRoot->pRight, pNode); } template <typename T>BinaryTreeNode<T>* BinaryTree<T>::parent (BinaryTreeNode<T>* pNode) { return findBinaryTreeNodeParent (pRoot, pNode); }
插入节点: 插入新的节点并使其成为给定节点的左子节点。
1 2 3 4 5 6 7 8 9 template <typename T>void BinaryTree<T>::insert (BinaryTreeNode<T>* pNode, const T& value) { if (pNode == nullptr ) return ; BinaryTreeNode<T>* pNew = new BinaryTreeNode <T>(); pNew->data = value; pNew->pLeft = pNode->pLeft; pNode->pLeft = pNew; }
删除节点及其子树:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 template <typename T>void BinaryTree<T>::remove (BinaryTreeNode<T>* pNode) { if (pNode == nullptr ) return ; if (pNode == pRoot) { releaseBinaryTreeNode (pRoot); pRoot = nullptr ; return ; } BinaryTreeNode<T>* pParent = parent (pNode); if (pParent->pLeft == pNode) pParent->pLeft = nullptr ; if (pParent->pRight == pNode) pParent->pRight = nullptr ; releaseBinaryTreeNode (pNode); }
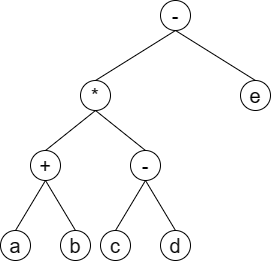
表达式二叉树
表达式中存在一个内在的二叉树结构,二叉树中叶子节点可以代表表达式中的变量或常数,非叶子节点可以代表操作符。如果不考虑一元操作符符号,则可以用后缀表达式构造表达式对应的二叉树。
上图对应的后缀表达式为:ab+cd-*e-
可以通过从左向右扫描后缀表达式中的符号,来建立二叉树:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 BinaryTree<char > createExpressionTree (const std::string& expr) { std::stack<BinaryTreeNode<char >*> nodeStack; for (const auto op : expr) { if (op == '+' || op == '-' || op == '*' || op == '/' ) { auto pNode = new BinaryTreeNode <char >(); pNode->data = op; pNode->pRight = nodeStack.top (); nodeStack.pop (); pNode->pLeft = nodeStack.top (); nodeStack.pop (); nodeStack.push (pNode); } else { auto pNode = new BinaryTreeNode <char >(); pNode->data = op; nodeStack.push (pNode); } } return BinaryTree <char >(nodeStack.top ()); }
通过后序遍历一个表达式对应的二叉树,可以计算出表达式的值:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 double calculateExpression (const BinaryTree<char >& tree) using TraversalData = std::pair<const BinaryTreeNode<char >*, uint8_t >; std::stack<TraversalData> travStack; travStack.push (TraversalData (tree.root (), 0 )); std::stack<double > calcStack; while (!travStack.empty ()) { TraversalData travData = travStack.top (); travStack.pop (); if (travData.second == 0 ) { travStack.push (TraversalData (travData.first, 1 )); if (travData.first->pLeft != nullptr ) { travStack.push (TraversalData (travData.first->pLeft, 0 )); } } if (travData.second == 1 ) { travStack.push (TraversalData (travData.first, 2 )); if (travData.first->pRight != nullptr ) { travStack.push (TraversalData (travData.first->pRight, 0 )); } } if (travData.second == 2 ) { auto pNode = travData.first; if (pNode->pLeft == nullptr && pNode->pRight == nullptr ) { calcStack.push (static_cast <double >(pNode->data - '0' )); } else { auto num2 = calcStack.top (); calcStack.pop (); auto num1 = calcStack.top (); calcStack.pop (); auto op = pNode->data; if (op == '+' ) calcStack.push (num1 + num2); else if (op == '-' ) calcStack.push (num1 - num2); else if (op == '*' ) calcStack.push (num1 * num2); else if (op == '/' ) calcStack.push (num1 / num2); } } } return calcStack.top (); }
线索二叉树
在之前提到过,遍历二叉树时我们会得到一个线性序列(前序序列、中序序列、后序序列),这些序列除了头尾节点之外,都有且仅有一个前驱和一个后继。而对于普通的二叉树,想要直接得到序列中节点的前驱和后继比较困难,必须要经过一次遍历,为了解决这一问题,我们需要引入线索二叉树(threaded binary tree) 。
我们利用原本二叉树节点中的空指针来存储线索(即指向前驱和后继的指针),为了区分节点存储的是线索还是指向子节点的指针,我们需要向节点中引入额外的两个标记ltag和rtag:
1 2 3 4 5 6 7 8 template <typename T>struct ThreadedBinaryTreeNode { T data; ThreadedBinaryTreeNode* pLeft{ nullptr }; ThreadedBinaryTreeNode* pRight{ nullptr }; bool ltag{ false }; bool rtag{ false }; };
若ltag为假,则pLeft指向其左子节点;若ltag为真,则pLeft指向其在序列中的前驱节点。
若rtag为假,则pRight指向其右子节点;若rtag为真,则pRight指向其在序列中的后继节点。
线索二叉树中一个节点为叶子节点的充要条件是ltag和rtag均为真。
压缩与哈夫曼树
文件编码与最优二叉树
在实际应用的一些大文件中,字符被使用的比例是非平均的,有些字符出现的次数较多,有些则非常少,如果所有的字符都用等长的二进制码表示,则将会造成空间的浪费。文件压缩的通常策略即是:采用不等长的二进制码。令文件中出现频率高的字符的编码尽可能短。
采用不等长编码有可能会产生多义性,为避免出现多义性,必须要求字符集中任何字符的编码都不是其它字符的编码的前缀,满足这个条件的编码被称为前缀码 ,显然等长编码就是一种前缀码。
设组成文件的字符集为 A = { a 1 , a 2 , ⋯ , a n } A = \{ a_1, a_2, \cdots, a_n \} A = { a 1 , a 2 , ⋯ , a n } a i a_i a i l i l_i l i c i c_i c i l i l_i l i ∑ i = 1 n c i l i \sum\limits_{i = 1}^n c_i l_i i = 1 ∑ n c i l i
扩充二叉树: 为了使处理问题更加方便,每当二叉树中出现空子树时,就在空子树的位置增加特殊的空叶子节点,由此生成的二叉树称为扩充二叉树。二叉树中原来的节点称为内节点 ,扩充出的节点称为外节点 。
从根节点到每个内节点的路径长度之和称为扩充二叉树的内部路径长度 ;从根节点到每个外节点的路径长度之和称为扩充二叉树的外部路径长度 。
给扩充二叉树的所有外节点附加一个实数权值,则扩充二叉树的加权路径长度(weighted path length,简称 WPL) 为:
W P L = ∑ i = 1 w i ⋅ l i WPL = \sum_{i = 1} w_i \cdot l_i
W P L = i = 1 ∑ w i ⋅ l i
其中 n n n w i w_i w i l i l_i l i k i k_i k i k i k_i k i 最优二叉树 。
文件编码问题可以转化为构造最优二叉树问题,每个外节点代表一个字符,其权值代表该字符的频率,从根到外节点的路径长度就是该字符的编码长度。
构建哈夫曼树
根据给定的 n n n w 1 , w 2 , ⋯ , w n w_1, w_2, \cdots, w_n w 1 , w 2 , ⋯ , w n n n n F = { T 1 , T 2 , ⋯ , T n } F = \{ T_1, T_2, \cdots, T_n \} F = { T 1 , T 2 , ⋯ , T n } T i T_i T i w 1 w_1 w 1
在 F F F F F F
重复步骤 2,直到 F F F 哈夫曼树(Huffman tree) 。
给哈夫曼树每个分支节点的左分支标上 0,右分支标上 1,把从根节点搭配每个叶子节点的路径上的标号连接起来,作为该叶子节点所代表的字符的编码,称为哈夫曼编码 。
定理 1: 在外节点权值分别为 w 1 , w 2 , ⋯ , w n w_1, w_2, \cdots, w_n w 1 , w 2 , ⋯ , w n
定理 2: 在构建哈夫曼树的过程中,不存在叶子节点是其它叶子节点的祖先,因此每个叶子节点对应的编码不可能是其它叶子节点对应的编码的前缀,所以哈夫曼编码为二进制前缀码。
哈夫曼树中不存在度为 1 的节点。
哈夫曼树节点的数据结构为:
1 2 3 4 5 6 7 template <typename T>struct HuffmanTreeNode { T data; int weight{ 0 }; int left{ 0 }; int right{ 0 }; };
静态哈夫曼编码: 需要通过两遍扫描来构建哈夫曼树,延迟比较大。动态哈夫曼编码: 通过前 t t t t + 1 t + 1 t + 1
树的存储与操作
树与二叉树的转化
将树转化为二叉树:
在相邻的兄弟节点之间增加连线;
对树中每个节点,删去它与除了第一个子节点外的所有子节点之间的连线;
调整连线使其形状符合二叉树的规范。
将森林转化为二叉树:
方法一:
引入一个虚拟总根,将其看作森林中所有树的根节点的父节点,这样森林就可以转化为一棵树;
将形成的新树转化为二叉树;
在转化为二叉树的过程中,虚拟总根不会起任何作用,转化完成后删去即可。
方法二:
先将森林中每一棵树都转化为二叉树,在转化完成后,新的二叉树根节点的右子树都是空树;
将第一棵二叉树的根节点视为总根,将其余二叉树的根节点彼此视为兄弟节点,依次从左到右连接在一起。
将二叉树转化为树: 若二叉树根节点的右子树为空,则可以将其自然地转化为树:
若某节点是其父节点的左子节点,则将其右子节点,右子节点的右子节点等都与其父节点之间增加连线;
删去所有父子节点与其右子节点之间的连线;
调整连线使其形状符合树的规范。
将二叉树转化为森林: 若二叉树根节点的右子树非空,则可以将其自然地转化为森林:
从根节点出发,递归地删去其与右子节点间的连线,形成多个二叉树;
将每个二叉树都转化为树的形状。
树的存储结构
树形结构是非线性结构,最自然地表示树形结构的方式就是链接结构,主要有以下几种:
父亲表示法;
孩子表示法;
父亲-孩子表示法;
孩子-兄弟表示法。
父亲表示法: 为各节点附加一个记录其父节点的数据成员:
1 2 3 4 5 template <typename T>struct TreeNode { T data; TreeNode* pParent{ nullptr }; };
缺点:不易实现遍历。
孩子表示法: 采用 “顺序表 + 链表” 的组合结构,在顺序表中依次存储树的各个节点,在链表中存储各节点的子节点位于顺序表中的位置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 struct TreeChildNode { std::size_t child{ -1 }; TreeChildNode* pNext{ nullptr }; }; template <typename T>struct TreeNode { T data; TreeChildNode* pFirstChild{ nullptr }; }; template <typename T>class Tree {public : ... private : std::vector<TreeNode> nodes; };
优点:便于涉及子节点的操作。
父亲-孩子表示法: 采用父节点数组与子节点链表组合在一起的存储结构:
1 2 3 4 5 6 template <typename T>struct TreeNode { T data; std::size_t parent{ -1 }; TreeChildNode* pFirstChild{ nullptr }; };
孩子-兄弟表示法: 存储各节点的第一个子节点和下一个兄弟节点:
1 2 3 4 5 6 template <typename T>struct TreeNode { T data; TreeNode* pFirstChild{ nullptr }; TreeNode* pNextSibling{ nullptr }; };
优点:与对应二叉树的链接表示法完全相同,可以用二叉树的算法来实现对树的操作。
树与森林的遍历
树的遍历:
前序遍历:先访问树的根节点,再依次前序遍历每棵子树。
后序遍历:先依次后序遍历每棵子树,再访问树的根节点。
例:写出该树的遍历序列。
前序遍历序列:A B C E F D
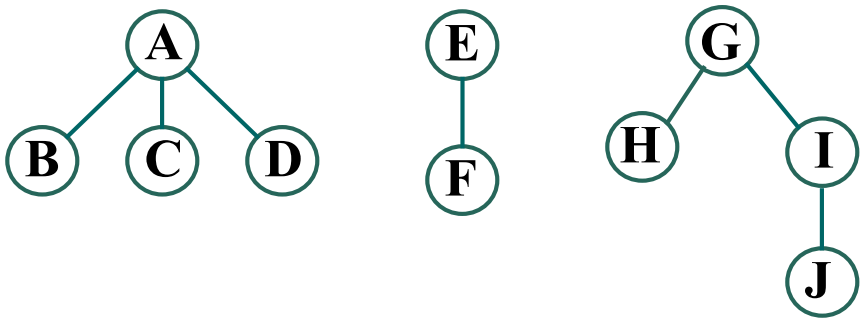
森林的遍历:
前序遍历:先访问森林中第一棵树的根节点,再前序遍历第一棵树中的各子树,之后再前序遍历其余各树。
后序遍历:先后序遍历森林中第一棵树的各子树,再访问第一棵树的根节点,之后再后序遍历其余各树。
森林的后序遍历序列 与其对应二叉树的中序遍历序列 一致。
例:写出该森林的遍历序列。
前序遍历序列:A B C D E F G H I J
定理 1: 如果已知一棵树的前序序列(或后序序列)和每个节点相应的次数,则能唯一确定该树的结构。
定理 2: 如果已知一个树的层次序列和每个节点相应的次数,则能唯一确定该树的结构。
并查集
并查集(disjoint set union,简称 DSU) 是一种用于处理不相交集(disjoint sets) 的合并及查询问题的数据结构,它的基本思想是维护一个不相交集的集合,为标识其中的每个集合,选择集合中的某个元素代表整个集合,该元素称为集合的代表元(representative element) ,并确保同一集合的两个元素拥有相同的代表元。
并查集的一种高效实现方式是用树表示集合,每棵树代表一个不相交集,由树组成的森林就代表一个并查集。树的每个节点对应集合中的一个元素,根节点对应集合的代表元。
并查集类的定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class DSUTree {public : DSUTree (std::size_t size) : parents (size) { for (std::size_t i = 0 ; i < parents.size (); ++i) { parents[i] = i; } } void merge (std::size_t lhs, std::size_t rhs) std::size_t find (std::size_t elem) const ; bool isSame (std::size_t lhs, std::size_t rhs) const ... private : std::vector<std::size_t > parents; };
并查集的查询:
1 2 3 4 5 std::size_t DSUTree::find (std::size_t elem) const { return parents[elem] == elem ? elem : find (parents[elem]); }
并查集的合并:
1 2 3 void DSUTree::merge (std::size_t lhs, std::size_t rhs) parents[find (lhs)] = find (rhs); }
判断两个元素是否属于同一集合:
1 2 3 bool DSUTree::isSame (std::size_t lhs, std::size_t rhs) const return find (lhs) == find (rhs); }
并查集的优化:
方法一(路径压缩):在查询的过程中,将沿途的每个节点的父节点都设为根节点,这样在下次查询时,就可以减少递归的次数(此时find和isSame不再是 const 成员函数):
1 2 3 4 5 std::size_t DSUTree::find (std::size_t elem) { return parents[elem] == elem ? elem : (parents[elem] = find (parents[elem])); }
方法二(按秩合并):此处的秩表示子树高的上界 ,通常我们令只有一个节点的树的秩为 0。在合并两棵树时,如果秩不相等,就将秩小的树合并到秩大的树上,这样就能保证新树的秩不大于原来任何一棵树;如果秩相等,就将两棵树任意合并,并将新树的秩设为原来的秩加 1。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class DSUTree {public : DSUTree (std::size_t size) : parents (size), ranks (size, 0 ) { for (std::size_t i = 0 ; i < parents.size (); ++i) { parents[i] = i; } } ... private : std::vector<std::size_t > parents; std::vector<std::size_t > ranks; }; void DSUTree::merge (std::size_t lhs, std::size_t rhs) auto x = find (lhs), y = find (rhs); if (ranks[x] > ranks[y]) { parents[y] = x; } else { parents[x] = y; if (ranks[x] == ranks[y]) ++ranks[y]; } }
前缀树
前缀树(字典树) 是一种专门用于处理字符串匹配的数据结构。通常来说,前缀树的每一个节点代表一个字符(前缀),每一个节点会有多个子节点,通往不同子节点的路径上有着不同的字符。子节点代表的字符串是由节点本身的原始字符串,以及通往该子节点路径上所有的字符组成的。
前缀树的数据结构为:
1 2 3 4 struct TrieNode { std::map<char , TrieNode*> children; bool end{ false }; };
前缀树的插入操作如下所示:
1 2 3 4 5 6 7 8 9 10 void insertTrieNode (TrieNode* pRoot, const string& word) auto p = pRoot; for (auto ch : word) { if (!p->child.count (ch)) { p->children[ch] = new Node (); } p = p->children[ch]; } p->end = true ; }
前缀树的查找操作如下所示:
1 2 3 4 5 6 7 8 9 10 TrieNode* searchTrieNode (TrieNode* pRoot, const string& prefix) { auto p = pRoot; for (char ch : prefix) { if (!p->children.count (ch)) { return nullptr ; } p = p->children[ch]; } return p; }
图
图的基本概念我已经在 离散数学(二):图与网络 中详细写过,此处不再赘述。
图的存储结构
邻接矩阵: 用顺序或链接方式存储图的顶点列表 v 1 , v 2 , ⋯ , v n v_1, v_2, \cdots, v_n v 1 , v 2 , ⋯ , v n n × n n \times n n × n A = ( a i j ) A = (a_{ij}) A = ( a ij )
(a)若图为权图,则 a i j a_{ij} a ij ⟨ v i , y j ⟩ \langle v_i, y_j \rangle ⟨ v i , y j ⟩
(b)若图为非权图,则
a i i = 0 a_{ii} = 0 a ii = 0 当 i ≠ j i \neq j i = j ⟨ v i , y j ⟩ \langle v_i, y_j \rangle ⟨ v i , y j ⟩ a i j = 1 a_{ij} = 1 a ij = 1
当 i ≠ j i \neq j i = j ⟨ v i , y j ⟩ \langle v_i, y_j \rangle ⟨ v i , y j ⟩ a i j = 0 a_{ij} = 0 a ij = 0
无向图的邻接矩阵对称,可压缩存储,有 n n n n ( n + 1 ) 2 \dfrac{n(n + 1)}{2} 2 n ( n + 1 ) n n n n 2 n^2 n 2
稠密图 适合用邻接矩阵存储。
借助邻接矩阵,可以很容易地求出图中顶点的度 :
无向图:邻接矩阵的第 i i i i i i v i v_i v i
有向图:邻接矩阵第 i i i v i v_i v i i i i v i v_i v i
顶点只用于存储数据:
1 2 3 4 template <typename T>struct Vertex { T data; };
边的结构为:
1 2 3 4 5 struct Edge { std::size_t start{ 0 }; std::size_t end{ 0 }; int weight{ 0 }; };
图的模板类定义如下:
1 2 3 4 5 6 7 8 9 10 11 template <typename T>class Graph {public : const std::vector<Vertex<T>>& getVertices () const { return vertices; } const std::vector<std::vector<Edge>>& getEdges () const { return edges; } ... private : std::vector<Vertex<T>> vertices; std::vector<std::vector<Edge>> edges; };
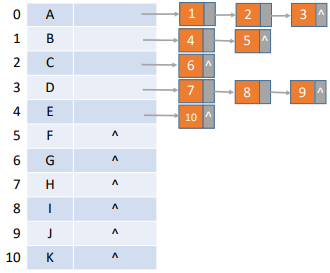
邻接表: 邻接表是图的一种链接存储结构。对图的每个顶点建立一个单链表,第 i i i v i v_i v i
稀疏图 适合用邻接表存储。
顶点的结构为:
1 2 3 4 5 template <typename T>struct Vertex { T data; Edge* pAdjEdge{ nullptr }; };
边节点的结构为:
1 2 3 4 5 struct Edge { std::size_t adjVertex{ 0 }; Edge* pLink{ nullptr }; int weight{ 0 }; };
图的模板类定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 template <typename T>class Graph {public : Graph (std::size_t vertexCount, std::size_t edgeCount) : vertices (vertexCount), edgeCount (edgeCount) {} const std::vector<Vertex<T>>& getVertices () const { return vertices; } std::size_t getEdgeCount () const { return edgeCount; } ... private : std::vector<Vertex<T>> vertices; std::size_t edgeCount{ 0 }; };
根据邻接表,可比较容易地统计出有向图中每个顶点的出度。但如果要统计顶点的入度,就需要遍历所有的边节点,其时间复杂度为 O ( e ) O(e) O ( e ) e e e O ( n e ) O(ne) O ( n e ) n n n
一种解决方法是对有向图建立逆邻接表 (顶点的指向关系与邻接表恰好相反),根据逆邻接表,很容易统计出图中每个顶点的入度。
有向图的十字链表:
顶点的结构为:
1 2 3 4 5 6 template <typename T>struct Vertex { T data; Arc* pFirstIn{ nullptr }; Arc* pFirstOut{ nullptr }; };
弧节点的结构为:
1 2 3 4 5 6 struct Arc { std::size_t headVertex{ 0 }; std::size_t tailVertex{ 0 }; Arc* pHeadLink{ nullptr }; Arc* pTailLink{ nullptr }; };
无向图的邻接多重表:
顶点的结构为:
1 2 3 4 5 template <typename T>struct Vertex { T data; Edge* pFirstEdge; };
边节点的结构为:
1 2 3 4 5 6 7 8 9 10 11 12 enum class VisitMark { unvisited, visited }; struct Edge { VisitMark mark{ VisitMark::unvisited }; std::size_t iVertex{ 0 }; std::size_t jVertex{ 0 }; Edge* piLink{ nullptr }; Edge* pjLink{ nullptr }; };
图的基本操作
图的创建操作: (顶点的邻接边按指向顶点索引的大小排序)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 template <typname T>Graph<T> Graph<T>::create () { std::size_t n, e; std::cin >> n >> e; Graph<T> graph (n, e) ; for (std::size_t i = 0 ; i < e; ++i) { std::size_t in, out; int weight; std::cin >> in >> out >> weight; auto pEdge = new Edge (); pEdge->adjVertex = out; pEdge->weight = weight; auto & v = graph.vertices[in]; if (v.pAdjEdge == nullptr ) { v.pAdjEdge = pEdge; } else if (out <= v.pAdjEdge->adjVertex) { pEdge->pLink = v.pAdjEdge; v.pAdjEdge = pEdge; } else { auto p = v.pAdjEdge; while (p->pLink != nullptr ) { if (out <= p->pLink->adjVertex) break ; p = p->pLink; } pEdge->pLink = p->pLink; p->pLink = pEdge; } } return graph; }
图的删边操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 template <typename T>void Graph<T>::remove (std::size_t v0, std::size_t v1) { auto & v = vertices[v0]; if (v.pAdjEdge->adjVertex == v1) { auto pOrigin = v.pAdjEdge; v.pAdjEdge = pOrigin->pLink; delete pOrigin; return ; } auto p = v.pAdjEdge; while (p->pLink != nullptr ) { if (p->pLink->adjVertex == v1) { auto pOrigin = p->pLink; p->pLink = pOrigin->pLink; delete pOrigin; return ; } p = p->pLink; } }
图的遍历
深度优先遍历(depth first search,DFS):
基本思想:
由图中某一起始顶点 v v v w 1 w_1 w 1
再从 w 1 w_1 w 1 w 1 w_1 w 1 w 2 w_2 w 2
然后再从 w 2 w_2 w 2
接着退回到前一次刚访问过的顶点,检查是否还有其它没有被访问的邻接顶点。如果有,则访问此顶点,之后再从此顶点出发,进行与前述类似的访问;如果没有,再退回一步进行搜索;
重复上述过程,直到所有与起始顶点有相通路径的顶点都被访问过为止。
DFS 的递归实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 template <typename T>void dfsMain (const Graph<T>& graph, std::size_t v, std::vector<uint8_t >& visited) std::cout << v; visited[v] = true ; auto p = graph.getVertices ()[v].pAdjEdge; while (p != nullptr ) { if (!visited[p->adjVertex]) dfsMain (graph, p->adjVertex, visited); p = p->pLink; } } template <typename T>void dfsTraversal (const Graph<T>& graph, std::size_t v) auto vertexCount = graph.getVertices ().size (); std::vector<uint8_t > visited (vertexCount, false ) ; for (std::size_t v = 0 ; v < vertexCount; ++v) { if (!visited[v]) dfsMain (graph, v, visited); } }
DFS 的迭代实现(借助栈):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 template <typename T>void dfsTraversal (const Graph<T>& graph) auto vertexCount = graph.getVertices ().size (); std::vector<uint8_t > visited (vertexCount, false ) ; std::stack<std::size_t > vertStack; for (std::size_t i = 0 ; i < vertexCount; ++i) { if (!visited[i]) vertStack.push (i); while (!vertStack.empty ()) { auto v = vertStack.top (); vertStack.pop (); if (!visited[v]) { std::cout << v; visited[v] = true ; auto p = graph.getVertices ()[v].pAdjEdge; while (p != nullptr ) { if (!visited[p->adjVertex]) vertStack.push (p->adjVertex); p = p->pLink; } } } } }
DFS 的时间复杂度分析:设图中有 n n n e e e
如果用邻接表存储,则扫描边的时间复杂度为 O ( e ) O(e) O ( e ) O ( n + e ) O(n + e) O ( n + e )
如果用邻接矩阵存储,则查找一个顶点的所有邻接边的时间复杂度为 O ( n ) O(n) O ( n ) O ( n 2 ) O(n^2) O ( n 2 )
广度优先遍历(breadth first search,BFS):
基本思想:
广度优先搜索是一种分层的搜索过程,每向前走一步可能访问一批顶点,不像深度优先搜索那样有回退的情况。因此,广度优先搜索是一个非递归算法。
为了实现逐层访问,算法中使用了一个队列,以记忆正在访问的这一层和上一层的顶点,以便于向下一层访问。
该算法的演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 template <typename T>void bfsTraversal (const Graph<T>& graph) auto vertexCount = graph.getVertices ().size (); std::vector<uint8_t > visited (vertexCount, false ) ; std::queue<std::size_t > vertQueue; for (std::size_t i = 0 ; i < vertexCount; ++i) { if (!visited[i]) { std::cout << i; visited[i] = true ; vertQueue.push (i); } while (!vertQueue.empty ()) { auto v = vertQueue.front (); vertQueue.pop (); auto p = graph.getVertices ()[v].pAdjEdge; while (p != nullptr ) { if (!visited[p->adjVertex]) { std::cout << p->adjVertex; visited[p->adjVertex] = true ; vertQueue.push (p->adjVertex); } p = p->pLink; } } } }
BFS 的时间复杂度分析:设图中有 n n n e e e
如果使用邻接表存储图,则循环的时间复杂度为 deg ( v 1 ) + deg ( v 2 ) + ⋯ + deg ( v n ) = O ( e ) \deg(v_1) + \deg(v_2) + \cdots + \deg(v_n)= O(e) deg ( v 1 ) + deg ( v 2 ) + ⋯ + deg ( v n ) = O ( e ) O ( n + e ) O(n + e) O ( n + e )
如果使用邻接矩阵,则对于每一个被访问的顶点,循环需要检测矩阵中的 n n n O ( n 2 ) O(n^2) O ( n 2 )
拓扑排序
AOV 网(activity on vertex network): 一种用于表现活动顺序的有向无环图,用顶点表示活动,用有向边表示活动之间的先后关系。
拓扑序列: AOV 网中所有顶点排成的线性序列,要求每个活动的所有前驱活动都排在该活动前面。构造 AOV 网的拓扑序列的过程称为拓扑排序 。
引理: 设图 G = ( V , E ) G = (V, E) G = ( V , E ) V ( G ) ≠ ∅ V(G) \neq \empty V ( G ) = ∅ G G G
拓扑排序算法的基本步骤:
从网中选择一个入度为 0 的顶点并将其输出;
从网中删除该顶点及其所有出边;
重复执行前两个步骤,直至所有顶点都已输出,或者网中剩余顶点的入度均不为 0(说明网中存在回路,无法继续拓扑排序)。
对于无回路的 AOV 网,其顶点一定可以排成拓扑序列,但其拓扑序列未必唯一 。
该算法的演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 template <typename T>bool topoSort (const Graph<T>& graph, std::vector<std::size_t >& topo) topo.clear (); auto vertexCount = graph.getVertices ().size (); std::vector<std::size_t > count (vertexCount, 0 ) ; for (std::size_t i = 0 ; i < vertexCount; ++i) { auto p = graph.getVertices ()[i].pAdjEdge; while (p != nullptr ) { ++count[p->adjVertex]; p = p->pLink; } } std::size_t top = -1 ; for (std::size_t i = 0 ; i < vertexCount; ++i) { if (count[i] == 0 ) { count[i] = top; top = i; } } for (std::size_t i = 0 ; i < vertexCount; ++i) { if (top == -1 ) { std::cerr << "网络中出现环!" ; return false ; } auto j = top; top = count[top]; topo.emplace_back (j); auto p = graph.getVertices ()[j].pAdjEdge; while (p != nullptr ) { auto k = p->adjVertex; --count[k]; if (count[k] == 0 ) { count[k] = top; top = k; } p = p->pLink; } } return true ; }
设 AOV 网的顶点数为 n n n e e e O ( n + e ) O(n + e) O ( n + e )
关键路径
AOE 网(activity on edge network): 一种有向无环的权图,用有向边表示一个工程中的各项活动,边上的权值表示活动的持续时间,用顶点表示事件。
源点: 表示整个工程的开始,即入度为零的顶点。汇点: 表示整个工程的结束,即出度为零的顶点。
在 AOE 网中, 从源点到各个顶点的有向路径可能不止一条,这些路径的长度也可能不同,完成不同路径的活动所需的时间当然也会不同,其中有些活动必须顺序进行,有些活动可以并行进行。但只有各条路径上的所有活动都完成了,整个工程才算完成,
因此,完成整个工程所需的时间取决于从源点到汇点的最长路径长度 ,即路径上所有活动的持续时间之和。路径长度最长的路径被称为关键路径(critical path) 。
任意非空 AOE 网至少存在一条关键路径。
求关键活动的基本步骤:
对 AOE 网进行拓扑排序,若网中有回路,则终止算法;按拓扑次序求出各顶点事件的最早发生时间 v e ve v e
按拓扑序列的逆序求出各顶点事件的最迟发生时间 v l vl v l
根据 v e ve v e v l vl v l a i a_i a i e ( i ) e(i) e ( i ) l ( i ) l(i) l ( i ) e ( i ) = l ( i ) e(i) = l(i) e ( i ) = l ( i ) a i a_i a i
该算法的演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 template <typename T>void criticalPath (const Graph<T>& graph) std::vector<std::size_t > topo; if (!topoSort (graph, topo)) return ; auto vertexCount = graph.getVertices ().size (); std::vector<int > ve (vertexCount, 0 ) ; for (std::size_t i = 0 ; i < vertexCount; ++i) { auto k = topo[i]; auto p = graph.getVertices ()[k].pAdjEdge; while (p != nullptr ) { auto j = p->adjVertex; auto sum = ve[k] + p->weight; if (ve[j] < sum) ve[j] = sum; p = p->pLink; } } decltype (ve) vl (vertexCount, ve.back ()); for (auto i = vertexCount - 1 ; i != -1 ; --i) { auto k = topo[i]; auto p = graph.getVertices ()[k].pAdjEdge; while (p != nullptr ) { auto j = p->adjVertex; auto dif = vl[j] - p->weight; if (vl[k] > dif) vl[k] = dif; p = p->pLink; } } std::cout << "最短完成时间:" << ve.back () << std::endl; for (std::size_t i = 0 ; i < vertexCount; ++i) { auto p = graph.getVertices ()[i].pAdjEdge; while (p != nullptr ) { auto j = p->adjVertex; auto e = ve[i]; auto l = vl[j] - p->weight; if (e == l) std::cout << i << "->" << j << "是关键活动" << std::endl; p = p->pLink; } } }
设 AOE 网的顶点数为 n n n e e e O ( n + e ) O(n + e) O ( n + e ) ve[i]和以拓扑逆序求vl[i]时,所需时间均为 O ( e ) O(e) O ( e ) e和l的时间复杂度为 O ( e ) O(e) O ( e ) O ( n + e ) O(n+e) O ( n + e )
定理: 假设边 ⟨ v i , v j ⟩ \langle v_i, v_j \rangle ⟨ v i , v j ⟩
v l [ j ] − v e [ i ] ≥ w e i g h t ( v i , v j ) vl[j] - ve[i] \geq weight(v_i, v_j)
v l [ j ] − v e [ i ] ≥ w e i g h t ( v i , v j )
如果 ⟨ v i , v j ⟩ \langle v_i, v_j \rangle ⟨ v i , v j ⟩
v l [ j ] − v e [ i ] = w e i g h t ( v i , v j ) vl[j] - ve[i] = weight(v_i, v_j)
v l [ j ] − v e [ i ] = w e i g h t ( v i , v j )
最短路径问题
两顶点间可能存在多条路径,每条路径所经过的边数可能不同,每条路径上的各边权值之和可能不同。从一个指定顶点到达另一指定顶点的路径上各边权值之和最小的路径称为最短路径(shortest path) ,这类问题亦称为最短路径问题 。
无权最短路径
在无权图中,源点到各顶点的路径所经历的边的数目就是路径的长度。求无权最短路径算法的基本思想如下:
l ( u i ) l(u_i) l ( u i ) u 0 u_0 u 0 u i u_i u i l ( u 0 ) = 0 l(u_0) = 0 l ( u 0 ) = 0 l ( u i ) = − 1 ( i ≠ 0 ) l(u_i) = -1\ (i \neq 0) l ( u i ) = − 1 ( i = 0 ) 访问初始顶点 u 0 u_0 u 0 u 0 u_0 u 0 w w w l ( w ) = − 1 l(w) = -1 l ( w ) = − 1 l ( w ) = l ( u 0 ) + 1 l(w)=l(u_0) + 1 l ( w ) = l ( u 0 ) + 1
设 v v v v v v w w w l ( w ) = − 1 l(w) = -1 l ( w ) = − 1 l ( w ) = l ( v ) + 1 l(w) = l(v) + 1 l ( w ) = l ( v ) + 1
处理完 v v v l ( u ) = l ( v ) l(u) = l(v) l ( u ) = l ( v ) u u u l ( u ) = l ( v ) + 1 l(u)=l(v) + 1 l ( u ) = l ( v ) + 1 u u u
该算法的演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 template <typename T>void shortestPath (const Graph<T>& graph, std::size_t start, std::vector<std::size_t >& path, std::vector<std::size_t >& distance) auto vertexCount = graph.getVertices ().size (); path = std::vector <std::size_t >(vertexCount, -1 ); distance = std::vector <std::size_t >(vertexCount, -1 ); std::queue<std::size_t > vertQueue; distance[start] = 0 ; vertQueue.push (start); while (!vertQueue.empty ()) { auto u = vertQueue.front (); vertQueue.pop (); auto p = graph.getVertices ()[u].pAdjEdge; while (p != nullptr ) { auto k = p->adjVertex; if (distance[k] == -1 ) { vertQueue.push (k); distance[k] = distance[u] + 1 ; path[k] = u; } p = p->pLink; } } }
在最短路径的计算中,每个顶点都要入队出队一次,产生 O ( n ) O(n) O ( n ) O ( e ) O(e) O ( e ) O ( n + e ) O(n+e) O ( n + e )
正权最短路径
解决求带有正权值的图的最短路径问题的常用算法是迪杰斯特拉(Dijkstra)算法 ,关于该算法的具体描述请参考 离散数学(二):加权图与 Dijkstra 算法 。
Dijkstra 算法的演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 template <typename T>std::vector<long > dijkstraShortestPath (const Graph<T>& graph, std::size_t start, std::vector<int >& distance, std::vector<std::vector<std::size_t >>& path) auto vertexCount = graph.vertices.size (); distance = std::vector <int >(vertexCount, INT_MAX); path = std::vector<std::vector<std::size_t >>(vertexCount); std::vector<uint8_t > visited (vertexCount, 0 ) ; distance[start] = 0 ; std::size_t u = start; for (std::size_t i = 1 ; i < vertexCount; ++i) { visited[u] = true ; auto p = graph.getVertices ()[u].pAdjEdge; while (p != nullptr ) { auto k = p->adjVertex; if (!visited[k]) { auto sum = distance[u] + p->weight; if (sum < distance[k]) { distance[k] = sum; path[k].emplace_back (u); } } p = p->pLink; } auto ldist = INT_MAX; for (std::size_t j = 0 ; j < vertexCount; ++j) { if (!visited[j] && distance[j] < ldist) { ldist = distance[j]; u = j; } } } }
该算法的时间复杂度为:
O ( ∑ i = 1 n ( n + d i ) ) = O ( n 2 + ∑ i = 1 n d i ) = O ( n 2 + e ) O\left( \sum_{i = 1}^n (n + d_i) \right) = O\left( n^2 + \sum_{i = 1}^n d_i \right) = O(n^2 + e)
O ( i = 1 ∑ n ( n + d i ) ) = O ( n 2 + i = 1 ∑ n d i ) = O ( n 2 + e )
每对顶点间的最短路径
弗洛伊德(Floyd)算法: 运用了动态规划思想,利用一个 n n n A − 1 , A 0 , A 1 , ⋯ , A n − 1 A_{-1}, A_0, A_1, \cdots, A_{n - 1} A − 1 , A 0 , A 1 , ⋯ , A n − 1
定义初始矩阵 A − 1 A_{-1} A − 1 A − 1 ( i , j ) = w e i g h t ( v i , v j ) A_{-1}(i, j) = weight(v_i, v_j) A − 1 ( i , j ) = w e i g h t ( v i , v j )
对于下一个矩阵 A k ( k = 0 , 1 , ⋯ , n − 1 ) A_k\ (k = 0, 1, \cdots, n -1) A k ( k = 0 , 1 , ⋯ , n − 1 )
A k ( i , j ) = min { A k − 1 ( i , j ) , A k − 1 ( i , k ) + A k − 1 ( k , j ) } A_k(i, j) = \min\{ A_{k - 1}(i, j), A_{k - 1}(i, k) + A_{k - 1}(k, j) \}
A k ( i , j ) = min { A k − 1 ( i , j ) , A k − 1 ( i , k ) + A k − 1 ( k , j )}
上述步骤每迭代一次,从顶点 v i v_i v i v j v_j v j A 0 ( i , j ) A_0(i, j) A 0 ( i , j ) v i v_i v i v j v_j v j v 0 v_0 v 0 A k ( i , j ) A_k(i, j) A k ( i , j ) v i v_i v i v j v_j v j k k k A n − 1 ( i , j ) A_{n - 1}(i, j) A n − 1 ( i , j ) v i v_i v i v j v_j v j
Floyd 算法的正确性证明(归纳法):
对于任意两顶点 v i v_i v i v j v_j v j
若从 v i v_i v i v j v_j v j v 0 v_0 v 0
假设若 v i v_i v i v j v_j v j k − 1 k - 1 k − 1
当 v i v_i v i v j v_j v j k k k v i v_i v i v k v_k v k k − 1 k - 1 k − 1 v k v_k v k v j v_j v j k − 1 k - 1 k − 1
由假设可得,算法求出的 v i v_i v i v k v_k v k v k v_k v k v j v_j v j v i v_i v i v k v_k v k v j v_j v j v i , v j v_i, v_j v i , v j k k k
综上所述,该算法正确。
Floyd 算法的演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 template <typename T>void floydShortestPath (const Graph<T>& graph, std::vector<std::vector<int >>& distance, std::vector<std::vector<std::size_t >>& path) auto vertexCount = graph.getVertices ().size (); distance = std::vector<std::vector<int >>(vertexCount, std::vector <int >(vertexCount, 0 )); path = std::vector<std::vector<std::size_t >>(vertexCount, std::vector <std::size_t >(vertexCount, -1 )); for (std::size_t i = 0 ; i < vertexCount; ++i) { for (std::size_t j = 0 ; j < vertexCount; ++j) { auto p = graph.getVertices ()[i].pAdjEdge; while (p != nullptr ) { if (p->adjVertex == j) { distance[i][j] = p->weight; break ; } p = p->pLink; } } } for (std::size_t k = 0 ; k < vertexCount; ++k) { for (std::size_t i = 0 ; i < vertexCount; ++i) { for (std::size_t j = 0 ; j < vertexCount; ++j) { if (distance[i][k] != 0 && distance[k][j] != 0 ) { auto sum = distance[i][k] + distance[k][j]; if (distance[i][j] > sum || distance[i][j] == 0 ) { distance[i][j] = sum; path[i][j] = k; } } } } } }
该算法的时间复杂度为 O ( n 3 ) O(n^3) O ( n 3 ) n n n 带负权值的边组成的回路(即负开销回路) 。
满足约束的最短路径
有些具体问题需要找到在某些约束条件下的最短路径,一种可行的方案是生成两个顶点间按照路径长度非递减次序排列的所有路径,然后逐一测试每条生成的路径是否满足特定的约束条件,第一条满足约束条件的路径即为所求。
求按照路径长度非递减次序排列的所有路径的步骤如下:
设集合 P P P G G G v 1 v_1 v 1 v n v_n v n v 1 v_1 v 1 v n v_n v n p 1 p_1 p 1 Q Q Q e 1 , e 2 , ⋯ , e k e1, e2, \cdots, e_k e 1 , e 2 , ⋯ , e k
将余下的路径(P − { p 1 } P - \{p_1\} P − { p 1 } k k k e k e_k e k e k e_k e k e k − 1 e_{k-1} e k − 1 e k − 1 , e k e_{k-1}, e_k e k − 1 , e k e k − 2 e_{k-2} e k − 2 ⋯ \cdots ⋯ e 2 , ⋯ , e k − 1 , e k e_2, \cdots, e_{k-1}, e_k e 2 , ⋯ , e k − 1 , e k e 1 e_1 e 1
从各个子集选出一条最短的路径加入集合 Q Q Q Q Q Q
重复步骤 2 和步骤 3,直到找出满足要求的路径或找出 v 1 v_1 v 1 v n v_n v n
可以将 “包含的边” 和 “不包含的边” 看成两种约束,算法的目的是寻找满足这些约束的最短路径。
最小生成树
对于一个无向加权连通图,设其顶点个数 n n n e e e e e e n − 1 n - 1 n − 1
这 n − 1 n - 1 n − 1 n n n
该连通图的代价(n − 1 n - 1 n − 1
这样的连通图被称为图的最小生成树(minimum-cost spanning tree,MST) ,也称为最小支撑树 或最优树 。
定理: 设 G = ( V , E ) G = (V, E) G = ( V , E ) U U U V V V u , v u, v u , v
w e i g h t ( u , v ) = min { w e i g h t ( u 0 , u 0 ) ∣ u 0 ∈ U , v 0 ∈ V − U } weight(u, v) = \min\{ weight(u_0, u_0) \ \mid u_0 \in U, v_0 \in V - U \}
w e i g h t ( u , v ) = min { w e i g h t ( u 0 , u 0 ) ∣ u 0 ∈ U , v 0 ∈ V − U }
则必然存在 G G G ⟨ u , v ⟩ \langle u, v \rangle ⟨ u , v ⟩
普里姆(Prim)算法: 设 G = ( V , E ) G = (V, E) G = ( V , E ) T E TE TE G G G
令 U = { v 0 } ( v 0 ∈ V ) , T E = ∅ U= \{v_0\}\ (v_0 \in V),TE = \empty U = { v 0 } ( v 0 ∈ V ) , TE = ∅
将满足以下条件的顶点 v v v U U U ⟨ u , v ⟩ \langle u, v \rangle ⟨ u , v ⟩ T E TE TE
w e i g h t ( u , v ) = min { w e i g h t ( u k , v k ) ∣ u k ∈ U , v k ∈ V − U } weight(u, v)=\min\{ weight(u_k, v_k) \mid u_k \in U, v_k \in V - U \}
w e i g h t ( u , v ) = min { w e i g h t ( u k , v k ) ∣ u k ∈ U , v k ∈ V − U }
反复执行步骤 2, 直至 U = V U = V U = V
Prim 算法的演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 template <typename T>std::vector<Edge> primMst (const Graph<T>& graph) { std::vector<Edge> result; auto vertexCount = graph.getVertices ().size (); std::vector<int > lowcost (vertexCount) ; std::vector<std::size_t > vertices (vertexCount, 0 ) ; for (std::size_t i = 0 ; i < vertexCount; ++i) { lowcost[i] = graph.getEdges ()[0 ][i].weight; } vertices[0 ] = -1 ; for (std::size_t i = 1 ; i < vertexCount; ++i) { std::size_t v = 0 ; int minWeight = -1 ; for (std::size_t j = 0 ; j < vertexCount; ++j) { if (vertices[j] != -1 && lowcost[j] < minWeight) { v = j; minWeight = lowcost[j]; } } if (v == 0 ) { std::cerr << "无边,图不连通!" << std::endl; break ; } Edge edge; edge.start = vertices[v]; edge.end = v; edge.weight = lowcost[v]; result.emplack_back (edge); vertices[v] = -1 ; for (std::size_t j = 0 ; j < vertexCount; ++j) { if (vertices[j] != -1 && graph.getEdges ()[v][j] < lowcost[j]) { lowcost[j] = graph.getEdges ()[v][j].weight; vertices[j] = v; } } } return result; }
Prim 算法的时间复杂度为 O ( n 2 ) O(n^2) O ( n 2 ) 稠密图 的最小生成树。
克鲁斯卡尔(Kruskal)算法: (也可参考 离散数学(二):最优树与 Kruskal 算法 )
设连通图 G = ( V , E ) G = (V, E) G = ( V , E ) T T T G G G
令 T = ( V , ∅ ) T = (V, ∅) T = ( V , ∅ ) T T T n n n n n n
在 E E E E E E
如果该边的两个顶点在 T T T T T T T T T
重复步骤 2 和步骤 3,直至 T T T
Kruskal 算法可以用并查集 实现:
每个连通分量包含的顶点是 V V V
对 E E E
Kruskal 算法的演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 template <typename T>std::vector<Edge> kruskalMst (const Graph<T>& graph) { std::vector<Edge> result; auto vertexCount = graph.getVertices ().size (); std::size_t connComp = vertexCount; DSUTree dsu (vertexCount) ; std::vector<Edge> edges; for (const auto & e : graph.getEdges ()) edges.emplace_back (e); std::sort (edges.begin (), edges.end (), [](const Edge& lhs, const Edge& rhs) { return lhs.weight <= rhs.weight; }); for (auto & edge : edges) { if (connComp <= 1 ) break ; auto v0 = edge.start; auto v1 = edge.end; if (dsu.find (v0) != dsu.find (v1)) { Edge e; e.start = v0; e.end = v1; e.weight = edge.weight; result.emplace_back (e); dsu.merge (v0, v1); --connComp; } } return result; }
Kruskal 算法的时间复杂度为 O ( e log 2 e ) O(e \log_2 e) O ( e log 2 e ) 稀疏图 的最小生成树。
图的应用
有向图的可达性与传递闭包算法:
若图 G G G v i v_i v i v j v_j v j v i v_i v i v j v_j v j v i v_i v i v j v_j v j 可达 (一般认为顶点到其自身是可达的)。
可以用 n × n n \times n n × n R R R 可达矩阵 ,若 v i v_i v i v j v_j v j R i j = 1 R_{ij} = 1 R ij = 1 R i j = 0 R_{ij} = 0 R ij = 0
可达的传递性: 如果 v i v_i v i v j v_j v j v j v_j v j v k v_k v k v i v_i v i v k v_k v k G G G V V V E E E G G G G G G 传递闭包 。
沃舍尔(Warshall)算法: 求有向图可及矩阵的算法,与 Floyd 算法类似,是一个动态规划算法,它的基本步骤是递推地计算一系列 WSM 矩阵。设 A A A
W S M 0 = A ( 加上主对角线元素 1 ) W S M k ( i , j ) = W S M k − 1 ( i , j ) ∨ W S M k − 1 ( i , k ) ∧ W S M k − 1 ( k , j ) , 1 ≤ k ≤ n \begin{aligned}
WSM_0 &= A (\text{加上主对角线元素 1})\\
WSM_k(i, j) &= WSM_{k - 1}(i, j)\\
&\vee WSM_{k - 1}(i, k) \wedge WSM_{k - 1}(k, j), \quad 1 \leq k \leq n
\end{aligned} W S M 0 W S M k ( i , j ) = A ( 加上主对角线元素 1 ) = W S M k − 1 ( i , j ) ∨ W S M k − 1 ( i , k ) ∧ W S M k − 1 ( k , j ) , 1 ≤ k ≤ n
其中 W S M k ( i , j ) WSM_k(i, j) W S M k ( i , j ) i i i 1 , 2 , ⋯ , k 1, 2, \cdots, k 1 , 2 , ⋯ , k j j j
求连通分量的算法:
算法中使用两个表 A A A B B B
选取一个不在 A A A v v v A A A B B B v v v v v v L L L
对 L L L w w w w w w v v v w w w v v v w w w A A A B B B
在处理完 L L L B B B G G G B B B
反复执行以上步骤,直至顶点表中的所有顶点均在 A A A
排序
对于 n n n R 1 , R 2 , ⋯ , R n R_1, R_2, \cdots, R_n R 1 , R 2 , ⋯ , R n K 1 , K 2 , ⋯ , K n K_1, K_2, \cdots, K_n K 1 , K 2 , ⋯ , K n
ρ = [ 0 1 ⋯ n − 1 ρ ( 0 ) ρ ( 1 ) ⋯ ρ ( n − 1 ) ] \rho = \begin{bmatrix}
0 & 1 & \cdots & n - 1 \\
\rho(0) & \rho(1) & \cdots & \rho(n - 1) \\
\end{bmatrix} ρ = [ 0 ρ ( 0 ) 1 ρ ( 1 ) ⋯ ⋯ n − 1 ρ ( n − 1 ) ]
使得各关键词按照非递减的次序排列,即
K ρ ( 0 ) ≤ K ρ ( 1 ) ≤ ⋯ ≤ K ρ ( n − 1 ) K_{\rho(0)} \leq K_{\rho(1)} \leq \cdots \leq K_{\rho(n - 1)}
K ρ ( 0 ) ≤ K ρ ( 1 ) ≤ ⋯ ≤ K ρ ( n − 1 )
如果进一步要求具有相同关键词的记录保持它们原来的相对次序,即当 K ρ ( i ) = K ρ ( j ) K_{\rho(i)} = K_{\rho(j)} K ρ ( i ) = K ρ ( j ) i < j i < j i < j ρ ( i ) < ρ ( j ) \rho(i) < \rho(j) ρ ( i ) < ρ ( j ) 稳定性 。
排序的分类有:
内排序:完全在内存中进行的排序。
外排序:在外部存储器上进行的排序。
基于关键词比较的排序。
分布排序算法。
插入排序
直接插入排序
基本思想: 将一个记录插入到已排好序的有序表中,从而得到一个新的、记录数增加 1 的有序表。
直接插入排序算法的演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 template <typename T>void insertSort (std::vector<T>& src) for (std::size_t i = 1 ; i < src.size (); ++i) { auto temp = src[i]; std::size_t j = i - 1 ; while (temp < src[j]) { src[j + 1 ] = src[j]; --j; if (j == -1 ) break ; } src[j + 1 ] = temp; } }
算法分析: 设 d j d_j d j R j R_j R j K j K_j K j
∑ j = 2 n ( 1 + d j ) = ( n − 1 ) + ∑ j = 2 n d j \sum_{j = 2}^n (1 + d_j) = (n - 1) + \sum_{j = 2}^n d_j
j = 2 ∑ n ( 1 + d j ) = ( n − 1 ) + j = 2 ∑ n d j
记录的移动次数为
( n − 1 ) + ( n − 1 ) + ∑ j = 2 n d j = 2 n − 2 + ∑ j = 2 n d j (n - 1) + (n - 1) + \sum_{j = 2}^n d_j = 2n - 2 + \sum_{j = 2}^n d_j
( n − 1 ) + ( n − 1 ) + j = 2 ∑ n d j = 2 n − 2 + j = 2 ∑ n d j
最好情况下,排序前记录已经按关键词从小到大有序排列,每趟只需与前面的有序部分的最后一个记录的关键词比较 1 1 1 2 2 2 n − 1 n - 1 n − 1 2 ( n − 1 ) 2(n - 1) 2 ( n − 1 )
最坏情况下,第 j j j j j j d j d_j d j j − 1 j - 1 j − 1 1 1 1 1 1 1 ( n − 1 ) ( n + 2 ) 2 \dfrac{(n - 1)(n + 2)}{2} 2 ( n − 1 ) ( n + 2 ) ( n − 1 ) ( n + 4 ) 2 \dfrac{(n - 1)(n + 4)}{2} 2 ( n − 1 ) ( n + 4 )
平均情况下,设待排序文件中记录所有可能排列的概率相同,则关键词比较次数为 ( n − 1 ) ( n + 4 ) 4 \dfrac{(n - 1)(n + 4)}{4} 4 ( n − 1 ) ( n + 4 ) ( n − 1 ) ( n + 8 ) 4 0 \dfrac{(n - 1)(n + 8)}{4}0 4 ( n − 1 ) ( n + 8 ) 0
综上所述,直接插入排序的时间复杂度为 O ( n 2 ) O(n^2) O ( n 2 )
直接插入排序算法的优点:
算法易于书写,执行过程非常清晰。
直接插入排序是稳定 的排序算法。
直接插入排序算法的缺点: 时间复杂度高。
对于顺序存储结构,可以通过将顺序查找改为二分查找,构造二分 / 对半插入排序算法 来提高排序效率,但对链接存储结构无效。
希尔(Shell)排序
基本思想: 把记录按下标的一定增量进行分组,对每组使用直接插入排序法,随着增量逐渐减少,每个分组内包含的关键词也就越来越多,当增量减至 1 时,整个文件恰好被分成一个组,随后算法终止。
若以 ⌊ n 2 ⌋ \left\lfloor \dfrac{n}{2} \right\rfloor ⌊ 2 n ⌋
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 template <typename T>void shellShort (std::vector<T>& src) auto n = src.size (); auto d = n / 2 ; while (d > 0 ) { for (auto i = d; i < n; ++i) { auto j = i - d; auto temp = src[i]; while (temp < src[j]) { src[j + d] = src[j]; if (j < d) { j -= d; break ; } j -= d; } src[j + d] = temp; } d /= 2 ; } }
Shell 算法的性能与所选取的分组长度序列 有很大关系。上述算法中使用的是最简单的分组长度序列,即 n 2 i \dfrac{n}{2^i} 2 i n O ( n 2 ) O(n^2) O ( n 2 ) 2.2 2.2 2.2 2 k − 1 2^k - 1 2 k − 1 O ( n 3 2 ) O(n^{\frac{3}{2}}) O ( n 2 3 )
Knuth 利用大量的实验统计得出,当 n n n n 1.25 n^{1.25} n 1.25 1.6 n 1.25 1.6n^{1.25} 1.6 n 1.25
Shell 算法是不稳定 的排序算法。
交换排序
冒泡排序
基本思想: 从左到右比较相邻记录的关键词,交换逆序的记录(即若 K j > K j + 1 K_j > K_{j + 1} K j > K j + 1 R j R_j R j R j + 1 R_{j + 1} R j + 1
冒泡排序算法的演示代码如下:
1 2 3 4 5 6 7 8 9 template <typename T>void bubbleSort (std::vector<T>& src) for (std::size_t i = src.size () - 1 ; i >= 1 ; --i) { for (std::size_t j = 0 ; j < i; ++j) { if (src[j] > src[j + 1 ]) std::swap (src[j], src[j + 1 ]); } } }
上述算法有以下可以改进的地方:
一旦发现某趟扫描中无任何记录交换时,就终止算法;
如果发现从某个位置 t t t R t R_t R t R n R_n R n t t t
改进后的算法演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 template <typename T>void bubbleSort (std::vector<T>& src) auto bound = src.size () - 1 ; while (bound > 0 ) { std::size_t t = 0 ; for (std::size_t i = 0 ; i < bound; ++i) { if (src[i] > src[i + 1 ]) { std::swap (src[i], src[i + 1 ]); t = i; } } bound = t; } }
假定记录序列 R 1 , R 2 , ⋯ , R n R_1,R_2,\cdots,R_n R 1 , R 2 , ⋯ , R n A = { K 1 , K 2 , ⋯ , K n } A= \{ K_1, K_2, \cdots, K_n \} A = { K 1 , K 2 , ⋯ , K n } b i b_i b i A A A i i i { b 1 , b 2 , ⋯ , b n } \{ b_1, b_2, \cdots, b_n \} { b 1 , b 2 , ⋯ , b n } A A A 反序表 。
定理: 设 { K 1 , K 2 , ⋯ , K n } \{ K_1, K_2, \cdots, K_n \} { K 1 , K 2 , ⋯ , K n } { 1 , 2 , ⋯ , n } \{ 1, 2, \cdots, n \} { 1 , 2 , ⋯ , n } { b 1 , b 2 , ⋯ , b n } \{ b_1, b_2, \cdots, b_n \} { b 1 , b 2 , ⋯ , b n } { K 1 , K 2 , ⋯ , K n } \{ K_1, K_2, \cdots, K_n \} { K 1 , K 2 , ⋯ , K n } { K 1 ′ , K 2 ′ , ⋯ , K n ′ } \{ K_1', K_2', \cdots, K_n' \} { K 1 ′ , K 2 ′ , ⋯ , K n ′ } b 1 , b 2 , ⋯ , b n b_1, b_2, \cdots, b_n b 1 , b 2 , ⋯ , b n 1 1 1
算法分析:
最好情况下,初始时记录已经按关键词从小到大排好序,此时算法只执行一趟冒泡,关键词比较次数为 n − 1 n - 1 n − 1
最坏情况下,算法执行了 n − 1 n - 1 n − 1 k k k n − k n - k n − k n − k n-k n − k ( n − 1 ) n 2 \dfrac{(n-1)n}{2} 2 ( n − 1 ) n
综上所述,冒泡算法在最好情况下的时间复杂度为 O ( n ) O(n) O ( n ) O ( n 2 ) O(n^2) O ( n 2 )
推论: 冒泡算法的趟数为 A = 1 + max { b 1 , b 2 , ⋯ , b n } A = 1 + \max\{ b_1, b_2, \cdots, b_n \} A = 1 + max { b 1 , b 2 , ⋯ , b n } B = ∑ i = 0 n − 1 b i B = \sum\limits_{i = 0}^{n - 1} b_i B = i = 0 ∑ n − 1 b i C = ∑ k = 0 A b o u n d k C = \sum\limits_{k = 0}^A bound_k C = k = 0 ∑ A b o u n d k
冒泡排序是稳定 的排序算法。
快速排序(分划交换排序)
基本思想: 任取待排序文件中的某个记录作为基准,按照该记录的关键词大小,将整个文件划分为左右两个子文件:
左侧子文件中所有记录的关键词都小于或等于基准记录的关键词;
右侧子文件中所有记录的关键词都大于基准记录的关键词;
基准记录排在这两个子文件中间(这也是该记录的最终位置)。
分别对两个子文件重复上述操作,直至所有记录都排在相应位置上。
Hoare 分划方法:
选择一个基准值,可以是序列中的任意一个元素;
定义两个指针,一个指向序列的起始位置,一个指向序列的末尾位置;
移动右指针,直到找到一个小于等于基准值的元素;
移动左指针,直到找到一个大于等于基准值的元素;
如果此时左指针小于右指针,则交换左右指针指向的元素;
继续移动左右指针,直到左指针大于右指针;
将基准值与右指针指向的元素交换,并返回右指针的位置。
演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 int partition (std::vector<int >& src, int left, int right) int base = src[left]; int begin = left; int end = right + 1 ; while (begin < end) { ++begin; while (src[begin] <= base) ++begin; --end; while (src[end] > base) --end; if (begin < end) std::swap (src[begin], src[end]); } std::swap (src[left], src[end]); return end; }
和以下写法等价:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 template <typename T>int partition (std::vector<T>& src, int left, int right) auto begin = left; auto base = src[begin]; while (left < right) { while (left < right && src[right] >= base) --right; while (left < right && src[left] <= base) ++left; std::swap (src[left], src[right]); } std::swap (src[begin], src[right]); return right; }
挖坑分划方法:
选择一个基准值,可以是序列中的任意一个元素;
定义两个指针,一个指向序列的起始位置,一个指向序列的末尾位置;
第一个坑为基准值的位置,右指针向左找小于基准值的元素,并将其填在坑上,原位置成为新的坑;
左指针向右找大于基准值的元素,并将其填在坑上,原位置成为新的坑;
最终左指针与右指针相遇,将基准值填在坑上,并返回坑的位置。
演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 template <typename T>int partition (std::vector<T>& src, int left, int right) auto base = src[left]; while (left < right) { while (left < right && src[right] >= base) --right; src[left] = src[right]; while (left < right && src[left] <= base) ++left; src[right] = src[left]; } src[left] = base; return left; }
快速排序算法的演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 template <typename T>void qsort (std::vector<T>& src, int left, int right) if (left < right) { auto pos = partition (src, left, right); qsort (src, left, pos - 1 ); qsort (src, pos + 1 , right); } } template <typename T>void qsort (std::vector<T>& src) qsort (src, 0 , static_cast <int >(src.size () - 1 )); }
最坏情况下,待排序记录序列已按关键词从小到大(或从大到小)排好序,此时每次分划只能得到一个比上一次少一个记录的子序列,这样就必须经过 n − 1 n - 1 n − 1 i i i n − i + 2 n - i + 2 n − i + 2 i i i
( n + 1 ) + n + ⋯ + 3 = ( n − 1 ) ( n + 4 ) 2 (n + 1) + n + \cdots + 3 = \dfrac{(n - 1)(n + 4)}{2}
( n + 1 ) + n + ⋯ + 3 = 2 ( n − 1 ) ( n + 4 )
此时快速排序的速度将退化到简单排序的水平,比直接插入排序还慢。
一种改进方法是取每个待排序记录序列的第一个记录、最后一个记录和接近序列正中位置的记录,在这三个记录中取关键词大小居中者作为基准记录。
改进算法的演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 template <typename T>int getMid (const std::vector<T>& src, int left, int right) int mid = left + (right - left) / 2 ; if (src[left] > src[mid]) { if (src[mid] > src[right]) return mid; if (src[left] > src[right]) return right; return left; } if (src[mid] < src[right]) return mid; if (src[left] < src[right]) return right; return left; } template <typename T>int partition (std::vector<T>& src, int left, int right) auto mid = getMid (src, left, right); std::swap (src[left], src[mid]); auto begin = left; auto base = src[begin]; while (left < right) { while (left < right && src[right] >= base) --right; while (left < right && src[left] <= base) ++left; std::swap (src[left], src[right]); } std::swap (src[begin], src[right]); return right; }
算法分析:
最好时间复杂度为 O ( n 2 ) O(n^2) O ( n 2 )
最坏和平均时间复杂度为 O ( n log 2 n ) O(n \log_2 n) O ( n log 2 n )
空间复杂度为 O ( log 2 n ) O(\log_2 n) O ( log 2 n )
快速排序是不稳定 的排序算法。
快速排序方法是目前内部排序中最好、最快的排序方法。
选择排序
直接选择排序
基本思想: 在第 i ( i = 0 , 1 , ⋯ , n − 2 ) i\ (i = 0, 1, \cdots, n - 2) i ( i = 0 , 1 , ⋯ , n − 2 ) n − i + 1 n - i + 1 n − i + 1 i i i n − i + 1 n - i + 1 n − i + 1
选择排序算法的演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 template <typename T>void selectionSort (std::vector<T>& src) for (std::size_t i = 0 ; i < src.size () - 1 ; ++i) { auto min = i; for (std::size_t j = i + 1 ; j < src.size (); ++j) { if (src[j] < src[min]) min = j; } std::swap (src[i], src[min]); } }
算法分析:
时间复杂度为 O ( n 2 ) O(n^2) O ( n 2 )
空间复杂度为 O ( 1 ) O(1) O ( 1 )
直接选择排序是不稳定 的排序算法。
锦标赛排序
锦标赛排序是对直接选择排序的改进,直接选择排序算法的时间大部分浪费在关键词的比较上,而锦标赛排序用树形结构保存了前面比较的结果,下一次选择时直接利用前面比较的结果,从而大大减少比较次数。
基本思想:
对于 n n n ⌈ n 2 ⌉ \left\lceil \dfrac{n}{2} \right\rceil ⌈ 2 n ⌉
对这 ⌈ n 2 ⌉ \left\lceil \dfrac{n}{2} \right\rceil ⌈ 2 n ⌉
如此重复,直到选出一个关键词最大的记录为止。
将每次两两比较的优胜者作为父节点,这样形成的树称为竞赛树 ;位于最底层的叶子节点称为竞赛树的外节点 ,非叶子节点称为竞赛树的内节点 ;比赛树的最顶层是树的根,表示最后选择出来的具有最大关键词的记录。
算法分析:
除第一次选择具有最大关键词的记录需要进行 n − 1 n-1 n − 1 O ( log 2 2 n ) O(\log_2 2n) O ( log 2 2 n ) O ( n log 2 2 n ) O(n \log_2 2n) O ( n log 2 2 n )
对于 n n n 2 n − 1 2n-1 2 n − 1
堆排序
最大堆: 任意节点的关键词大于等于 它的两个子节点的关键词的完全二叉树,也称为大顶堆 ,在堆排序算法中用于升序排列。
最小堆: 任意节点的关键词小于等于 它的两个子节点的关键词的完全二叉树,也称为小顶堆 ,在堆排序算法中用于降序排列。
堆排序的基本思想:
如果 n n n
调整后,R[0] 就是 R[1], R[2], …, R[n - 2] 中最大的记录,然后再交换 R[0] 与 R[n - 2],使得最大记录放在 R[n - 2] 处,再对 R[0], R[1], …, R[n - 3] 进行调整,使它们重新构成一个堆;
重复上述步骤,直到调整范围只剩下一个记录 R[0] 为止,此时 R[0] 是所有记录中最小的,且数组 R 中的记录已经按关键词从小到大排列了。
重建堆算法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 template <typename T>void restoreHeap (std::vector<T>& src, int begin, int end) auto parent = begin; auto child = parent * 2 + 1 ; while (child <= end) { if (child + 1 <= end && src[child] < src[child + 1 ]) ++child; if (src[parent] < src[child]) { std::swap (src[parent], src[child]); parent = child; child = parent * 2 + 1 ; } else { return ; } } }
堆排序算法的演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 template <typename T>void heapSort (std::vector<T>& src) auto n = static_cast <int >(src.size ()); for (auto i = n / 2 - 1 ; i >= 0 ; --i) { restoreHeap (src, i, n - 1 ); } for (auto i = n - 1 ; i > 0 ; --i) { std::swap (src[0 ], src[i]); restoreHeap (src, 0 , i - 1 ); } }
算法分析:
时间复杂度为 O ( n log 2 n ) O(n \log_2 n) O ( n log 2 n )
空间复杂度为 O ( 1 ) O(1) O ( 1 )
堆排序是不稳定 的排序算法。
归并排序
合并过程的基本思想: 将一个序列分成两个表 A 和 B,且它们已经各自排序完成,则
分别定义表 A 和 B 的头指针 i 和 j;
当 i 和 j 分别在两个表内变化时,通过比较 A[i] 与 B[j] 的关键词大小,依次把关键词小的对象放到新表中;
当 i 与 j 中有一个超出表长时,将另一个表中的剩余部分照抄到新表中。
合并算法的演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 template <typename T>void merge (std::vector<T>& src, std::size_t begin, std::size_t mid, std::size_t end) std::vector temp (src) ; std::size_t i = begin, j = mid + 1 , k = begin; while (i <= mid && j <= end) { if (temp[i] <= temp[j]) { src[k] = temp[i]; ++i; } else { src[k] = temp[j]; ++j; } ++k; } while (i <= mid) { src[k] = temp[i]; ++i; ++k; } while (j <= end) { src[k] = temp[j]; ++j; ++k; } }
二路归并排序的基本思想:
将 n n n n 2 \dfrac{n}{2} 2 n
对两个子序列进行递归地排序;
合并两个已排序的子序列得到排序结果。
二路归并排序算法的演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 template <typename T>void mergeSort (std::vector<T>& src, std::size_t begin, std::size_t end) if (begin < end) { auto mid = (begin + end) / 2 ; mergeSort (src, begin, mid); mergeSort (src, mid + 1 , end); merge (src, begin, mid, end); } } template <typename T>void mergeSort (std::vector<T>& src) mergeSort (src, 0 , src.size () - 1 ); }
算法分析:
时间复杂度为 O ( n log 2 n ) O(n \log_2 n) O ( n log 2 n )
归并排序占用的附加存储空间较大,需要另外一个与原待排序对象数组同样大小的辅助数组,空间复杂度为 O ( n ) O(n) O ( n )
归并排序是稳定 的排序算法。
基于关键词比较的排序算法分析
排序方法
最好时间
平均时间
最坏时间
辅助空间
稳定性
直接插入排序
O ( n ) O(n) O ( n ) O ( n 2 ) O(n^2) O ( n 2 ) O ( n 2 ) O(n^2) O ( n 2 ) O ( 1 ) O(1) O ( 1 ) 稳定
直接选择排序
O ( n 2 ) O(n^2) O ( n 2 ) O ( n 2 ) O(n^2) O ( n 2 ) O ( n 2 ) O(n^2) O ( n 2 ) O ( 1 ) O(1) O ( 1 ) 不稳定
冒泡排序
O ( n ) O(n) O ( n ) O ( n 2 ) O(n^2) O ( n 2 ) O ( n 2 ) O(n^2) O ( n 2 ) O ( 1 ) O(1) O ( 1 ) 稳定
希尔排序
O ( n 1.25 ) O(n^{1.25}) O ( n 1.25 ) 不稳定
快速排序
O ( n log 2 n ) O(n \log_2 n) O ( n log 2 n ) O ( n log 2 n ) O(n \log_2 n) O ( n log 2 n ) O ( n 2 ) O(n^2) O ( n 2 ) O ( log 2 n ) O(\log_2 n) O ( log 2 n ) 不稳定
堆排序
O ( n log 2 n ) O(n \log_2 n) O ( n log 2 n ) O ( n log 2 n ) O(n \log_2 n) O ( n log 2 n ) O ( n log 2 n ) O(n \log_2 n) O ( n log 2 n ) O ( 1 ) O(1) O ( 1 ) 不稳定
归并排序
O ( n log 2 n ) O(n \log_2 n) O ( n log 2 n ) O ( n log 2 n ) O(n \log_2 n) O ( n log 2 n ) O ( n log 2 n ) O(n \log_2 n) O ( n log 2 n ) O ( n ) O(n) O ( n ) 稳定
分治法的基本思想: 将一个输入规模为 n n n k k k
分治排序包括三个步骤:
分:将记录文件划分为若干子部分,一般为二分,可以证明多分策略效果不会优于二分策略;
治:对子部分递归执行算法;
合:将子部分处理后的结果整合在一起。
合并排序侧重 “合”,“分” 的过程就是简单的二分;
快速排序侧重 “分”,在 “分” 的过程中调整了两个子集的元素,而 “合” 的过程无需任何操作。
若所分成的两个子问题的输入规模大致相等,则分治排序的计算时间可表示为:
T ( n ) = { g ( n ) , 当 n 足够小 2 T ⋅ n 2 + f ( n ) T(n) = \begin{cases}
g(n), & \text{当} \ n \ \text{足够小} \\
2T \cdot \dfrac{n}{2} + f(n)
\end{cases} T ( n ) = { g ( n ) , 2 T ⋅ 2 n + f ( n ) 当 n 足够小
其中 g ( n ) g(n) g ( n ) f ( n ) f(n) f ( n )
基于关键词比较的排序算法下界: 如果一个领域问题的输入大小为 n n n L ( n ) L(n) L ( n ) 时间复杂度下界 为 L ( n ) L(n) L ( n ) n log 2 n n \log_2 n n log 2 n
分布排序
基数排序
假设记录 R 1 , R 2 , ⋯ , R n R_1, R_2, \cdots, R_n R 1 , R 2 , ⋯ , R n K 1 , K 2 , ⋯ , K n K_1, K_2, \cdots, K_n K 1 , K 2 , ⋯ , K n
K i = ( K i , p , K i , p – 1 , ⋯ , K i , 0 ) K_i = (K_{i, p}, K_{i, p – 1}, \cdots,K_{i, 0})
K i = ( K i , p , K i , p –1 , ⋯ , K i , 0 )
且对任意 t ( 0 ≤ t ≤ p ) t\ (0 \leq t \leq p) t ( 0 ≤ t ≤ p ) 0 ≤ K i , t < r 0 \leq K_{i, t} < r 0 ≤ K i , t < r r r r 基数 。
基数排序按照关键词的字典序,由小到大进行排列,规定:当且仅当存在 t ≤ p t \leq p t ≤ p t < s ≤ p t < s \leq p t < s ≤ p K i , s = K j , s K_{i, s} = K_{j, s} K i , s = K j , s K i , t < K j , t K_{i, t} < K_{j, t} K i , t < K j , t
K i = ( K i , p , ⋯ , K i , 0 ) < K j = ( K j , p , ⋯ , K j , 0 ) K_i = (K_{i, p},\cdots,K_{i, 0}) < K_j = (K_{j, p}, \cdots, K_{j, 0})
K i = ( K i , p , ⋯ , K i , 0 ) < K j = ( K j , p , ⋯ , K j , 0 )
最高次序位法(MSD): 先按高位分桶,然后在桶内进行排序。
最低次序位法(LSD): 先按最低位排序,然后按下一个次低位排序,以此类推,直到最后按最高位排序。
LSD 基数排序的过程演示:
计数排序
如果已知 K 0 , K 1 , ⋯ , K n − 1 K_0,K_1,\cdots,K_{n - 1} K 0 , K 1 , ⋯ , K n − 1 ( K 0 , K n ) (K_0, K_n) ( K 0 , K n )
例如,如果 K 0 , K 1 , ⋯ , K n − 1 K_0,K_1,\cdots,K_{n - 1} K 0 , K 1 , ⋯ , K n − 1 ( K 0 , K n ) (K_0, K_n) ( K 0 , K n ) b b b B 1 , B 2 , ⋯ , B b B_1, B_2, \cdots, B_b B 1 , B 2 , ⋯ , B b B j ( 0 ≤ j < n ) B_j\ (0 \leq j < n) B j ( 0 ≤ j < n )
K 0 + K n + 1 − K 0 b ( j − 1 ) < K i ≤ K 0 + K n + 1 − K 0 b j K_0 + \frac{K_{n + 1} - K_0}{b} (j - 1) < K_i \leq K_0 + \frac{K_{n + 1} - K_0}{b} j
K 0 + b K n + 1 − K 0 ( j − 1 ) < K i ≤ K 0 + b K n + 1 − K 0 j
那么给定 K i K_i K i
计数排序的过程演示:
计数排序算法的时间复杂度为 O ( n ) O(n) O ( n )
模拟 STL sort
众所众知,快速排序是目前已知平均情况下最快的排序算法,但其最坏情况下时间复杂度会退化为 O ( n 2 ) O(n^2) O ( n 2 ) sort函数基于快速排序算法实现,但对其做了巧妙的改进,使其在最坏情况下时间复杂度也能维持在 O ( n log n ) O(n \log{n}) O ( n log n )
快速排序算法最坏情况下时间复杂度退化为 O ( n 2 ) O(n^2) O ( n 2 ) O ( n ) O(n) O ( n ) sort函数在划分操作有恶化倾向时,能够自行改为堆排序,使效率维持在堆排序的 O ( n log n ) O(n \log{n}) O ( n log n )
传统的快速排序在数据量很小时,为极小的子数组产生许多的递归调用,得不偿失。为此,STL 的sort函数进行了优化,在小数据量(小于等于某个阈值threshold)的情况下改用插入排序。
“三数取中” 选基准元素。不是选取第一个元素作为基准元素,而是在当前子数组中选取3个元素,取中间大的那个元素作为基准元素。从而保证选出的基准元素不是子数组的最小元素,也不是最大元素,避免分划分到子数组最边上,以降低最坏情况发生的概率。
将尾递归转为循环。即先递归处理左区间,后循环处理右区间,从而消除一个尾递归,以减少递归调用带来的时空消耗。
模拟 STL 的sort函数的具体代码如下:
主函数:
1 2 3 4 5 6 7 void sort (std::vector<int >& src) if (n > 0 ) { auto n = src.size (); introsort (src, 0 , n - 1 , log2 (n) * 2 ); finalsort (src); } }
划分和快速排序(主递归调用):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 void moveMedian (std::vector<int >& src, int a, int b, int c) std::swap (src[b], src[a + 1 ]); if (src[c] < src[a + 1 ]) std::swap (src[c], src[a + 1 ]); if (src[c] < src[a]) std::swap (src[c], src[a]); if (src[a] < src[a + 1 ]) std::swap (src[a], src[a + 1 ]); } pair<int , int > partition (std::vector<int >& src, int left, int right, int pivot) { auto base = src[pivot]; auto i = left; auto j = left; auto k = right; while (j <= k) { if (src[j] < base) { std::swap (src[j], src[i]); ++i; ++j; } else if (src[j] > base) { std::swap (src[j], src[k]); --k; } else { ++j; } } return make_pair <int , int >(i - 1 , k + 1 ); } pair<int , int > partitionPivot (std::vector<int >& src, int left, int right) { auto mid = (left + right) / 2 ; moveMedian (src, left, mid, right); return partition (src, left, right, left); } void introsort (std::vector<int >& src, int left, int right, int depthLimit) while (right - left >= threshold) { if (depthLimit == 0 ) { partialsort (src, left, right); return ; } --depthLimit; auto cut = partitionPivot (src, left, right); if (cut.first - left <= right - cut.second) { introsort (src, left, cut.first, depthLimit); left = cut.second; } else { introsort (src, cut.second, right, depthLimit); right = cut.first; } } }
部分排序(堆排序):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 void restoreHeap (std::vector<int >& src, int left, int right) int parent = left; int child = parent * 2 + 1 ; while (child <= right) { if (child + 1 <= right && src[child] < src[child + 1 ]) ++child; if (src[parent] < src[child]) { std::swap (src[parent], src[child]); parent = child; child = parent * 2 + 1 ; } else { return ; } } } void partialsort (std::vector<int >& src, int left, int right) auto n = right - left + 1 ; std::vector<int > temp (n) ; for (int i = 0 ; i < n; ++i) { temp[i] = src[left + i]; } for (int i = n / 2 - 1 ; i >= 0 ; --i){ restoreHeap (A, i, n - 1 ); } for (int i = n - 1 ; i > 0 ; --i){ std::swap (A[0 ], A[i]); restoreHeap (A, 0 , i - 1 ); } for (int i = 0 ; i < n; ++i) { src[left + i] = temp[i]; } }
最终排序(插入排序):
1 2 3 4 5 6 7 8 9 10 11 12 13 void finalsort (std::vector<int >& src) for (int i = 2 ; i <= n; ++i) { int temp = src[i]; int j = i - 1 ; while (temp < src[j]) { src[j + 1 ] = src[j]; --j; if (j == -1 ) break ; } src[j + 1 ] = temp; } }
查找
查找表: 由同一类型的数据元素构成的集合,包含 N N N K K K K K K
查找表的操作:
静态查找表:建表、查找、读表;
动态查找表:建表、查找、读表、插入、删除。
查找算法的特征:
属于内查找还是外查找。
静态查找时,表的内容不变;动态查找时,表中的内容不断地变化。
原词系指使用原来的关键词,变词系指使用经过变换的
指进行比较的时候,是否使用数字性质。
顺序查找
无序表的顺序查找
基本思想: 从 n n n K i = K K_i = K K i = K i > n i > n i > n
无序表顺序查找算法的演示代码如下:
1 2 3 4 5 6 7 template <typename T>std::size_t seqSearch (const std::vector<T>& src, const T& key) { for (std::size_t i = 0 ; i < src.size (); ++i) if (src[i] == key) return i; return -1 ; }
算法分析:
E ( n ) = ∑ i = 1 n P i ⋅ C i = 1 n ∑ i = 1 n i = n + 1 2 E(n) = \sum_{i = 1}^{n} P_i \cdot C_i = \frac{1}{n} \sum_{i = 1}^{n} i = \frac{n + 1}{2}
E ( n ) = i = 1 ∑ n P i ⋅ C i = n 1 i = 1 ∑ n i = 2 n + 1
查找失败的查找长度为 n + 1 n + 1 n + 1
顺序查找的时间复杂度为 O ( n ) O(n) O ( n )
有序表的顺序查找
如果只对表查找一次,则顺序查找要比排序快;但如果要对同一个表进行多次查找,则将表按序排列再进行查找是个更好的方法。
有序表顺序查找算法的演示代码如下:
1 2 3 4 5 6 7 8 9 template <typename T>std::size_t sequenceSearch (const std::vector<T>& src, const T& key) { std::size_t i = 0 ; while (src[i] < key) ++i; if (src[i] == key) return i; return -1 ; }
算法分析:
查找成功的平均查找长度为 n + 1 2 \dfrac{n+1}{2} 2 n + 1
查找失败的查找长度为 n + 1 2 \dfrac{n+1}{2} 2 n + 1
基于关键词比较的查找
二分查找
基本思想: 将 K K K K ⌊ n 2 ⌋ K_{\lfloor \frac{n}{2} \rfloor} K ⌊ 2 n ⌋
K < K ⌊ n 2 ⌋ K < K_{\lfloor \frac{n}{2} \rfloor} K < K ⌊ 2 n ⌋ K > K ⌊ n 2 ⌋ K > K_{\lfloor \frac{n}{2} \rfloor} K > K ⌊ 2 n ⌋ K = K ⌊ n 2 ⌋ K = K_{\lfloor \frac{n}{2} \rfloor} K = K ⌊ 2 n ⌋
重复上述过程,直至找到所查记录或确定该记录不在表中。
二分查找算法的演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 template <typename T>std::size_t binarySearch (const std::vector<T>& src, const T& key) { std::size_t left = 0 ; std::size_t right = src.size () - 1 ; while (left <= right) { auto mid = left + (right - left) / 2 ; if (src[mid] < key) left = mid + 1 ; else if (src[mid] > key) right = mid - 1 ; else return mid; } return -1 ; }
二叉判定树: 二叉判定树 T ( s , e ) T(s, e) T ( s , e ) s s s e e e
当 e − s + 1 ≤ 0 e - s + 1 \leq 0 e − s + 1 ≤ 0 T ( s , e ) T(s, e) T ( s , e )
当 e − s + 1 > 0 e - s + 1 >0 e − s + 1 > 0 ⌊ e + s 2 ⌋ \lfloor \dfrac{e+s}{2} \rfloor ⌊ 2 e + s ⌋ R s , R s + 1 , ⋯ , R ⌊ e + s 2 ⌋ − 1 R_s, R_{s + 1}, \cdots, R_{\lfloor \frac{e+s}{2} \rfloor - 1} R s , R s + 1 , ⋯ , R ⌊ 2 e + s ⌋ − 1 R ⌊ e + s 2 ⌋ + 1 , R ⌊ e + s 2 ⌋ + 2 , ⋯ , R e R_{\lfloor \frac{e+s}{2} \rfloor + 1}, R_{\lfloor \frac{e+s}{2} \rfloor + 2}, \cdots, R_e R ⌊ 2 e + s ⌋ + 1 , R ⌊ 2 e + s ⌋ + 2 , ⋯ , R e
二叉判定树的简易构造方式:
画出小于节点总数的最大满二叉树;
将剩余节点从最右侧开始依次排布在二叉树的底层,先放在作为右子节点的终端节点的右子树上,再放在作为左子节点的终端节点的右子树上,接着按照相同顺序放在终端节点的左子树上;
将给定序列依次按照中序遍历顺序填入各个节点。
平均查找长度(ASL): 已知二叉判定树,则查找成功的 ASL 的计算方式为
A S L s u c c = ∑ i = 1 n p i ⋅ l e v e l ( k i ) ASL_{succ} = \sum_{i = 1}^n p_i \cdot level(k_i)
A S L s u cc = i = 1 ∑ n p i ⋅ l e v e l ( k i )
其中 k i k_i k i l e v e l ( k i ) level(k_i) l e v e l ( k i ) p i p_i p i
A S L u n s u c c = ∑ 0 n q i ⋅ ( l e v e l ( u i ) − 1 ) ASL_{unsucc} = \sum_0^n q_i \cdot (level(u_i) - 1)
A S L u n s u cc = 0 ∑ n q i ⋅ ( l e v e l ( u i ) − 1 )
其中 u i u_i u i q i q_i q i
例:画出对长度为 12 的有序表进行二分查找的判定树,并求其等概率时的平均查找长度。
查找成功的 ASL 为
A S L s u c c = 1 + 2 × 2 + 3 × 4 + 4 × 5 12 = 37 12 ASL_{succ} = \frac{1 + 2 \times 2 + 3 \times 4 + 4 \times 5}{12} = \frac{37}{12}
A S L s u cc = 12 1 + 2 × 2 + 3 × 4 + 4 × 5 = 12 37
查找失败的 ASL 为
A S L u n s u c c = 3 × 3 + 4 × 10 13 = 49 13 ASL_{unsucc} = \frac{3 \times 3 + 4 \times 10}{13} = \frac{49}{13}
A S L u n s u cc = 13 3 × 3 + 4 × 10 = 13 49
算法分析:
最好时间复杂度为 O ( 1 ) O(1) O ( 1 )
最坏和期望时间复杂度为 O ( log 2 n ) O(\log_2 n) O ( log 2 n )
一致二分查找
基本思路: 将二分查找的指针数量由三个减少为两个(即 i 和 m),使得层 l l l l − 1 l - 1 l − 1 l l l δ \delta δ
一致二分查找算法的演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 template <typename T>std::size_t ubinarySearch (const std::vector<T>& src, const T& key) { auto i = static_cast <std::size_t >(std::ceil (src.size () / 2.0 )); auto m = static_cast <std::size_t >(src.size () / 2 ); while (key != src[i]) { if (key < src[i]) { if (m == 0 ) { return -1 ; } else { i -= static_cast <std::size_t >(std::ceil (m / 2.0 )); m /= 2 ; } } if (key > src[i]) { if (m == 0 ) { return -1 ; } else { i += static_cast <std::size_t >(std::ceil (m / 2.0 )); m /= 2 ; } } } return i; }
改进方法: 在运行期间,不去计算 i 和 m 的值,而是使用一张辅助表来存储 δ \delta δ
δ [ j ] = ⌊ n + 2 j − 1 2 j ⌋ , 0 ≤ j ≤ ⌊ l o g 2 n ⌋ + 1 \delta[j] = \left\lfloor \frac{n + 2^{j - 1}}{2^j} \right\rfloor, \quad 0 \leq j \leq \lfloor log_2 n \rfloor + 1
δ [ j ] = ⌊ 2 j n + 2 j − 1 ⌋ , 0 ≤ j ≤ ⌊ l o g 2 n ⌋ + 1
改进后的算法演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 void calcDelta (std::vector<std::size_t >& delta) auto n = delta.size (); auto k = static_cast <std::size_t >(std::log (n) / std::log (2 )) + 1 ; std::size_t s = 1 ; for (std::size_t j = 0 ; j <= k; ++j) { delta[j] = (n + s) / (s * 2 ); s *= 2 ; } } template <typename T>std::size_t cbinarySearch (const std::vector<T>& src, const T& key, const std::vector<std::size_t >& delta) auto i = delta[0 ]; std::size_t j = 1 ; while (key != src[i]) { if (key < src[i]) { if (delta[j] == 0 ) { return -1 ; } else { i -= delta[j]; ++j; } } if (key > src[i]) { if (delta[j] == 0 ) { return -1 ; } else { i += delta[j]; ++j; } } } return i; }
算法分析:
对于成功的查找,平均比较次数和二分查找算法相同。
对于不成功的查找,比较次数为 ⌊ log 2 n ⌋ + 1 \lfloor \log_2 n \rfloor + 1 ⌊ log 2 n ⌋ + 1
该算法中的算术运算仅包含加减法,并且使用辅助表来代替 m 的计算,从而明显提高了速度,因此时间花费不足二分查找算法的二分之一。
斐波那契查找
斐波那契(Fibonacci)序列:
0 , 1 , 1 , 2 , 3 , 5 , 8 , 13 , 21 , 34 , ⋯ f 0 = 0 , f 1 = 1 , f i = f i − 1 + f i − 2 ( i ≥ 2 ) 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, \cdots\\
f_0 = 0, \quad f_1 = 1, \quad f_i = f_{i - 1} + f_{i - 2} \ (i \geq 2) 0 , 1 , 1 , 2 , 3 , 5 , 8 , 13 , 21 , 34 , ⋯ f 0 = 0 , f 1 = 1 , f i = f i − 1 + f i − 2 ( i ≥ 2 )
以斐波那契序列的分划代替二分查找的均匀分划,这种分划方式接近黄金分割 。
基本思路: 假定表中元素的个数比某个斐波那契数小 1 1 1 n = f k − 1 n = f_k − 1 n = f k − 1 K K K K f k − 1 − 1 K_{f_{k - 1} - 1} K f k − 1 − 1
K < K f k − 1 − 1 K < K_{f_{k - 1} - 1} K < K f k − 1 − 1 0 0 0 f k − 1 − 2 f_{k - 1} − 2 f k − 1 − 2 1 1 1 K > K f k − 1 − 1 K > K_{f_{k - 1} - 1} K > K f k − 1 − 1 f k − 1 f_{k - 1} f k − 1 f k − 2 f_k − 2 f k − 2 f k − 2 − 1 f_{k - 2} - 1 f k − 2 − 1 1 1 1 K = K f k − 1 − 1 K = K_{f_{k - 1} - 1} K = K f k − 1 − 1 f k − 1 − 1 f_{k - 1} - 1 f k − 1 − 1
重复上述过程,直至找到所查记录或确定该记录不在表中。
斐波那契查找算法的演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 template <typename T>std::size_t fibonacciSearch (const std::vector<T>& src, const T& key) { std::size_t left = 0 ; std::size_t right = src.size () - 1 ; std::size_t k = 0 ; auto f = fibonacci (src.size ()); while (static_cast <int >(right) > static_cast <int >(f[k]) - 1 ) ++k; std::vector<T> temp (src) ; temp.resize (f[k] - 1 ); for (auto i = src.size (); i < f[k] - 1 ; ++i) temp[i] = src.back (); while (left <= right) { auto mid = left + f[k - 1 ] - 1 ; if (key < temp[mid]) { right = mid - 1 ; --k; } else if (key > temp[mid]) { left = mid + 1 ; k -= 2 ; } else { if (mid <= right) return mid; else return right; } } return -1 ; }
斐波那契树: k k k T k T_k T k
当 k ≤ 1 k \leq 1 k ≤ 1 T k T_k T k
当 k ≥ 2 k \geq 2 k ≥ 2 T k T_k T k R f k − 1 R_{f_k - 1} R f k − 1 k − 1 k - 1 k − 1 R f k − 1 − 1 R_{f_{k - 1} - 1} R f k − 1 − 1 k − 2 k - 2 k − 2 f k f_k f k R f k − 2 + f k − 1 R_{f_{k - 2} + f_k - 1} R f k − 2 + f k − 1
6 阶斐波那契树如下图所示:
算法分析:
平均时间复杂度为 O ( log 2 n ) O(\log_2 n) O ( log 2 n )
一致二分查找的平均运行时间大约是斐波那契查找的 1.2 倍,二分查找的平均运行时间大约是斐波那契查找的 2.5 倍。在最坏的情况下,斐波那契查找的运行8.6 log 2 n 8.6 \log_2 n 8.6 log 2 n
插值查找
基本思想: 假定有序表中记录的关键词 K 0 < K 1 < ⋯ < K n − 1 K_0 < K_1 < \cdots < K_{n - 1} K 0 < K 1 < ⋯ < K n − 1 [ K 0 , K n ) [K0, K_n) [ K 0 , K n ) K K K K 0 ≤ K < K n K_0 \leq K < K_n K 0 ≤ K < K n K K K n K − K 0 K n − 1 − K 0 n\dfrac{K - K_0}{K_{n - 1} - K_0} n K n − 1 − K 0 K − K 0 K K K K s K_s K s K e K_e K e s s s e e e
插值查找算法的演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 template <typename T>std::size_t interpolationSearch (const std::vector<T>& src, const T& key) { std::size_t left = 0 ; std::size_t right = src.size () - 1 ; if (key < src.front () || key > src.back ()) return -1 ; if (key == src.back ()) return src.size () - 1 ; while (left <= right) { auto mid = left + (right - left) * (key - src[left]) / (src[right] - key); if (src[mid] < key) left = mid + 1 ; else if (src[mid] > key) right = mid - 1 ; else return mid; } return -1 ; }
算法分析:
最好时间复杂度为 O ( 1 ) O(1) O ( 1 )
最坏时间复杂度为 O ( n ) O(n) O ( n )
平均时间复杂度为 O ( log 2 ( log 2 n ) ) O(\log_2(\log_2 n)) O ( log 2 ( log 2 n ))
二叉搜索树(BST)
定义: 对于二叉搜索树中的任一节点 P P P P P P P P P 中序 下按其关键词由小到大排序,并且关键词各不相同。
二叉搜索树的查找操作:
若树非空,则将目标关键词与根节点的关键词进行比较;若相等,则查找成功;若小于根节点,则在左子树上查找,否则在右子树上查找。演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 template <typename T>BinaryTreeNode<T>* findBstNode (const BinaryTreeNode<T>* pRoot, const T& key) { auto pNode = pRoot; while (pRoot != nullptr && pNode->data != key) { if (key < pNode->data) pNode = pNode->pLeft; else pNode = pNode->pRight; } return pNode; }
查找效率取决于树的高度,随机情况下,算法的时间复杂度为 O ( log 2 n ) O(\log_2 n) O ( log 2 n ) O ( n ) O(n) O ( n )
二叉搜索树的插入操作:
若原二叉搜索树为空,则直接插入节点;否则,若待插入关键词小于根节点的关键词,则插入到左子树;若待插入关键词大于根节点的关键词,则插入到右子树。演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 template <typename T>BinaryTreeNode<T>* insertBstNode (BinaryTreeNode<T>* pRoot, const T& value) { if (pRoot == nullptr ) { pRoot = new BinaryTreeNode <T>(); pRoot->data = value; return pRoot; } auto pNode = pRoot; auto pParent = pRoot; while (pNode != nullptr ) { pParent = pNode; if (pNode->data > value) pNode = pNode->pLeft; else if (pNode->data < value) pNode = pNode->pRight; else return pRoot; } auto pNew = new BinaryTreeNode <T>(); pNew->data = value; if (value < pParent->data) pParent->pLeft = pNew; else pParent->pRight = pNew; return pRoot; }
按照给定序列构造二叉搜索树:
1 2 3 4 5 6 7 8 9 10 template <typename T>BinaryTreeNode<T>* createBstNode (const std::vector<T>& src) { BinaryTreeNode<T>* pRoot = nullptr ; std::size_t i = 0 ; while (i < src.size ()) { insertBstNode (pRoot, src[i]); ++i } return pRoot; }
二叉搜索树的删除操作:
先搜索找到目标节点,有下列几种情况:
若被删除节点 P 是叶子节点,则直接删除,不会破坏二叉搜索树的性质;
若节点 P 只有一棵左子树或右子树,则让 P 的子树成为其父节点的子树,替代 P 的位置;
若节点 P 有左、右两棵子树,则令 P 的直接后继(或直接前驱)替代 P,然后从二叉排序树中删去这个直接后继(或直接前驱),这样就转换为了第一或第二种情况。
演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 template <typename T>BinaryTreeNode<T>* removeBstNode (BinaryTreeNode<T>* pRoot, const T& value) { BinaryTreeNode<T>* pParent = nullptr ; auto pNode = pRoot; while (pNode != nullptr ) { if (pNode->data < value) { pParent = pNode; pNode = pNode->pRight; } else if (pNode->data > value) { pParent = pNode; pNode = pNode->pLeft; } else { if (pNode->pLeft == nullptr ) { if (pNode == pRoot) { pRoot = pNode->pRight; } else { if (pNode == pParent->pLeft) { pParent->pLeft = pNode->pRight; } else { pParent->pRight = pNode->pRight; } } delete pNode; pNode = nullptr ; } else if (pNode->pRight == nullptr ) { if (pNode == pRoot) { pRoot = pNode->pLeft; } else { if (pNode == pParent->pLeft) { pParent->pLeft = pNode->pLeft; } else { pParent->pRight = pNode->pLeft; } } delete pNode; pNode = nullptr ; } else { auto pRepParent = pNode; auto pReplace = pNode->pRight; while (pReplace->pLeft != nullptr ) { pRepParent = pReplace; pReplace = pReplace->pLeft; } std::swap (pNode->data, pReplace->data); if (pRepParent->pLeft == pReplace) { pRepParent->pLeft = pReplace->pRight; } else { pRepParent->pRight = pReplace->pRight; } delete pReplace; } return pRoot; } } return pRoot; }
平衡二叉树(AVL)
定义: 平衡二叉树由单一的外节点组成,或由根节点 T T T T l T_l T l T r T_r T r
∣ h ( T l ) − h ( T r ) ∣ ≤ 1 |h(T_l) - h(T_r)| \leq 1 ∣ h ( T l ) − h ( T r ) ∣ ≤ 1 h ( T ) h(T) h ( T ) T T T T l T_l T l T r T_r T r
为节点添加一个新的高度字段,并以此计算平衡因子 ,其定义为节点的左子树高和右子树高的差,即 h r − h l h_r - h_l h r − h l
斐波那契树是一棵平衡二叉树,且每个结点的平衡因子为 −1。
平衡二叉树节点的结构及计算平衡因子的方法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 template <typename T>struct AvlNode { T key; int height{ 0 }; AvlNode* pLeft{ nullptr }; AvlNode* pRight{ nullptr }; }; template <typename T>class AvlTree {public : AvlNode<T>* pRoot{ nullptr }; AvlTree (); ~AvlTree (); ... private : int getHeight (AvlNode<T>* pNode) if (pNode == nullptr ) return -1 ; return pNode->height; } int getBalance (AvlNode<T>* pNode) return getHeight (pNode->pLeft) - getHeight (pNode->pRight); } ... };
平衡树二叉树的调整:
对平衡二叉树执行插入操作会使平衡性遭到破坏,此时要进行调整以再次保持平衡。对最小不平衡树 A 的调整方法分下列情况:
LL 型:在 A 的左子节点的左子树中插入新节点导致不平衡;
RR 型:在 A 的右子节点的右子树中插入新节点导致不平衡;
LR 型:在 A 的左子节点的右子树中插入新节点导致不平衡;
RL 型:在 A 的右子节点的左子树中插入新节点导致不平衡。
LL 型(右单旋转): 将 A 的左子节点 B 向右上旋转代替 A 成为根节点,将 A 节点向右下旋转成为 B 的右子树的根节点,而 B 的原右子树则作为 A 节点的左子树。如下图所示:
RR 型(左单旋转): 将 A 的右子节点 B 向左上旋转代替 A 成为根节点,将 A 节点向左下旋转成为 B 的左子树的根节点,而 B 的原左子树则作为 A 节点的右子树。如下图所示:
LR 型(先左后右双旋转): 先将 A 节点的左子节点 B 的右子树的根节点 C 向左上旋转到 B 节点的位置,然后再把该 C 节点向右上旋转到 A 节点的位置。如下图所示:
RL 型(先右后左双旋转): 先将 A 节点的右子节点 B 的左子树的根节点 C 向右上旋转到 B 节点的位置,然后再把该 C 节点向左上旋转到 A 节点的位置。如下图所示:
具体代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 template <typename T>class AvlTree {public : ... void insert (const T& key) pRoot = insert (pRoot, key); } private : ... AvlNode<T>* leftRotate (AvlNode<T>* pNode) { auto pRoot = pNode->pRight; auto p = pRoot->pLeft; pRoot->pLeft = pNode; pNode->pRight = p; pNode->height = 1 + std::max (getHeight (pNode->pLeft), getHeight (pNode->pRight)); pRoot->height = 1 + std::max (getHeight (pRoot->pLeft), getHeight (pRoot->pRight)); return pRoot; } AvlNode<T>* rightRotate (AvlNode<T>* pNode) { auto pRoot = pNode->pLeft; auto p = pRoot->pRight; pRoot->pRight = pNode; pNode->pLeft = p; pNode->height = 1 + std::max (getHeight (pNode->pLeft), getHeight (pNode->pRight)); pRoot->height = 1 + std::max (getHeight (pRoot->pLeft), getHeight (pRoot->pRight)); return pRoot; } AvlNode<T>* adjust (AvlNode<T>* pNode) { auto balance = getBalance (pNode); if (balance > 1 ) { if (getBalance (pNode->pLeft) >= 0 ) { return rightRotate (pNode); } if (getBalance (pNode->pLeft) < 0 ) { pNode->pLeft = leftRotate (pNode->pLeft); return rightRotate (pNode); } } if (balance < -1 ) { if (getBalance (pNode->pRight) <= 0 ) { return leftRotate (pNode); } if (getBalance (pNode->pRight) > 0 ) { pNode->pRight = rightRotate (pNode->pRight); return leftRotate (pNode); } } return pNode; } AvlNode<T>* insert (AvlNode<T>* pNode, const T& key) { if (pNode == nullptr ) { pNode = new Node (); pNode->key = key; return pNode; } if (key < pNode->key) { pNode->pLeft = insert (pNode->pLeft, key); } else if (key > pNode->key) { pNode->pRight = insert (pNode->pRight, key); } else { return pNode; } pNode->height = 1 + std::max (getHeight (pNode->pLeft), getHeight (pNode->pRight)); return adjust (pNode); } };
平衡树二叉树的删除操作:
删除节点(方法同二叉搜索树);
若找不到最小不平衡二叉树,则操作完成;
找最小不平衡二叉树中,最高的子节点和孙子节点;
根据孙子节点的位置,调整平衡;
如果不平衡则向上传导,回到步骤 2。
平衡二叉树删除操作的时间复杂度为 O ( log 2 n ) O(\log_2 n) O ( log 2 n )
具体代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 template <typename T>class AvlTree {public : ... void remove (const T& key) pRoot = remove (pRoot, key); } private : ... AvlNode<T>* remove (AvlNode<T>* pNode, const T& key) { if (pNode == nullptr ) { return nullptr ; } if (key < pNode->key) { pNode->pLeft = remove (pNode->pLeft, key); } else if (key > pNode->key) { pNode->pRight = remove (pNode->pRight, key); } else { if (pNode->pLeft == nullptr ) { auto p = pNode->pRight; delete pNode; return p; } if (pNode->pRight == nullptr ) { auto p = pNode->pLeft; delete pNode; return p; } auto pReplace = pNode->pRight; while (pReplace->pLeft != nullptr ) { pReplace = pReplace->pLeft; } std::swap (pNode->key, pReplace->key); pNode->pRight = remove (pNode->pRight, pReplace->key); } pNode->height = 1 + std::max (getHeight (pNode->pLeft), getHeight (pNode->pRight)); return adjust (pNode); } };
B树及其变体
定义: B树又称多路平衡查找树 ,B树的所有节点的最大子节点个数称为B树的阶,一棵 m m m
树中每个节点最多有 m m m m − 1 m - 1 m − 1
除根节点外的所有非叶子节至少有 ⌈ m 2 ⌉ \left\lceil \dfrac{m}{2} \right\rceil ⌈ 2 m ⌉ ⌈ m 2 ⌉ − 1 \left\lceil \dfrac{m}{2} \right\rceil - 1 ⌈ 2 m ⌉ − 1
如果根节点不是叶子节点,则至少有两棵子树;
所有的叶子结点都出现在同一层上,并且都不带有信息。
一棵 5 阶B树如下图所示:
B树每个非叶子节点的结构如下:
其中 K i ( i = 1 , 2 , ⋯ , n ) K_i\ (i = 1, 2, \cdots, n) K i ( i = 1 , 2 , ⋯ , n ) K 1 < K 2 < ⋯ < K n K_1 < K_2 < \cdots < K_n K 1 < K 2 < ⋯ < K n P i ( i = 0 , 1 , ⋯ , n ) P_i\ (i = 0, 1, \cdots, n) P i ( i = 0 , 1 , ⋯ , n ) P i − 1 P_{i - 1} P i − 1 K i K_i K i P i P_i P i K i K_i K i n ( ⌈ m 2 ⌉ − 1 ≤ n ≤ m − 1 ) n\ (\left\lceil \dfrac{m}{2} \right\rceil - 1 \leq n \leq m - 1) n ( ⌈ 2 m ⌉ − 1 ≤ n ≤ m − 1 )
B树的高度(不包括叶子节点): 对于有 n n n m m m log m n \log_m n log m n
h ≤ log ⌈ m 2 ⌉ ( n + 1 2 ) + 1 h \leq \log_{\left\lceil \frac{m}{2} \right\rceil} \left( \frac{n + 1}{2} \right) + 1
h ≤ log ⌈ 2 m ⌉ ( 2 n + 1 ) + 1
B树的查找操作:
当节点的关键词个数 n n n n n n K K K K K K P P P
若 K i < K < K i + 1 ( 1 ≤ i < n ) K_i < K < K_{i + 1}\ (1 \leq i < n) K i < K < K i + 1 ( 1 ≤ i < n ) P i P_i P i
若 K > K n K > K_n K > K n P n P_n P n
若 K < K 1 K < K_1 K < K 1 P 0 P_0 P 0
如果指向下一个要查找的节点的指针 P i P_i P i
B树的插入操作:
通过查找确定插入位置(一定是终端节点)。
若插入后节点关键词个数未超过上限,则无需做其它处理。
若插入后关键词个数超过上限,则需要将当前节点的中间元素放到父节点中,当前节点分裂为两个部分;该操作会导致父节点的关键个数 + 1,若父节点关键词个数也超过乐上限,则需要继续向上分裂;根节点的分裂会导致B树高度 + 1。
B树的删除操作:
非终端结点的删除:使用直接前驱或者直接后继来代替被删除的关键词,转换为对 “终端结点” 的删除。
直接前驱:当前关键词左边指针所指子树中 “最右下” 的元素。
B+树: B+树是为了适应文件系统的需要而产生的一种B树的变体,一棵 m m m
每个分支节点最多有 m m m
非叶子节点至少有两棵子树,其它每个分支节点至少有 ⌈ m 2 ⌉ \left\lceil \dfrac{m}{2} \right\rceil ⌈ 2 m ⌉
节点的子树个数与关键词个数相等;
所有叶子节点包含全部关键词及指向响应记录的指针,叶子节点中将关键词按大小顺序排列,并且相邻叶子节点按大小顺序相互链接起来。
一棵 4 阶B+树如下图所示:
在B+树上进行随机查找、插入和删除操作的过程基本上与B树类似,只是在查找时,如果非叶子节点上的关键词等于给定值,并不终止,而是需要继续向下走到叶子节点以获取记录。因此,在B+树中,不管查找成功与否,每次查找都是走了一条从根节点到叶子节点的路径。
B+树比B树更适合作索引的原因:
磁盘读写代价更低:B+树内部节点并没有指向关键词具体记录信息的指针,因此其内部节点相对B树更小。
查询效率更加稳定。
方便扫库:B树必须用中序遍历的方法按序扫库,而B+树直接从叶子节点顺序扫描一遍就可以。
红黑树
红黑树(Red-Black Tree, RBT) 是一种自平衡的二叉搜索树,是一种高效的查找数据结构,它和 4 阶 B树(即 2-3-4树)具有等价性。一棵有 n 个节点的红黑树的高度,最多是 2 log ( n + 1 ) 2\log(n + 1) 2 log ( n + 1 ) O ( log ( n ) ) O(\log(n)) O ( log ( n ))
红黑树具有以下基本性质:
节点是红色或黑色;
根节点是黑色;
叶子节点(外部节点、空节点)都是黑色;
红色节点的子节点都是黑色;
从任一节点到叶子节点的所有路径都包含相同数目的黑色节点。
红色节点的父节点都是黑色节点;从根节点到叶子节点的所有路径上不能有 2 个连续的红色节点。
红黑树节点的结构如下:
1 2 3 4 5 6 7 8 template <typename T>struct RBTNode { T key; bool black{ false }; RBTNode* pLeft{ nullptr }; RBTNode* pRight{ nullptr }; RBTNode* pParent{ nullptr }; };
红黑树的插入操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 template <typename T>class RBTree {public : RBTNode<T>* pRoot{ nullptr }; void insert (const T& key) if (pRoot == nullptr ) { pRoot = new RBTNode <T>(); pRoot->key = key; pRoot->black = true ; return ; } RBTNode<T>* pNode = pRoot; RBTNode<T>* pParent = nullptr ; while (pNode != nullptr ) { pParent = pNode; if (pNode->key > key) pNode = pNode->pLeft; else if (pNode->key < key) pNode = pNode->pRight; else return ; } auto pNew = new RBTNode <T>(); pNew->key = key; pNew->pParent = pParent; if (key < pParent->key) pParent->pLeft = pNew; else pParent->pRight = pNew; insertFixUp (pNew); } ... private : void leftRotate (RBTNode<T>* px) auto py = px->pRight; px->pRight = py->pLeft; if (py->pLeft != nullptr ) { py->pLeft->pParent = px; } py->pParent = px->pParent; if (px->pParent == nullptr ) { pRoot = py; } else { if (px->pParent->pLeft == px) px->pParent->pLeft = py; else px->pParent->pRight = py; } py->pLeft = px; px->pParent = py; } void rightRotate (RBTNode<T>* py) auto px = py->pLeft; py->pLeft = px->pRight; if (px->pRight != nullptr ) { px->pRight->pParent = py; } px->pParent = py->pParent; if (py->pParent == nullptr ) { pRoot = px; } else { if (py == py->pParent->pRight) py->pParent->pRight = px; else py->pParent->pLeft = px; } px->pRight = py; py->pParent = px; } void insertFixUp (RBTNode<T>* pNode) RBTNode<T>* pParent = nullptr ; RBTNode<T>* pGParent = nullptr ; while ((pParent = pNode->pParent) && !pParent->black) { pGParent = pParent->pParent; if (pParent == pGParent->pLeft) { auto pUncle = pGParent->pRight; if (pUncle != nullptr && !pUncle->black) { pUncle->black = true ; pParent->black = true ; pGParent->black = false ; pNode = pGParent; continue ; } if (pParent->pRight == pNode) { leftRotate (pParent); std::swap (pNode, pParent); continue ; } pParent->black = true ; pGParent->black = false ; rightRotate (pGParent); } else { auto pUncle = pGParent->pLeft; if (pUncle != nullptr && !pUncle->black) { pUncle->black = true ; pParent->black = true ; pGParent->black = false ; pNode = pGParent; continue ; } if (pParent->pLeft == pNode) { rightRotate (pParent); std::swap (pNode, pParent); continue ; } pParent->black = true ; pGParent->black = false ; leftRotate (pGParent); } } pRoot->black = true ; } ... };
红黑树的删除操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 template <typename T>class RBTree {public : ... void remove (const T& key) RBTNode<T>* pNode = pRoot; RBTNode<T>* pParent = nullptr ; while (pNode != nullptr ) { if (pNode->key < key) { pParent = pNode; pNode = pNode->pRight; } else if (pNode->key > key) { pParent = pNode; pNode = pNode->pLeft; } else { if (pNode->pLeft != nullptr && pNode->pRight != nullptr ) { auto pRepParent = pNode; auto pReplace = pNode->pRight; while (pReplace->pLeft != nullptr ) { pRepParent = pReplace; pReplace = pReplace->pLeft; } std::swap (pNode->key, pReplace->key); RBTNode<T>* pChild = pReplace->pRight; if (pRepParent->pLeft == pReplace) { pRepParent->pLeft = pChild; } else { pRepParent->pRight = pChild; } if (pChild != nullptr ) pChild->pParent = pRepParent; if (pReplace->black) removeFixUp (pChild, pRepParent); delete pReplace; return ; } RBTNode<T>* pChild = nullptr ; if (pNode->pLeft != nullptr ) pChild = pNode->pLeft; else pChild = pNode->pRight; if (pChild != nullptr ) pChild->pParent = pParent; if (pParent != nullptr ) { if (pParent->pLeft == pNode) pParent->pLeft = pChild; else pParent->pRight = pChild; } else pRoot = pChild; if (pNode->black) removeFixUp (pChild, pParent); delete pNode; return ; } } } private : ... void removeFixUp (RBTNode<T>* pNode, RBTNode<T>* pParent) RBTNode<T>* pOther = nullptr ; while ((pNode == nullptr || pNode->black) && pNode != pRoot) { if (pParent->pLeft == pNode) { pOther = pParent->pRight; if (!pOther->black) { pOther->black = true ; pParent->black = false ; leftRotate (pParent); pOther = pParent->pRight; } if ((pOther->pLeft == nullptr || pOther->pLeft->black) && (pOther->pRight == nullptr || pOther->pRight->black)) { pOther->black = false ; pNode = pParent; pParent = pNode->pParent; } else { if (pOther->pRight == nullptr || pOther->pRight->black) { pOther->pLeft->black = true ; pOther->black = false ; rightRotate (pOther); pOther = pParent->pRight; } pOther->black = pParent->black; pParent->black = true ; pOther->pRight->black = true ; leftRotate (pParent); pNode = pRoot; break ; } } else { pOther = pParent->pLeft; if (!pOther->black) { pOther->black = true ; pParent->black = false ; rightRotate (pParent); pOther = pParent->pLeft; } if ((pOther->pLeft == nullptr || pOther->pLeft->black) && (pOther->pRight == nullptr || pOther->pRight->black)) { pOther->black = false ; pNode = pParent; pParent = pNode->pParent; } else { if (pOther->pLeft == nullptr || pOther->pLeft->black) { pOther->pRight->black = true ; pOther->black = false ; leftRotate (pOther); pOther = pParent->pLeft; } pOther->black = pParent->black; pParent->black = true ; pOther->pLeft->black = true ; rightRotate (pParent); pNode = pRoot; break ; } } } if (pNode != nullptr ) pNode->black = true ; } };
散列查找
散列查找是一种几乎不用对表进行搜索的查找算法。以给定变元 K K K 散列函数(哈希函数) h ( K ) h(K) h ( K ) K K K K K K
根据给定的散列函数和处理冲突的方法,将一组关键词映射到一个有限的连续地址空间上,并以关键词在地址集上的 “像” 作为该记录在表中的存储位置,这种表称为散列表(或哈希表,Hash table) ,这种映射过程称为散列 ,所得到的存储位置称为散列地址 。
装填因子: 装填因子 α \alpha α
散列函数的取法: (应满足便于快速计算 和极少出现冲突 两个条件)
直接定址法:h ( K ) = K h(K) = K h ( K ) = K H ( K ) = a ∗ K + b H(K) = a * K + b H ( K ) = a ∗ K + b a , b a, b a , b
抽取法:从关键词对应的二进制串中抽取几个分散的代码,然后合并这几个代码形成地址。
抽取法虽然简单,但容易出现 “群集 ” 现象,这是因为散列函数值不是依赖整个二进制串,而仅依赖二进制串的部分代码。一般来说,选取散列函数时,其函数值应依赖关键词对应的二进制串中的每一位。
拉链法: 将所有 “同义词” 存储在一个链表中。演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 template <typename T>class HashTable {public : HashTable (size_t size) : table (size) {} void insert (const T& key) auto index = hash (key); for (const auto & i : table[index]) { if (i == key) { return ; } } table[index].emplace_back (key); } std::optional<T> search (const T& key) { auto index = hash (key); for (const auto & i : table[index]) { if (i == key) { return key; } } return {}; } void remove (const T& key) int index = hash (key); for (auto i = table[index].begin (); i != table[index].end (); ++i) { if (*i == key) { table[index].erase (i); return ; } } } private : std::vector<std::list<T>> table; std::size_t hash (const T& key) { return key % table.size (); } };
开放定址法: 一旦产生了冲突,就按某种规则去寻找另一空地址,有线性探测法,平方探测法和伪随机探测法等。其数学递推公式为
h i = ( h ( K ) + d i ) m o d m h_i = (h(K) + d_i) \ \mathrm{mod} \ m
h i = ( h ( K ) + d i ) mod m
其中 m m m d i d_i d i i = 0 , 1 , 2 , ⋯ , k ( k ≤ m − 1 ) i = 0, 1, 2, \cdots, k\ (k \leq m - 1) i = 0 , 1 , 2 , ⋯ , k ( k ≤ m − 1 ) i i i
(1)线性探测法: 发生冲突时,每次向后探测相邻的下一单元是否为空,增量序列为 d i = 0 , 1 , 2 , ⋯ , m − 1 d_i = 0, 1, 2, \cdots, m - 1 d i = 0 , 1 , 2 , ⋯ , m − 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 template <typename T>class HashTable {public : HashTable (size_t size) : table (size) {} void insert (const T& key) auto index = key % table.size (); while (table[index].has_value ()) { index = (index + 1 ) % table.size (); } table[index] = key; } std::optional<size_t > search (const T& key) { auto index = key % table.size (); while (table[index].has_value () && table[index].value () != key) { index = (index + 1 ) % table.size (); } if (table[index].has_value ()) { return index; } else { return {}; } } void remove (const T& key) auto index = search (key); if (index.has_value ()) { table[index.value ()].reset (); } } private : std::vector<std::optional<T>> table; };
线性探测法很容易造成同义词、非同义词的堆积现象,严重影响查找效率。
(2)平方探测法: 又称二次探测法,增量序列为 d i = 0 2 , 1 2 , − 1 2 , 2 2 , − 2 2 , ⋯ , k 2 , − k 2 ( k ≤ m 2 ) d_i = 0^2, 1^2, -1^2, 2^2, -2^2,\cdots, k^2, -k^2\ (k \leq \dfrac{m}{2}) d i = 0 2 , 1 2 , − 1 2 , 2 2 , − 2 2 , ⋯ , k 2 , − k 2 ( k ≤ 2 m )
(3)伪随机探测法: 建立一个伪随机发生器,当发生冲突时,就利用伪随机数发生器计算出下一个探查的位置,d i d_i d i
双重散列: 寻找空地址时,所前进的步长不是固定的,而与 K K K δ ( K ) \delta(K) δ ( K ) δ \delta δ